【小技巧】跳过隐藏行或列,读取excel内容 收藏
收藏
评论
收藏【小技巧】跳过隐藏行或列,读取excel内容
阿
2024-06-30 18:53·浏览量:2180
阿
阿深
一、问题场景:
在进行excel自动化时,有时我们需要跳过隐藏行或者隐藏列,只读取excel显示的内容。
例如下图👇,18~35行是隐藏行,C~E列是隐藏列,而我们的需求是能够跳过这部分隐藏的数据,只读取excel显示的内容。
但是如果直接使用影刀指令【读取excel内容】或【循环excel内容】,我们无法实现这个操作。

二、解决方案:
而针对于这个问题场景,我们自然而然地想到了借助python编码版来解决。
其中,又可以有两种不同的思路:
- 直接跳过隐藏行或列,读取excel表内容,输出二维列表。(代替【读取excel内容】的作用)
- 判断当前行或列是不是隐藏的,继而再判断是否需要跳过。(配合【excel内容】进行使用)
最终,整合后的代码如下:
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import os
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
import datetime
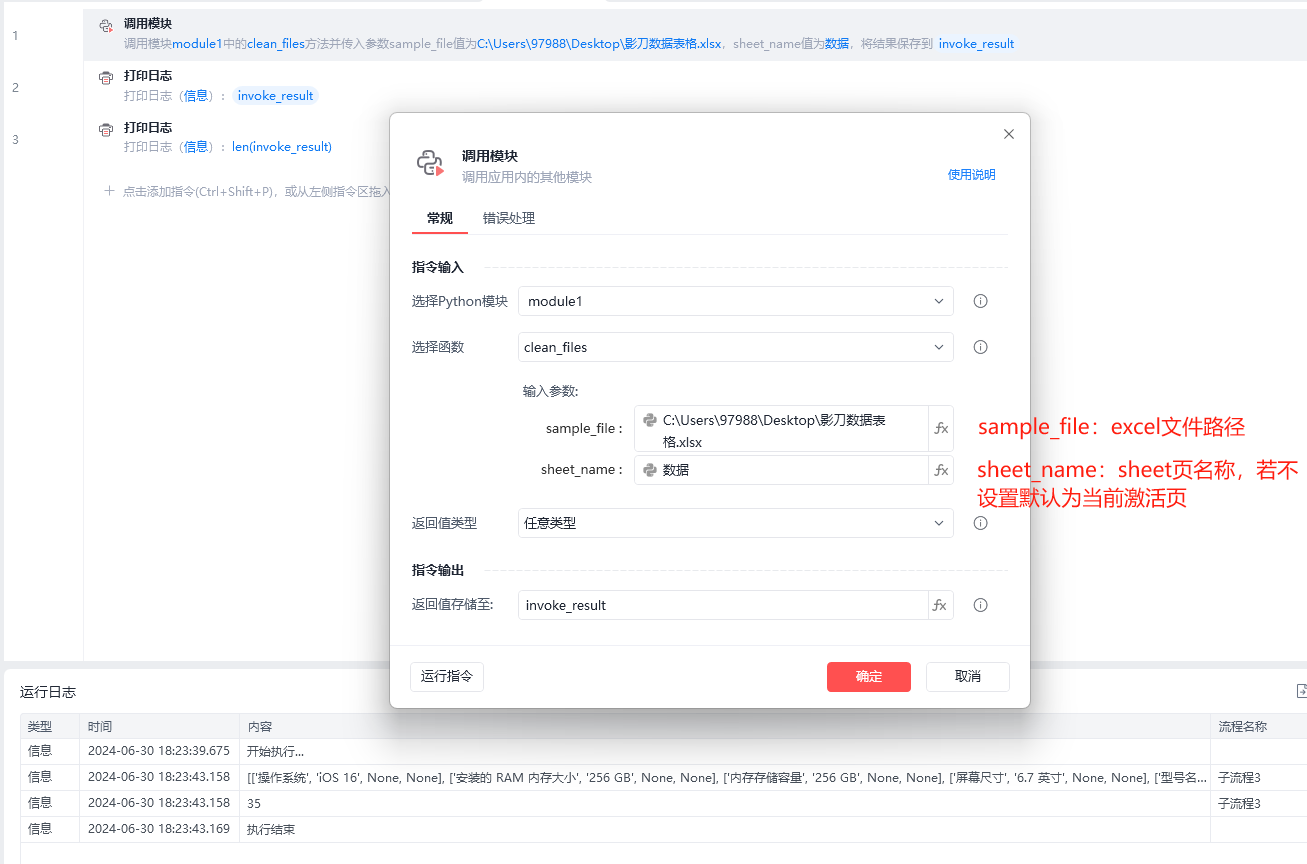
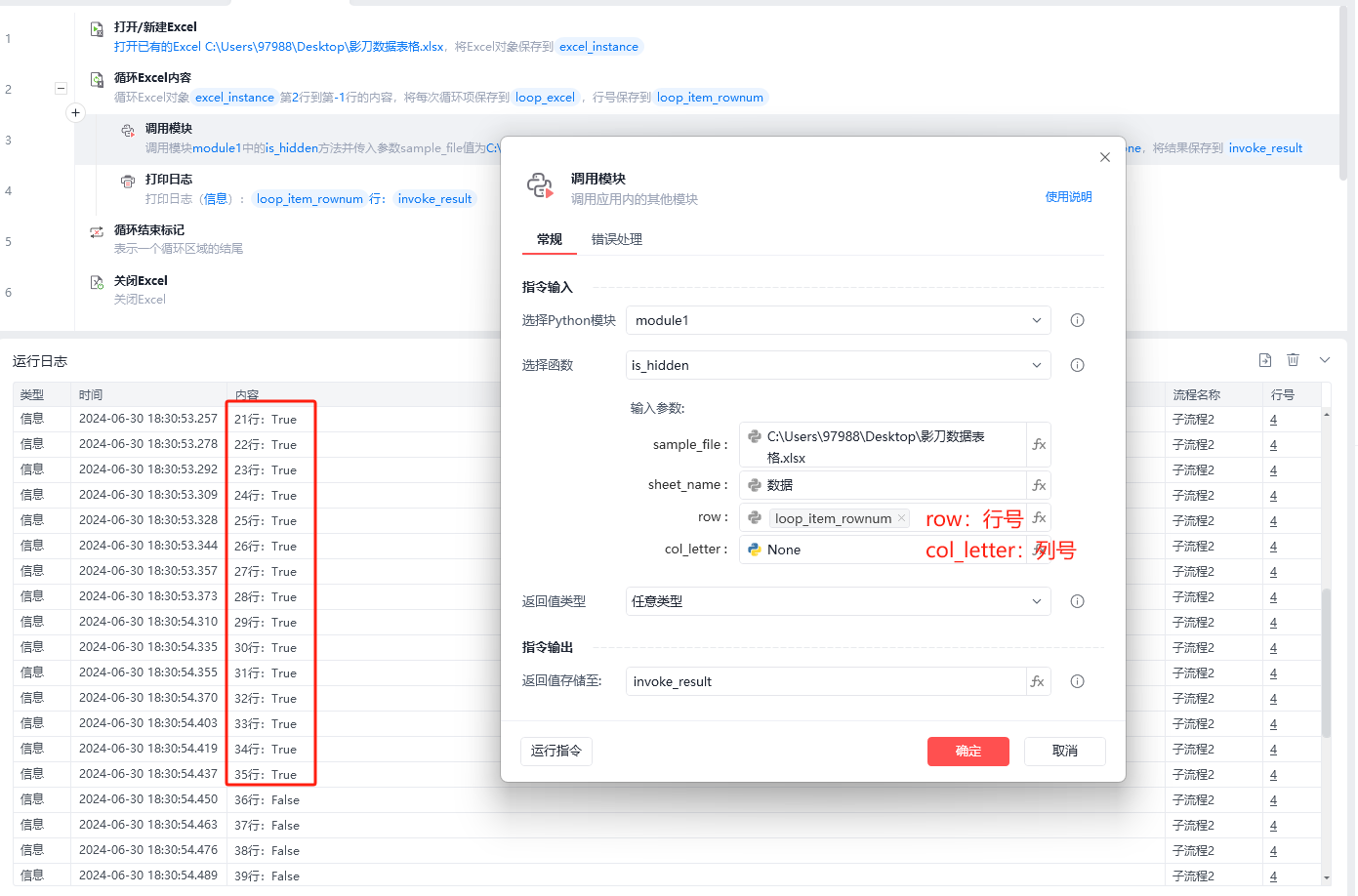
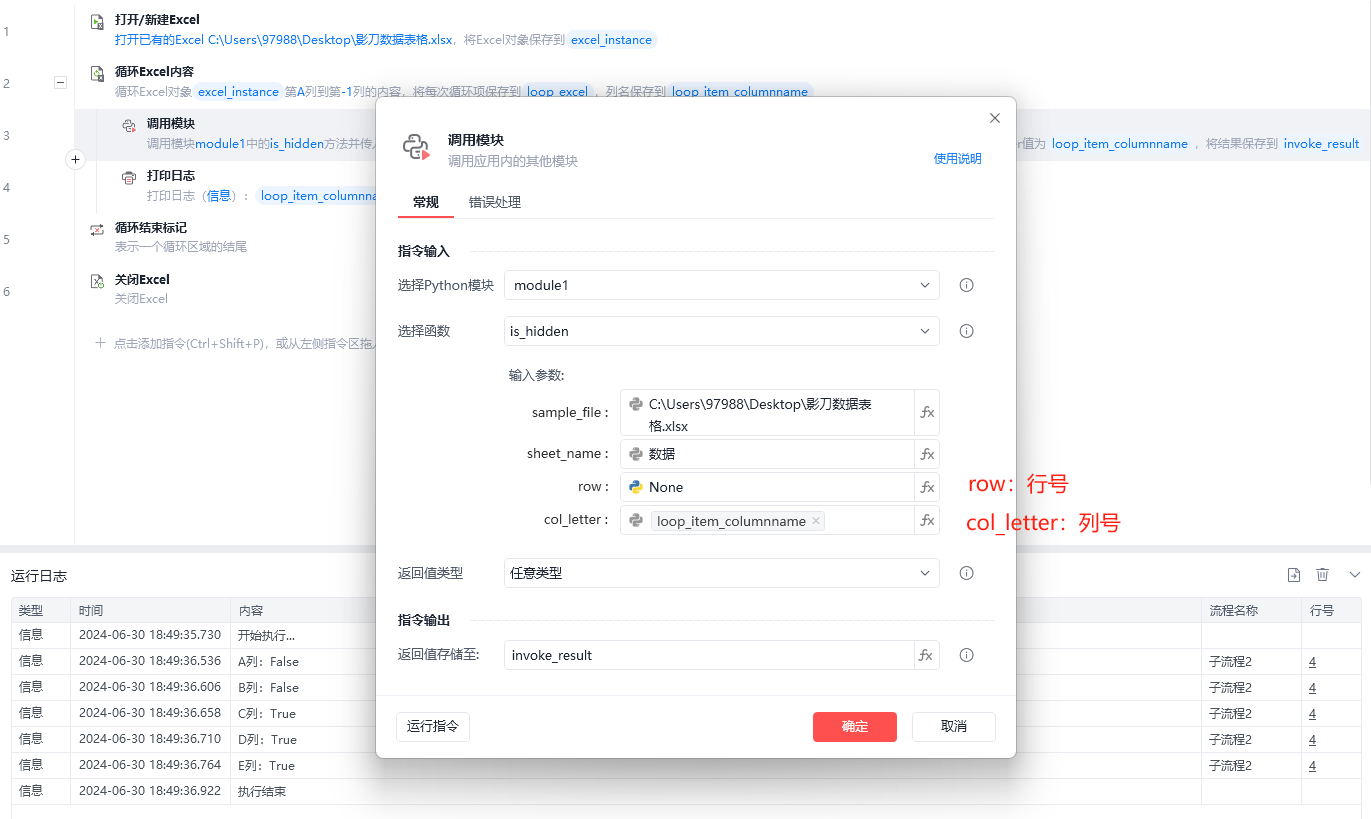
def is_hidden(sample_file, sheet_name=None, row=None, col_letter=None):
wb = load_workbook(sample_file, read_only=False, data_only=True)
ws = wb[sheet_name] if sheet_name else wb.active
if row and ws.row_dimensions[row].hidden:
return True
if col_letter and ws.column_dimensions[col_letter].hidden:
return True
return False
def clean_files(sample_file, sheet_name=None):
wb = load_workbook(sample_file, read_only=False, data_only=True)
if sheet_name:
sheet_names = [sheet_name]
else:
sheet_names = [wb.active.title]
for sheet in sheet_names:
ws = wb[sheet]
data, visible_cols = [], []
for col_idx in range(1, ws.max_column + 1):
col_letter = get_column_letter(col_idx)
if not is_hidden(sample_file, sheet, col_letter=col_letter):
visible_cols.append(col_idx)
for idx, row in enumerate(ws.iter_rows(values_only=True, max_col=ws.max_column), start=1):
if not is_hidden(sample_file, sheet, row=idx):
row_data = [cell for col_idx, cell in enumerate(row, start=1) if col_idx in visible_cols]
new_row = [i.strftime('%Y/%m/%d') if isinstance(i, datetime.datetime) else i for i in row_data]
data.append(new_row)
df = pd.DataFrame(data)
if not df.empty:
df.dropna(how='all', axis=1, inplace=True)
df.dropna(how='all', inplace=True)
df.reset_index(drop=True, inplace=True)
return df.values.tolist()三、使用方法:
第一种使用方法:调用其中的clean_files()方法,读取跳过隐藏行列后的excel表内容,输出二维列表。👇
第二种使用方法:在循环excel内容时,调用其中的is_hidden()方法,判断当前行或列是不是隐藏的。👇
- 判断当前行:
- 判断当前列:
收藏2全部评论(1)
最新
发布评论
评论




