 收藏
收藏【小技巧】Excel数据执行筛选速度慢?巧用代码拆分子表来提速。
有小伙伴反馈,使用影刀Excel扩展操作中的”筛选“指令时,在处理数据量较大的文件时,指令的执行速度会变得非常缓慢。在刚搭建完应用的时候,运行完大概是20多分钟,现在速度越来越慢了,可能需要两个小时才能执行完一个应用。
收到这个反馈,我也是做了多种测试来验证问题所在。
首先,这位小伙伴的表格有多个Sheet页,每一个Sheet页的数据都超过8000条。
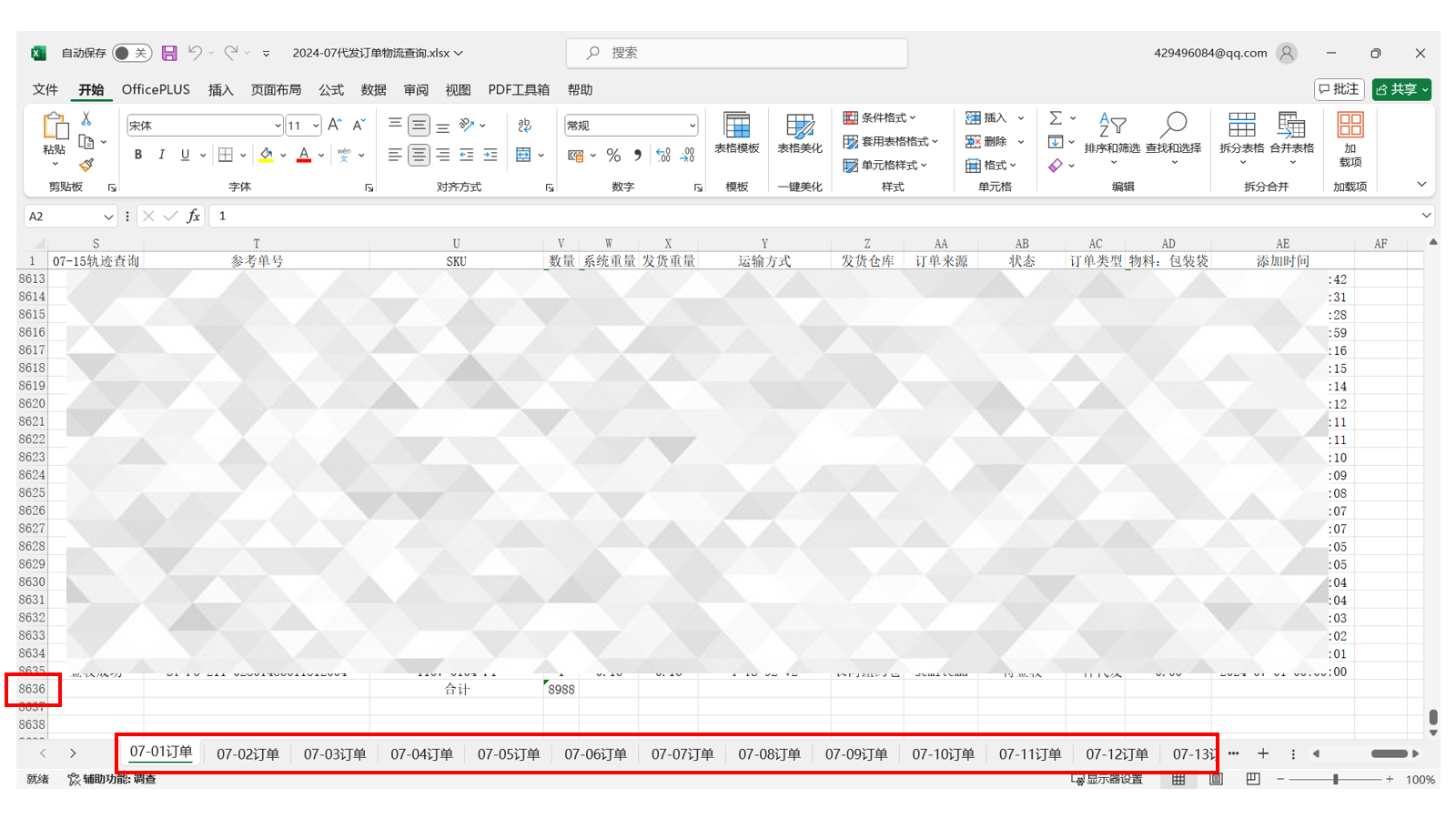
他的需求是,需要循环每一个Sheet,每个Sheet中需要对客户编号进行筛选、拷贝到另一个表格。
按照常规的逻辑,我先用指令来实现。一方面也是为了验证相同的流程在不同电脑的运行是否线下一致,排除设备原因。
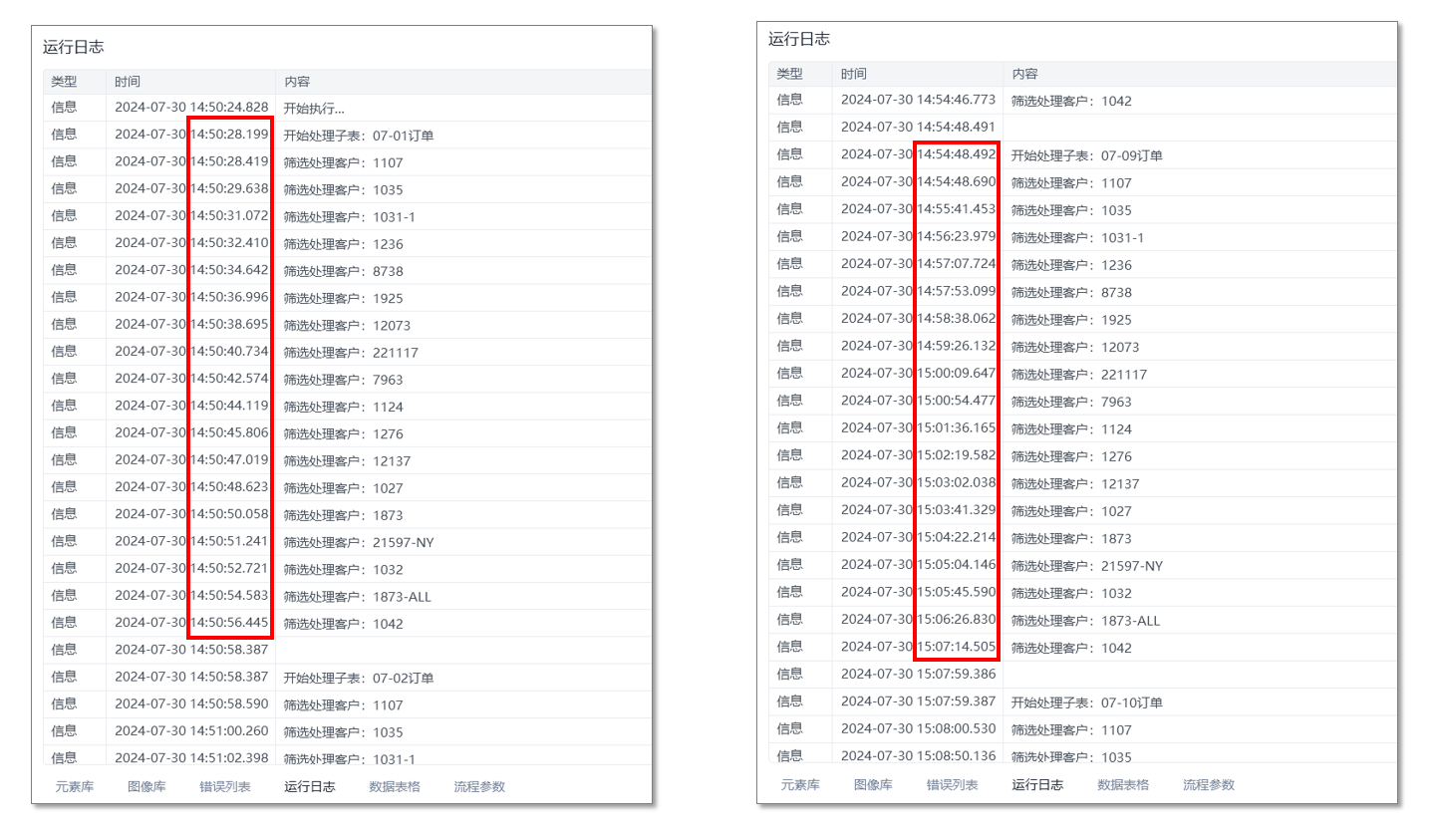
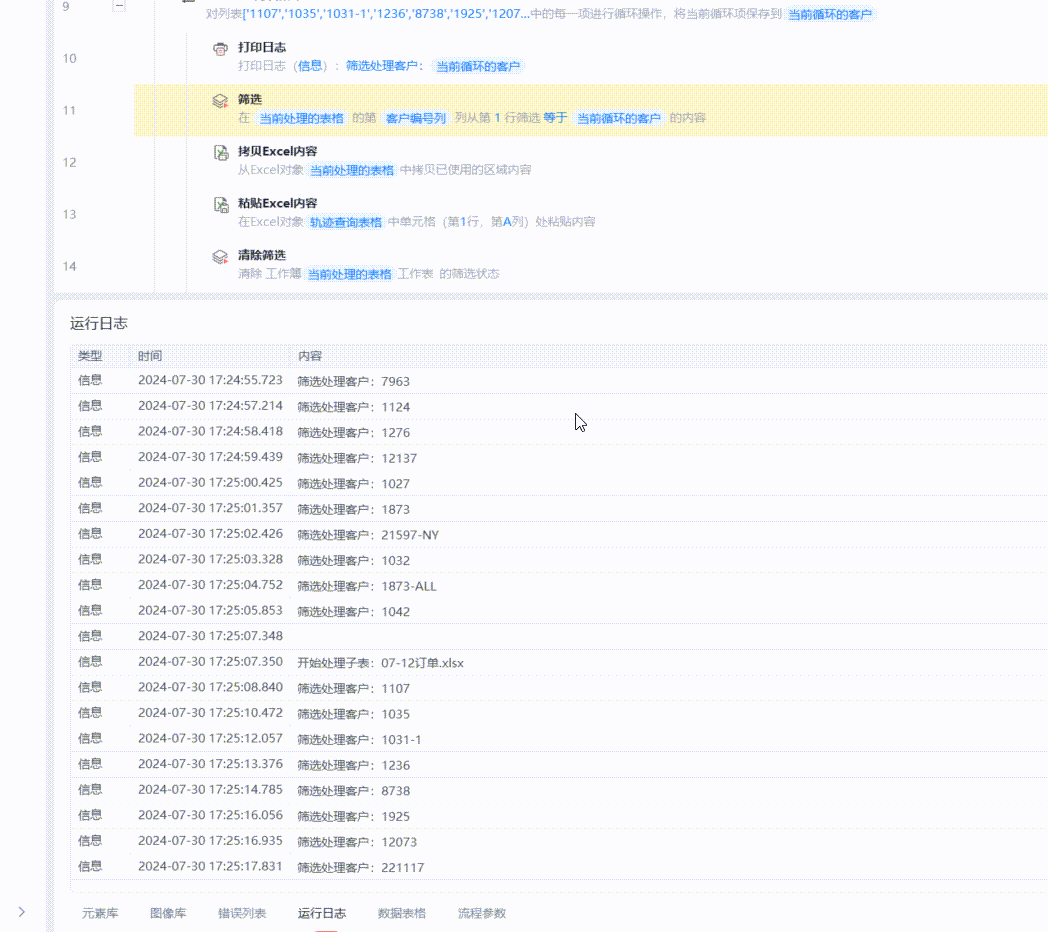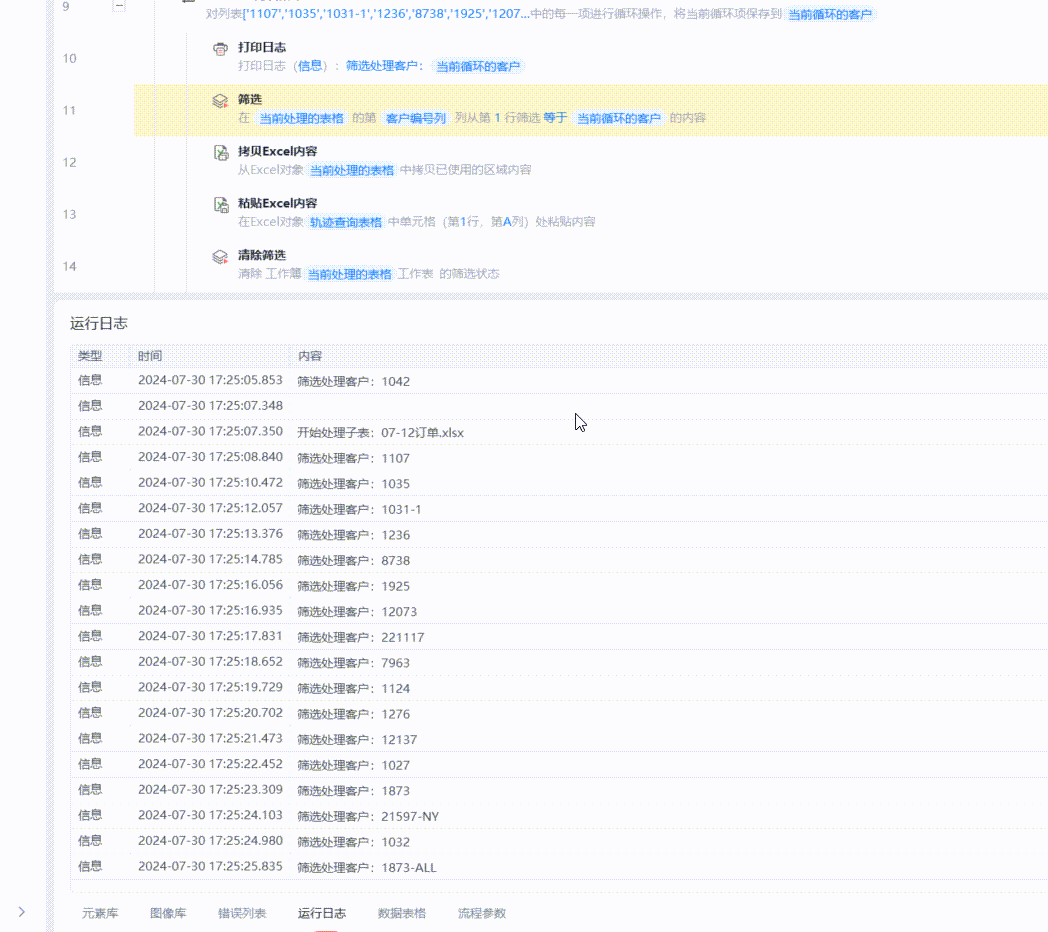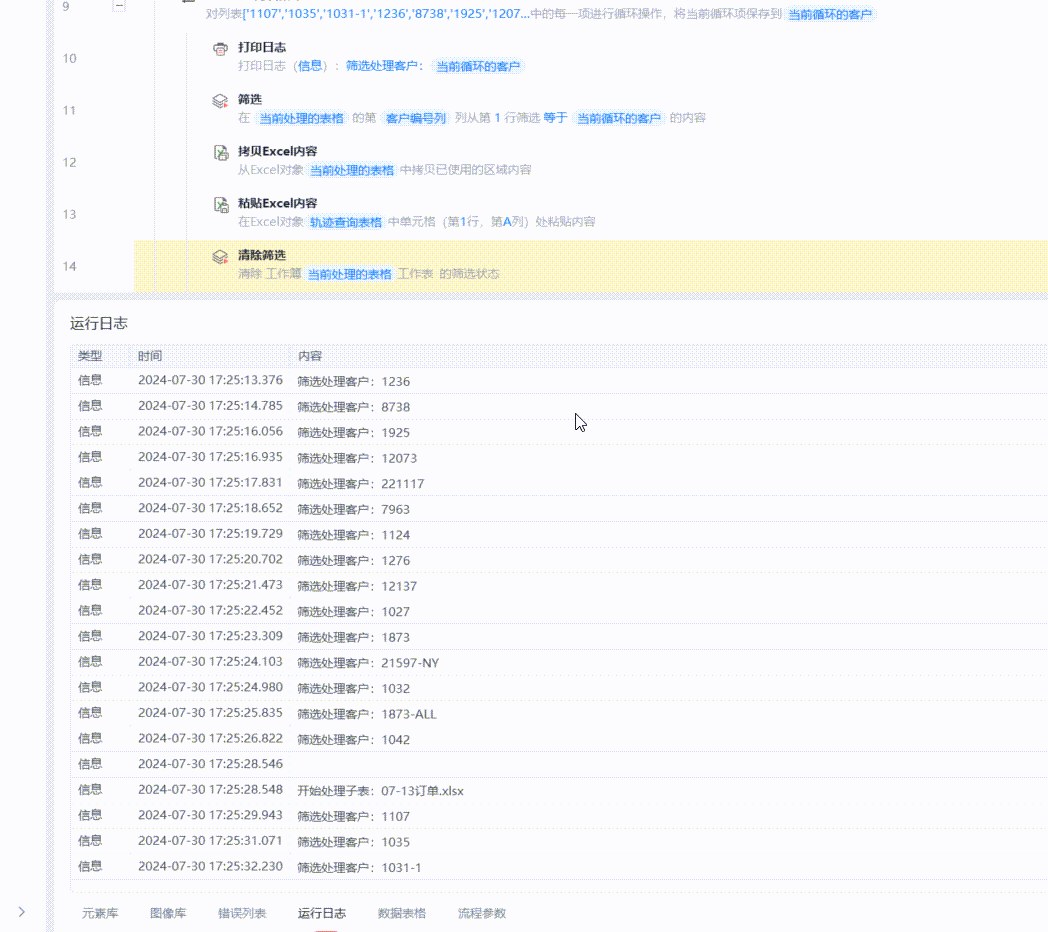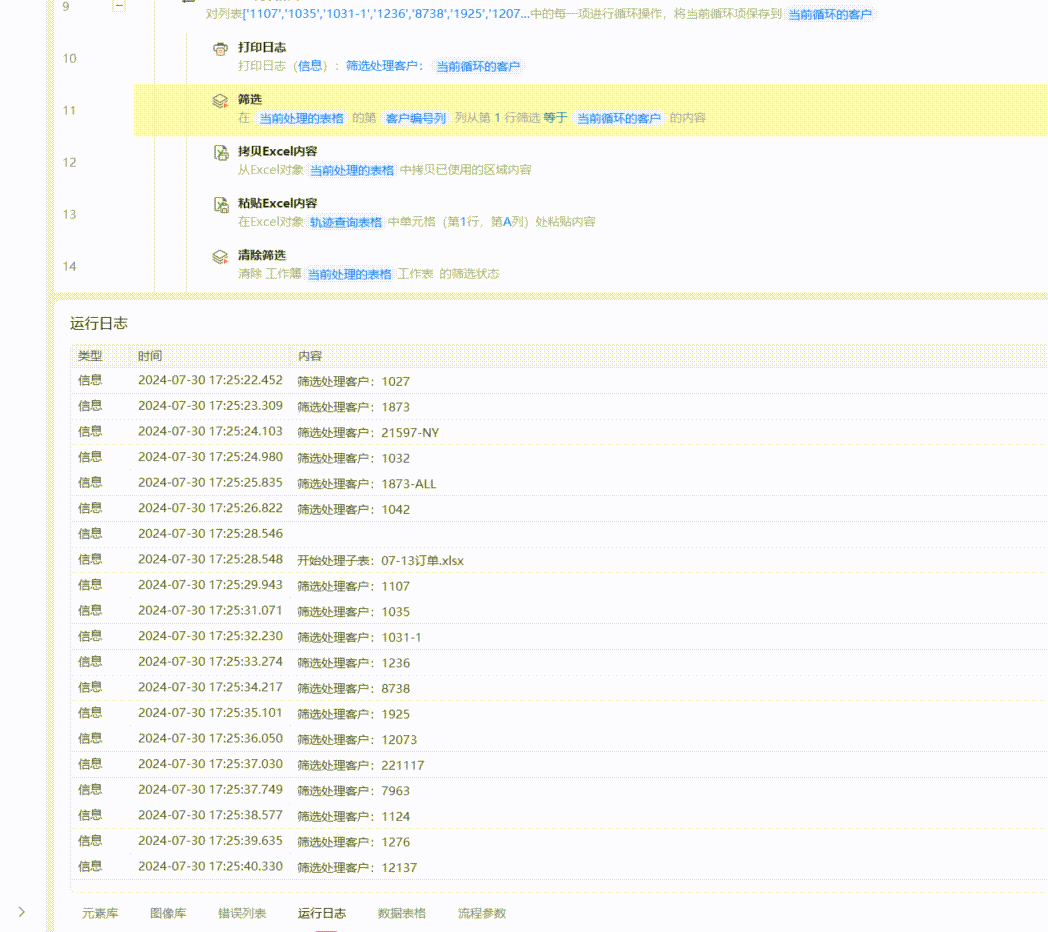
从运行日志来看,程序开始执行的Sheet,每一次筛选都是约1~2秒完成,从第”07-09订单“这个Sheet开始,速度就变得非常非常非常慢了,一次筛选可能需要用去约1分钟的时间。
此时,可以排除设备原因,并且推测可能是因为连续运行处理表格导致程序占内存从而运行速度变慢。
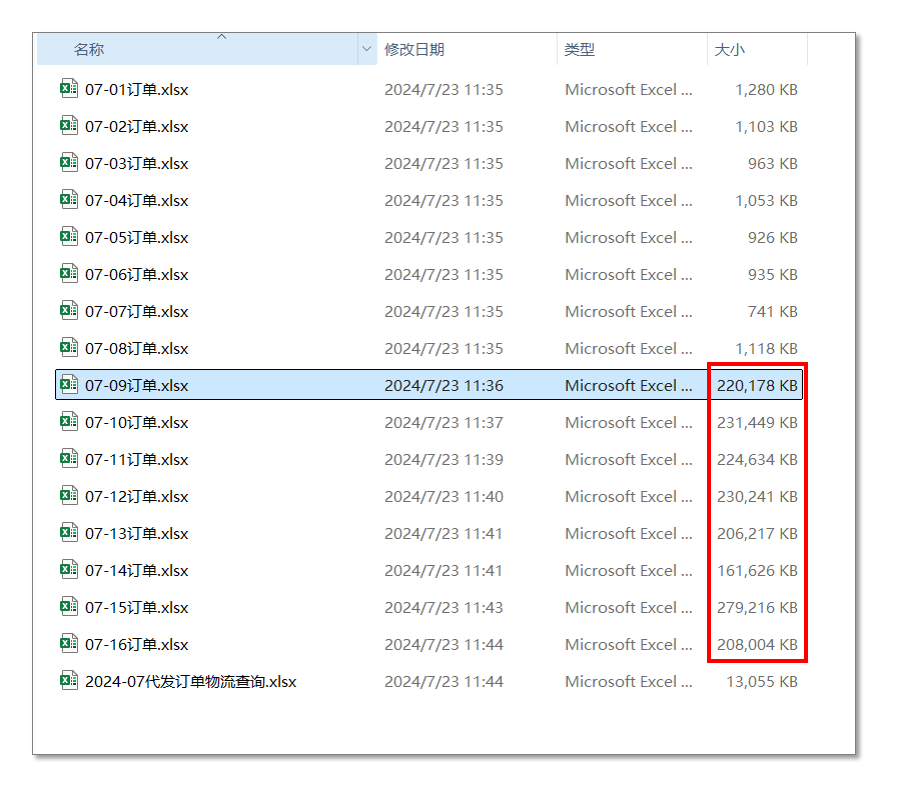
于是我萌生想法,先用指令将每个Sheet单独保存为一个Excel文件,再循环这些Excel文件进行单独的筛选,是否速度就可以提高一些呢?于是我
做了验证。却得到了一个意外的结果。使用指令单独将Sheet保存出来,这些新文件的文件大小却超出了预期,比如下图中从"07-09订单"开始后
的每个文件,一个文件就到了200m,远超原文件本身的大小。这个也可能就是影响原本程序到了该Sheet就运行速度急剧变慢的原因。
既然用指令处理得到此结果,那用代码来实现会不会也是同样的。
我用了以下这个代码,来实现将一个Excel文件的所有Sheet拆分成单独文件的效果。
import pandas as pd
import os
def split_excel_sheets(input_file, output_dir):
# 读取Excel文件
xls = pd.ExcelFile(input_file)
# 遍历所有表
for sheet_name in xls.sheet_names:
# 读取每个sheet
df = pd.read_excel(xls, sheet_name=sheet_name)
# 创建单独的工作簿文件名
output_file = os.path.join(output_dir, f"{sheet_name}.xlsx")
# 保存到新的工作簿
df.to_excel(output_file, index=False)从代码的执行结果来看,使用代码保存后的文件,所有文件的大小都在一个正常的范围内。
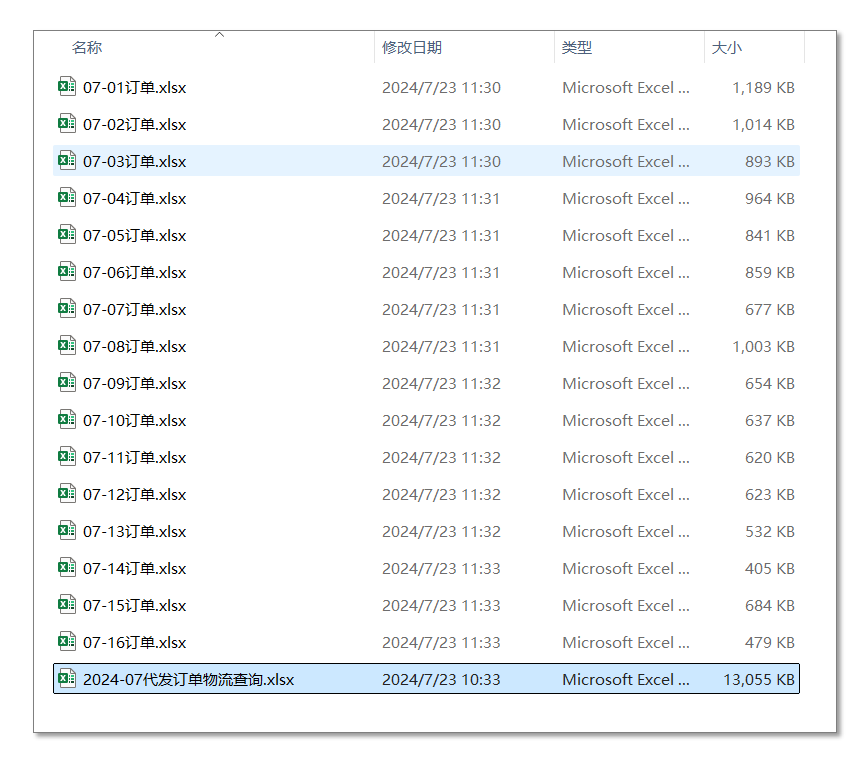
对拆分后的所有表格文件再进行筛选和后续操作,速度就可以达到一个比较可观的效果了。
补充说明 >>>
1. 使用上述代码,需要先在影刀安装 pandas 库;
2. 上述代码中,参数 input_file 为需要处理的原始文件,output_dir 为拆分出来的每一个文件保存的文件夹路径;
3. 使用代码对Excel表格进行拆分的部分,需要一定的运行时长,但是先慢后快,整体也快;
收藏2



