Excel操作,无法使用指令直接实现的内容集合 收藏
收藏
评论
收藏Excel操作,无法使用指令直接实现的内容集合

2024-09-03 17:22·浏览量:2033
土豆
一、下拉框(数据验证)
1.1设置下拉框(数据验证)
在指定单元格插入数据验证。影刀有指令可以直接实现,代码放在这里供参考
from openpyxl import Workbook
from openpyxl.worksheet.datavalidation import DataValidation
# 创建要操作的工作簿和工作表
wb= Workbook()
ws= wb.active
# 创建序列有效性的数据有效性对象
dv= DataValidation(type="list",formula1='"苹果,香蕉,脐橙"',allow_blank=True)
# 在工作表中添加数据有效性对象
ws.add_data_validation(dv)
# 在工作表单元格区域中添加数据有效性
dv.add('A1:A5')
# 保存工作簿
wb.save("测试.xlsx")1.2获取下拉框的内容和单元格位置
直接获取指定sheet页的所有下拉框位置和内容
import openpyxl
#封装函数
def read_with_dropdown(book_name, sheet_name):
# 读取excel
wb = openpyxl.load_workbook(book_name)
# 读取sheet表
ws = wb[sheet_name]
# 获取内容存在下拉选的框数据
validations = ws.data_validations.dataValidation
# 遍历存在下拉选的单元格
for validation in validations:
# # 获取下拉框中的所有选择值
cell = validation.sqref #单元格内容
result = validation.formula1 #下拉框内容
print("单元格位置:"+str(cell)+",下拉选内容:"+result)
# #调用函数
data = read_with_dropdown("测试.xlsx", "Sheet1")
# ————————————————
#版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,
转载请附上原文出处链接和本声明。
# 原文链接:https://blog.csdn.net/weixin_41267342/article/details/866340071.3一些注意事项与技巧
内容来源: python操作excel数据验证
如果单元格中的值不在数据有效性序列值中,运行时会出错:
cell2= ws["C3"]
c3.value= "无效值"
dv.add(cell2)
可用下列代码判断单元格中是否设置了数据有效性:
“B2”in dv
下面是一些设置数据有效性的代码示例:
1.允许任何整数:
dv= DataValidation(type=”whole”)
2.允许任何大于100的整数:
dv= DataValidation(type=”whole”, operator=”greaterThan”, formula=100)
3.允许任何小数:
dv= DataValidation(type=”decimal”)
4.允许任何0至1之间的小数:
dv= DataValidation(type=”decimal”, operator=”between”, formula1=0, formula2=1)
5.允许日期:
dv= DataValidation(type=”date”)
6.允许时间:
dv= DataValidation(type=”time”)
7.允许最多15个字符的字符串:
dv= DataValidation(type=”textLength”, operator=”lessThanOrEqual”, formula1=15)
8.单元格区域数据有效性:
fromopenpyxl.utils import quote_sheetname
dv= DataValidation(type=”list”, formula1=”{0}!$B$1:$B$10”.format(quote_sheetname(sheetname))
9.自定义规则:
dv= DataValidation(type=”custom”, formula1=”=公式”)二、excel隐藏内容(Sheet页,行列)
2.1查找隐藏的Sheet页
import openpyxl
#首先定义获取所有Sheet页名称的函数
def get_all_sheet_names(wb):
"""
获取所有sheet的名称
:param wb:
:return:
"""
# sheet名称列表
sheet_names = wb.sheetnames
return sheet_names
def get_all_sheet(wb):
"""
获取所有的sheet
:param wb:
:return:
"""
# sheet名称列表
sheet_names = get_all_sheet_names(wb)
# 所有sheet
sheets = []
for sheet_name in sheet_names:
sheet = wb[sheet_name]
sheets.append(sheet)
return sheets
#通过判断 Sheet 对象的 sheet_state 属性值,可以判断当前 Sheet 是显示还是隐藏
#当值为 visible 时,代表 Sheet 是显示的
#当值是 hidden 时,代表这个 Sheet 被隐藏了
def get_all_visiable_sheets(wb):
"""
获取工作簿中所有可见的sheet
:param wb:
:return:
"""
return [sheet for sheet in get_all_sheet(wb) if sheet.sheet_state == 'visible']
def get_all_hidden_sheets(wb):
"""
获取工作簿中所有隐藏的sheet
:param wb:
:return:
"""
return [sheet for sheet in get_all_sheet(wb) if sheet.sheet_state == 'hidden']
————————————————
#版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
#原文链接:https://blog.csdn.net/qq_40932679/article/details/1209012822.2查找隐藏的行列
import openpyxl
from openpyxl.utils import get_column_letter, column_index_from_string
#使用 sheet.max_row 和 sheet.max_column 可以获取当前 Sheet 中的数据行数和列数
def get_row_and_column_num(sheet):
"""
获取sheet的行数和列数
:param sheet:
:return:
"""
# 行数
row_count = sheet.max_row
# 列数
column_count = sheet.max_column
return row_count, column_count
# 行数和列数
row_count, column_count = get_row_and_column_num(sheet)
print('行数和列数分别为:', row_count, column_count)
#遍历 Sheet 对象的 row_dimensions 属性值,通过判断行属性的 hidden 值,判断当前行是否隐藏或显示
def get_all_rows_index(sheet, hidden_or_visiable):
"""
获取所有隐藏/显示的行
:param hidden_or_visiable: True:隐藏;False:显示
:param sheet:
:return:
"""
# 遍历行
# 隐藏的索引
row_hidden_indexs = []
column_hidden_indexs = []
# 所有隐藏的行索引
for row_index, rowDimension in sheet.row_dimensions.items():
if rowDimension.hidden:
row_hidden_indexs.append(row_index)
# 所有显示的行索引
visiable_indexs = [index + 1 for index in range(get_row_and_column_num(sheet)[0]) if index + 1 not in row_hidden_indexs]
# 所有隐藏的列索引
for column_index, columnDimension in sheet.column_dimensions.items():
if columnDimension.hidden:
column_hidden_indexs.append(column_index)
# 所有显示的列索引,get_column_letter实现数字转字母
visiable_column = [get_column_letter(column) for column in range(1,get_row_and_column_num(sheet)[1]+1) if get_column_letter(column) not in column_hidden_indexs]
# 隐藏或者显示的行索引列表
print(row_hidden_indexs,column_hidden_indexs if hidden_or_visiable else visiable_indexs)
return row_hidden_indexs,column_hidden_indexs if hidden_or_visiable else visiable_indexs
file_path = r"测试.xlsx"
wb = openpyxl.load_workbook(file_path)
get_all_rows_index(wb['Sheet5'],0)三、获取单元格属性(待完善)
3.1字体颜色,单元格颜色,行高,列宽
import openpyxl
from openpyxl.utils import get_column_letter, column_index_from_string
from openpyxl.styles import Font, Color, PatternFill
file_path = r"测试.xlsx"
wb = openpyxl.load_workbook(file_path)
sheet = wb['Sheet5']
cell = wb['Sheet5']['A1']
# 字体颜色
font_color = cell.font.color.rgb if cell.font.color.rgb else None
# 背景色
fill_color = cell.fill.fgColor.rgb if cell.fill.fgColor.rgb else None
# 行高
row_height = sheet.row_dimensions[cell.row].height
# 列宽
column_width = sheet.column_dimensions[get_column_letter(cell.column)].width
# 打印单元格属性
print(f"字体颜色: {font_color}")
print(f"背景色: {fill_color}")
print(f"行高: {row_height}")
print(f"列宽: {column_width}")
3.2字体,大小,是否加粗,是否斜体
import openpyxl
from openpyxl.utils import get_column_letter, column_index_from_string
from openpyxl.styles import Font, Color, PatternFill
wb = openpyxl.load_workbook(file_path)
cell = wb['Sheet5']['A1']
font = cell.font
# name 字体,size 大小 ,bold 大写 ,italic 斜体
print(font.name, font.size, font.bold, font.italic)3.3边框颜色获取
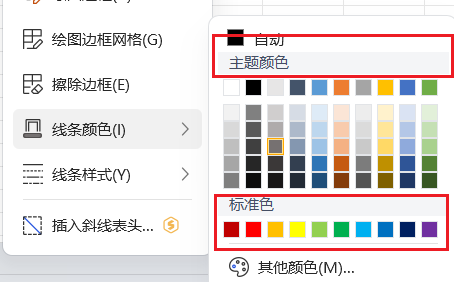
# excel主题色和标准色不一样,用openpyxl方法获取会得结果Values must be of type <class 'str'>
# 参考CSDN大佬文章修改的 https://blog.csdn.net/as604049322/article/details/134470419?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171862715116800178591125%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=171862715116800178591125&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-134470419-null-null.nonecase&utm_term=%E5%8D%95%E5%85%83%E6%A0%BC&spm=1018.2226.3001.4450
# 感谢二乔及大佬
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
def main(args):
pass
import pandas as pd
from openpyxl import load_workbook
from openpyxl.styles.colors import RGB
from openpyxl.styles import Font
from openpyxl.styles import Border, Side
from colorsys import rgb_to_hls, hls_to_rgb
from openpyxl.styles.colors import RGB
class ThemeColorConverter:
RGBMAX = 0xff
HLSMAX = 240
def __init__(self, wb):
self.colors = self.get_theme_colors(wb)
@staticmethod
def tint_luminance(tint, lum):
if tint < 0:
return int(round(lum * (1.0 + tint)))
return int(round((ThemeColorConverter.HLSMAX - lum) * tint)) + lum
@staticmethod
def ms_hls_to_rgb(hue, lightness=None, saturation=None):
if lightness is None:
hue, lightness, saturation = hue
hlsmax = ThemeColorConverter.HLSMAX
return hls_to_rgb(hue / hlsmax, lightness / hlsmax, saturation / hlsmax)
@staticmethod
def rgb_to_hex(red, green=None, blue=None):
if green is None:
red, green, blue = red
return '{:02X}{:02X}{:02X}'.format(
int(red * ThemeColorConverter.RGBMAX),
int(green * ThemeColorConverter.RGBMAX),
int(blue * ThemeColorConverter.RGBMAX)
)
@staticmethod
def rgb_to_ms_hls(red, green=None, blue=None):
if green is None:
if isinstance(red, str):
if len(red) > 6:
red = red[-6:] # Ignore preceding '#' and alpha values
rgbmax = ThemeColorConverter.RGBMAX
blue = int(red[4:], 16) / rgbmax
green = int(red[2:4], 16) / rgbmax
red = int(red[0:2], 16) / rgbmax
else:
red, green, blue = red
h, l, s = rgb_to_hls(red, green, blue)
hlsmax = ThemeColorConverter.HLSMAX
return (int(round(h * hlsmax)), int(round(l * hlsmax)),
int(round(s * hlsmax)))
@staticmethod
def get_theme_colors(wb):
from openpyxl.xml.functions import QName, fromstring
xlmns = 'http://schemas.openxmlformats.org/drawingml/2006/main'
root = fromstring(wb.loaded_theme)
themeEl = root.find(QName(xlmns, 'themeElements').text)
colorSchemes = themeEl.findall(QName(xlmns, 'clrScheme').text)
firstColorScheme = colorSchemes[0]
colors = []
for c in ['lt1', 'dk1', 'lt2', 'dk2', 'accent1', 'accent2', 'accent3', 'accent4', 'accent5', 'accent6']:
accent = firstColorScheme.find(QName(xlmns, c).text)
for i in list(accent):
if 'window' in i.attrib['val']:
colors.append(i.attrib['lastClr'])
else:
colors.append(i.attrib['val'])
return colors
def theme_and_tint_to_rgb(self, theme, tint):
rgb = self.colors[theme]
h, l, s = self.rgb_to_ms_hls(rgb)
return self.rgb_to_hex(self.ms_hls_to_rgb(h, self.tint_luminance(tint, l), s))
# # 加载Excel文件
workbook = load_workbook(r'text.xlsx')
sheet = workbook['Sheet1'] # 替换为你要操作的工作表名称
# 标准色边框获取
# 获取单元格D5的边框颜色
cell = sheet['D5']
Border_rgb = cell.border.top.color.rgb
if isinstance(Border_rgb,RGB) ==True :
# 主题色边框获取
# 获取单元格D5的边框颜色
cell = sheet['D5']
Border_tint = cell.border.top.color.tint #透明度
Border_theme = cell.border.top.color.theme #theme类型的颜色,确实是索引5的位置
theme_color = ThemeColorConverter(workbook)
result = theme_color.theme_and_tint_to_rgb(Border_theme,Border_tint)
print(result)
else:
print(Border_rgb)
四、Sheet页移动
4.1移动Sheet页并到最前面(指令有其他方式实现,但是不够直接快速)
import openpyxl
# 打开 Excel 文件
workbook = openpyxl.load_workbook(r'file_path')
# 获取要移动的 sheet 页
sheet = workbook['sheet2']
# 移动到最前面
#-数代表往前,index(sheet)得到需要移动的距离
workbook.move_sheet(sheet, offset=-workbook.index(sheet))
# 保存文件
workbook.save(r'file_path')
五、条件格式
5.1 conditional_formatting参数枚举
以下是operator参数的可选取值:
'between': 如果单元格的值在指定的范围内,则应用条件格式。
'notBetween': 如果单元格的值不在指定的范围内,则应用条件格式。
'equal': 如果单元格的值等于指定的值,则应用条件格式。
'notEqual': 如果单元格的值不等于指定的值,则应用条件格式。
'greaterThan': 如果单元格的值大于指定的值,则应用条件格式。
'lessThan': 如果单元格的值小于指定的值,则应用条件格式。
'greaterThanOrEqual': 如果单元格的值大于或等于指定的值,则应用条件格式。
'lessThanOrEqual': 如果单元格的值小于或等于指定的值,则应用条件格式。
下面是formula参数的规则取决于不同的operator值:
'between'和'notBetween': 对应的formula参数应该是一个包含两个值的列表,表示范围的下限和上限。
'equal'和'notEqual': 对应的formula参数应该是一个包含一个值的列表,表示要比较的具体数值。
'greaterThan'、'lessThan'、'greaterThanOrEqual'和'lessThanOrEqual': 对应的formula参数应该是一个包含一个值的列表,表示要比较的具体数值。5.2 具体案例
(此坑待补充)
六、查找重复值
6.1 筛选列上重复项并去重输出结果
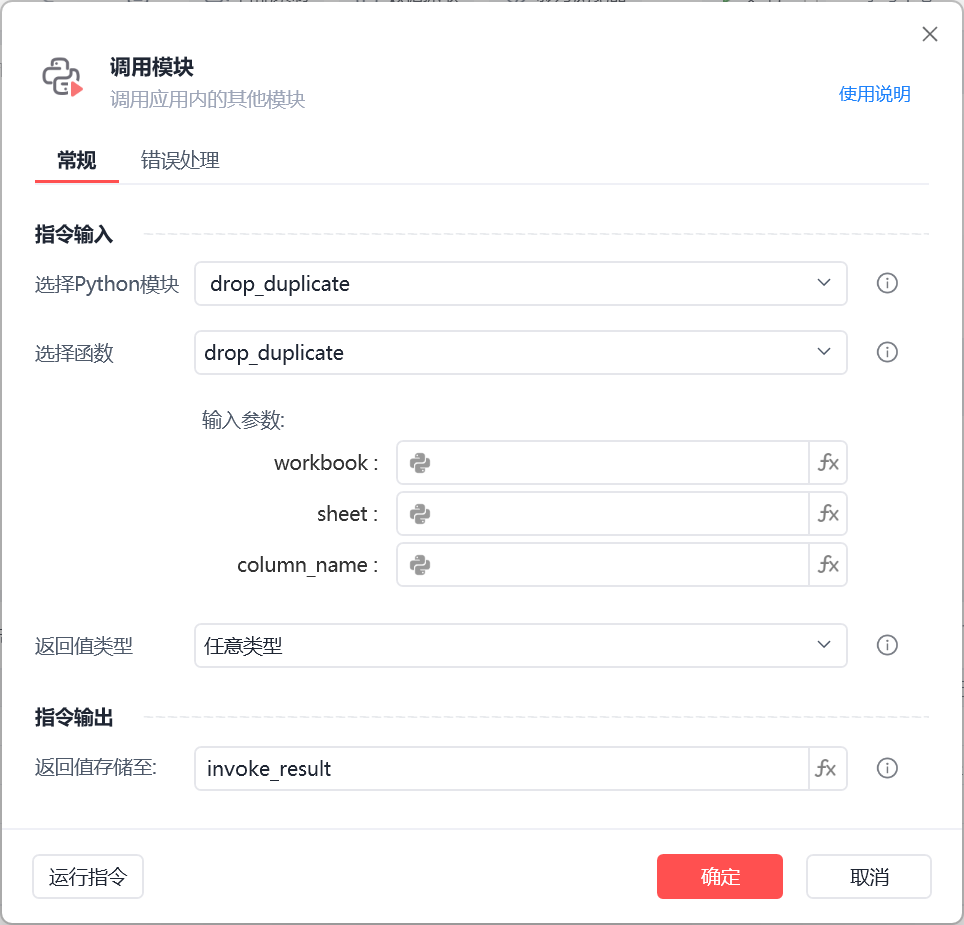
#影刀实际案例,筛选列上重复项并去重输出结果
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
def main(args):
pass
import pandas as pd
def drop_duplicate(workbook,sheet,column_name):
# 读取Excel文件中指定sheet页的数据
# book_name = r"C:\Users\土豆\Desktop\ceshi.xlsx"
# sheet_name = 'Sheet1'
# column_name = '城市'
# 读取指定sheet页的数据
df = pd.read_excel(workbook, sheet_name=sheet)
# 查找指定列上的重复值并删除重复项
duplicate_values_in_column = df[column_name][df.duplicated(subset=column_name, keep=False)]
drop_data_list = list(duplicate_values_in_column.drop_duplicates())
return drop_data_list6.2 一些大佬的参考资料
#参考链接:https://blog.csdn.net/u014740628/article/details/134047456
import pandas as pd
# 创建一个包含重复项的数据集
data = {
'col1': ['A', 'B', 'A', 'C', 'D', 'E', 'F', 'G', 'A'],
'col2': ['W', 'X', 'Y', 'Z', 'W', 'X', 'Y', 'Z', 'R'],
'col3': [1, 2, 3, 4, 1, 2, 3, 4, 5]
}
df = pd.DataFrame(data)
# 查找重复项
duplicates = df.duplicated()
print(duplicates)
# 删除重复项
df_dropped = df.drop_duplicates()
print(df_dropped)
# 指定列进行重复项的查找和删除
duplicates_col1_col2 = df.duplicated(['col1', 'col2'])
print(duplicates_col1_col2)
df_dropped_col1_col2 = df.drop_duplicates(['col1', 'col2'])
print(df_dropped_col1_col2)
# 保留重复项的第一个或最后一个
df_dropped_keep_last = df.drop_duplicates(keep='last')
print(df_dropped_keep_last)
# 统计重复项
duplicates_sum = duplicates.sum()
print(duplicates_sum)
# 标记重复项
duplicates_boolean = df.duplicated(keep=False)
print(duplicates_boolean)
# 检查重复项并替换
df_replaced = df.replace({'A': 'Z'})
print(df_replaced)
# 指定不同的重复项
df_dropped_diff = df.drop_duplicates(subset=['col1'], keep=False)
print(df_dropped_diff)
# 设定阈值
df_dropped_threshold = df.drop_duplicates(subset='col1', keep=False, threshold=3)
print(df_dropped_threshold)
# 根据指定列对重复项进行排序
df_drop_sort = df.drop_duplicates(subset=['col1'], keep='first').sort_values(by=['col1'])
print(df_drop_sort)
# 检查重复索引
index_duplicates = df.index.duplicated()
print(index_duplicates)
# 检查重复值
col1_duplicates = df['col1'].duplicated()
print(col1_duplicates)
col1_duplicates_unique = col1_duplicates.unique()
print(col1_duplicates_unique)七、合并单元格
7.1 查找合并单元格开始结束行列
import openpyxl as xl
from openpyxl.worksheet.worksheet import Worksheet
from openpyxl.cell import MergedCell
wb = xl.load_workbook(r"D:\tudoudesk\Workbook2.xlsx")
sheet = wb["Sheet1"]
merged_ranges = sheet.merged_cell_ranges # 获取当前工作表的所有合并区域列表
for merged_range in merged_ranges:
# print(type(merged_range)) # 打印区域对象类型
cell = sheet.cell(row = merged_range.min_row,column =merged_range.min_col )
# print(cell.value)
if cell.value == "SEAL #":
print(merged_range) # 打印区域
八、sheet页保护
8.1 sheet取消密码(取消保护-已知密码)
import os
import win32com.client
from win32com.client import Dispatch
# 如果有打开的excel窗口先关闭,否则后边会无法解除密码
def removePassword(file_path,password):
try:
xlApp = win32com.client.DispatchEx('Excel.Application')
except Exception as err:
print('错误: %s' % err)
try:
if not os.path.isfile(file_path):
print(file_path +'不是文件')
# 关闭可视化
xlApp.Visible = False
# 禁用兼容性检查
xlApp.DisplayAlerts = False
# 打开文件
wb = xlApp.Workbooks.Open(file_path)
try:
# print(password)
wb.Unprotect(password)
wb.Checkcompatibility = False
# 获取工作簿中设置了密码的工作表名称
sheet_names = [sheet.Name for sheet in wb.Sheets if sheet.ProtectContents]
for sheet_name in sheet_names:
sht = wb.Worksheets(sheet_name)
sht.Unprotect(password)
except Exception as err:
print('清除 %s 的保护密码出错:%s' % (file_path, err))
wb.Save()
wb.Close(SaveChanges=True)
finally:
if hasattr(xlApp, 'Quit'):
xlApp.Quit()
8.2 sheet设置密码(保护工作表)
import win32com.client
def set_sheetpassword(file_path,password):
# 创建 Excel 应用程序对象
xlApp = win32com.client.DispatchEx('Excel.Application')
xlApp.Visible = False
xlApp.DisplayAlerts = False
# 打开 Excel 文件
wb = xlApp.Workbooks.Open(file_path)
# 获取要设置密码的所有工作表对象
sheet_names = [sheet.Name for sheet in wb.Sheets]
for sheet_name in sheet_names:
sheet = wb.Sheets(sheet_name) # 替换为您要设置密码的工作表名称
# 设置保护密码
# password = "your_password"
sheet.Protect(password)
# 保存并关闭工作簿
wb.Save()
wb.Close()
# 退出 Excel 应用程序
xlApp.Quit()全部评论(1)
最新
发布评论
评论




