 收藏
收藏设计场景之Midjourney批量生图介绍
设计是一件偏主观性质的工作,所以RPA在设计领域能帮上忙的地方不多。以往只能在套模板批量处理图片场景上实现自动化,现在分享一个可以减轻设计师工作量的自动化场景——Midjourney批量生成图片。
Midjourney介绍
Midjourney是一款基于人工智能技术的绘画工具,它利用了机器学习和深度学习技术,让计算机可以像人类一样创作出精美的艺术品。素材收集得好,工作减轻不少。
设计师可以通过上传草图或者描述需求,然后交给AI绘画工具生成大量的素材图片,接着从素材中挑选合适的图片再做修改,从而完成工作。
虽然Midjourney生成的效果十分优异、功能也很齐全,但是它使用起来也会有不方便的地方,比如:需要参考的图片量较多,反复输入比较繁琐;生成图片需求等待较长时间。而这部分刚好可以用RPA来解决。
RPA可以自动上传设置好的内容,并逐个等待、保存生成的图片,最后将所有图片结果呈现给设计师。
RPA实现思路
假如现在需要让MJ通过一张图片生成其它类似图片,那么我们正常的执行流程是:
- 上传图片,选择点击提示词1;
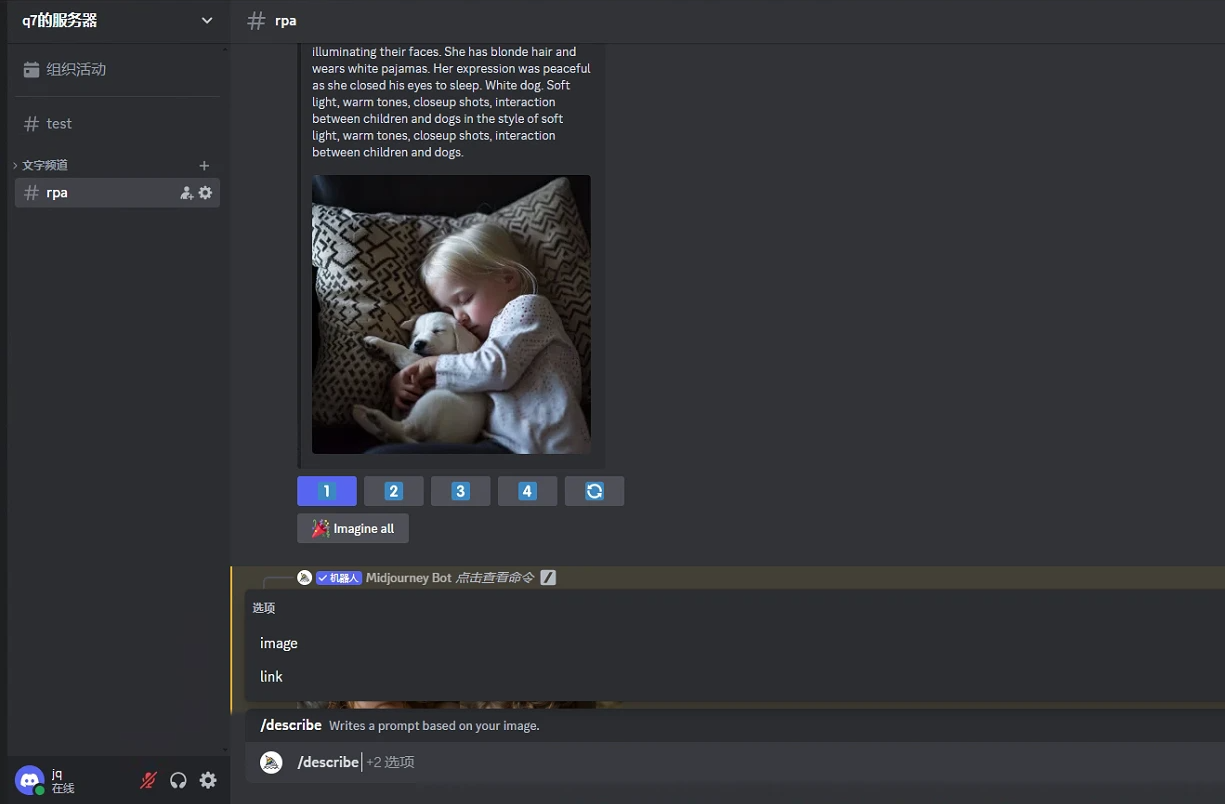
- 点击U按钮,生成单图;
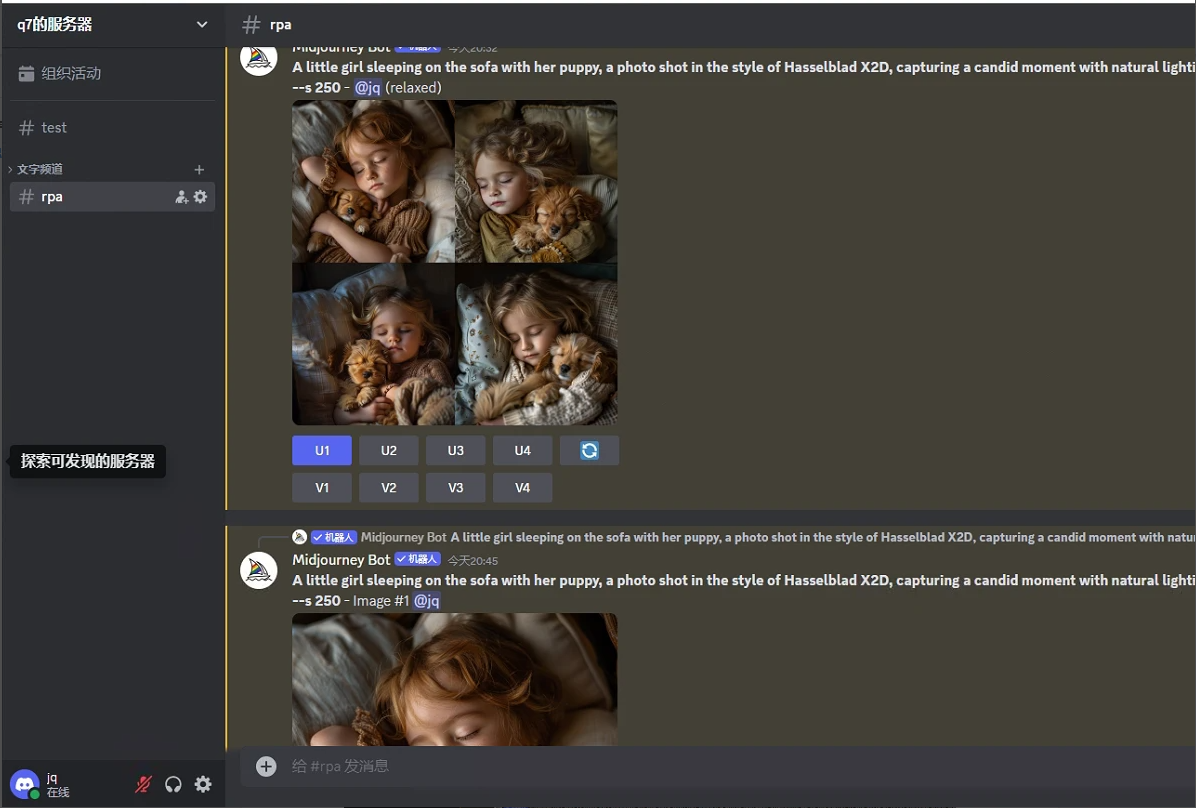
- 点击V按钮,生成拼图;
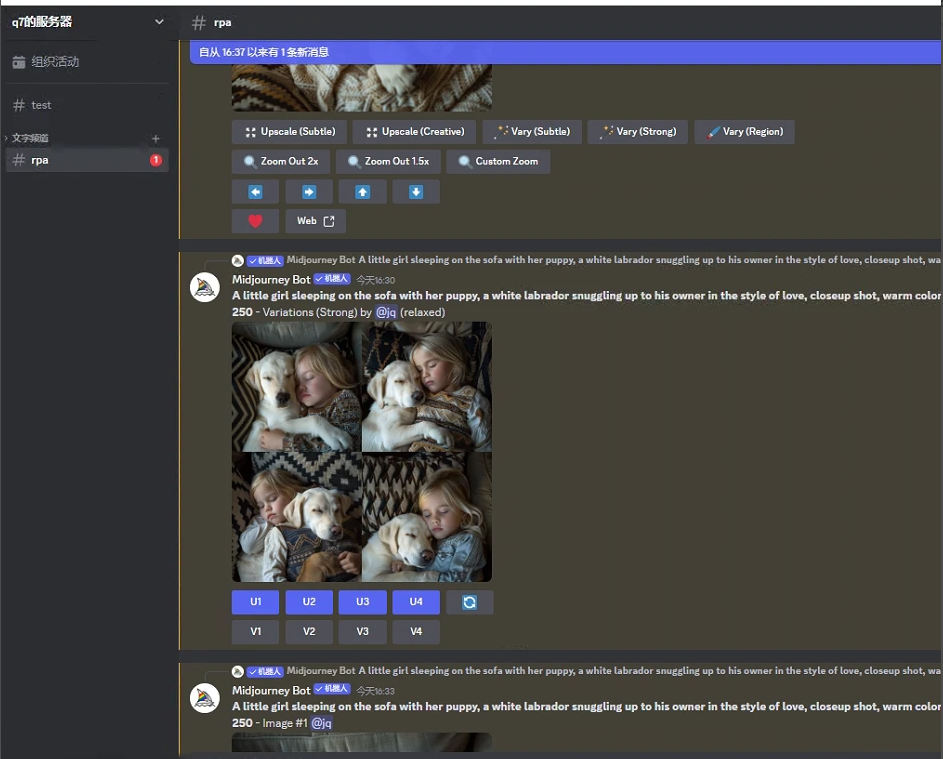
那么按正常逻辑来说,我们只需要用影刀捕获元素,然后点点点即可。然而实际操作的时候,我们会遇到几个问题:
- 无法通过标签或者属性来区分拼图和单图,只能通过li标签的位置确定;
- 无法通过标签或者属性来区分U按钮和V按钮,只能通过按钮的位置或者文本确定;
- 每次新生成图片时需要等待不定时的时间。
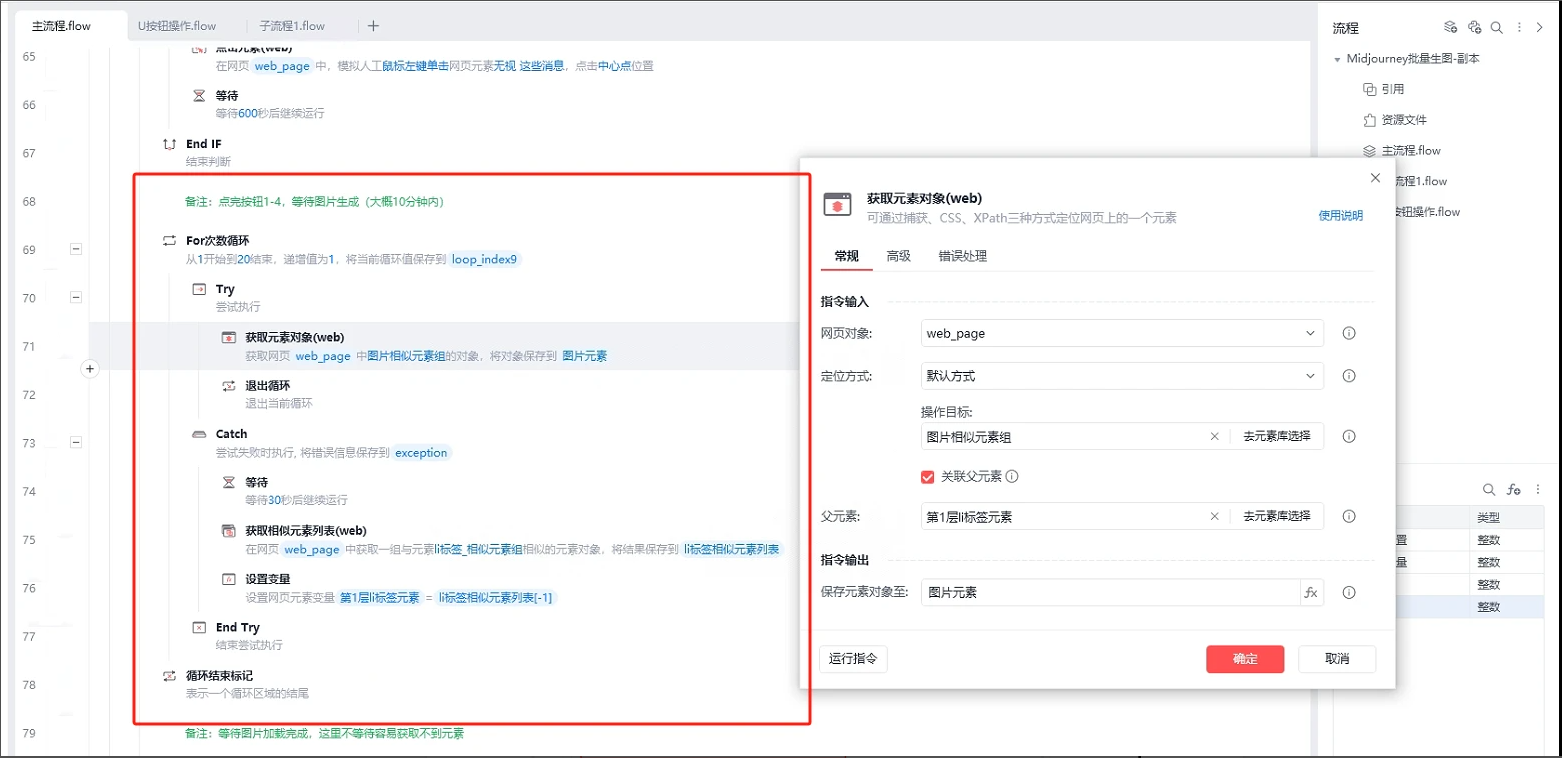
经过研究发现,每生成一次图片,网页就会在原有结果后面新加一个li标签。因此我们可以先记录重要的li标签位置,例如提示词1-4按钮的li标签、拼图的li标签,当通过点击1个提示词生成完一系列单图和拼图后,就可以回过头来根据位置找到第2个提示词。
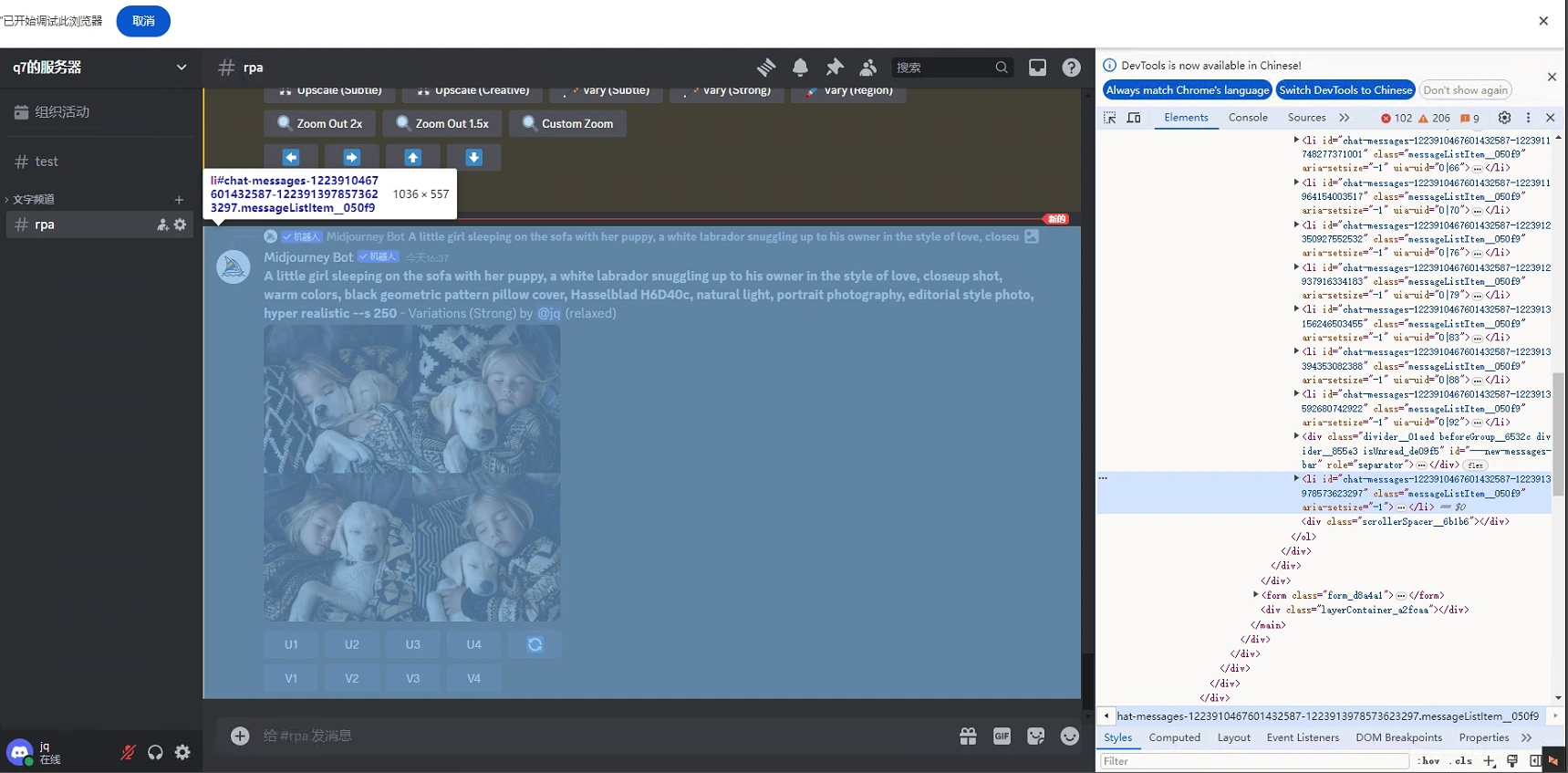
在确定完li标签后,我们可以通过父子元素定位到按钮,不过U按钮和V按钮之间只有位置和文本不同,如果不希望通过一个一个捕获元素再点击来实现的话,那么也可以使用循环给元素属性传参的方式来实现。具体操作可以参考之前文档的3.3部分: 数据抓取技巧之特殊网页抓取案例演示

关于第3个问题,正常来说可以使用等待元素(web)指令来实现,这样就需要通过给图片元素里上层li标签属性传参的方式来定位元素,再使用等待元素指令。不过这里我使用了通过循环+try+等待的方式来做一层等待判断,期间也可以适当做一些其它结果的判断。
视频演示
https://www.bilibili.com/video/BV1kf421Z72h/?vd_source=9805da21f042ac2dce7036fd6609a343
收藏3



