监听并保存网页中的媒体文件 收藏
收藏
评论
收藏监听并保存网页中的媒体文件
恒
2024-10-24 15:27·浏览量:1083
恒
恒星
背景:
使用过影刀的”监听网页请求“指令的小伙伴都指定,监听是一种非常高效的获取数据方式,不过我们常用的是监听网页请求去获取json文件,解析得到所需的信息。如果我们想通过监听去获取网页中的媒体文件,比如某个mp4视频,应该怎么操作呢?
思路:
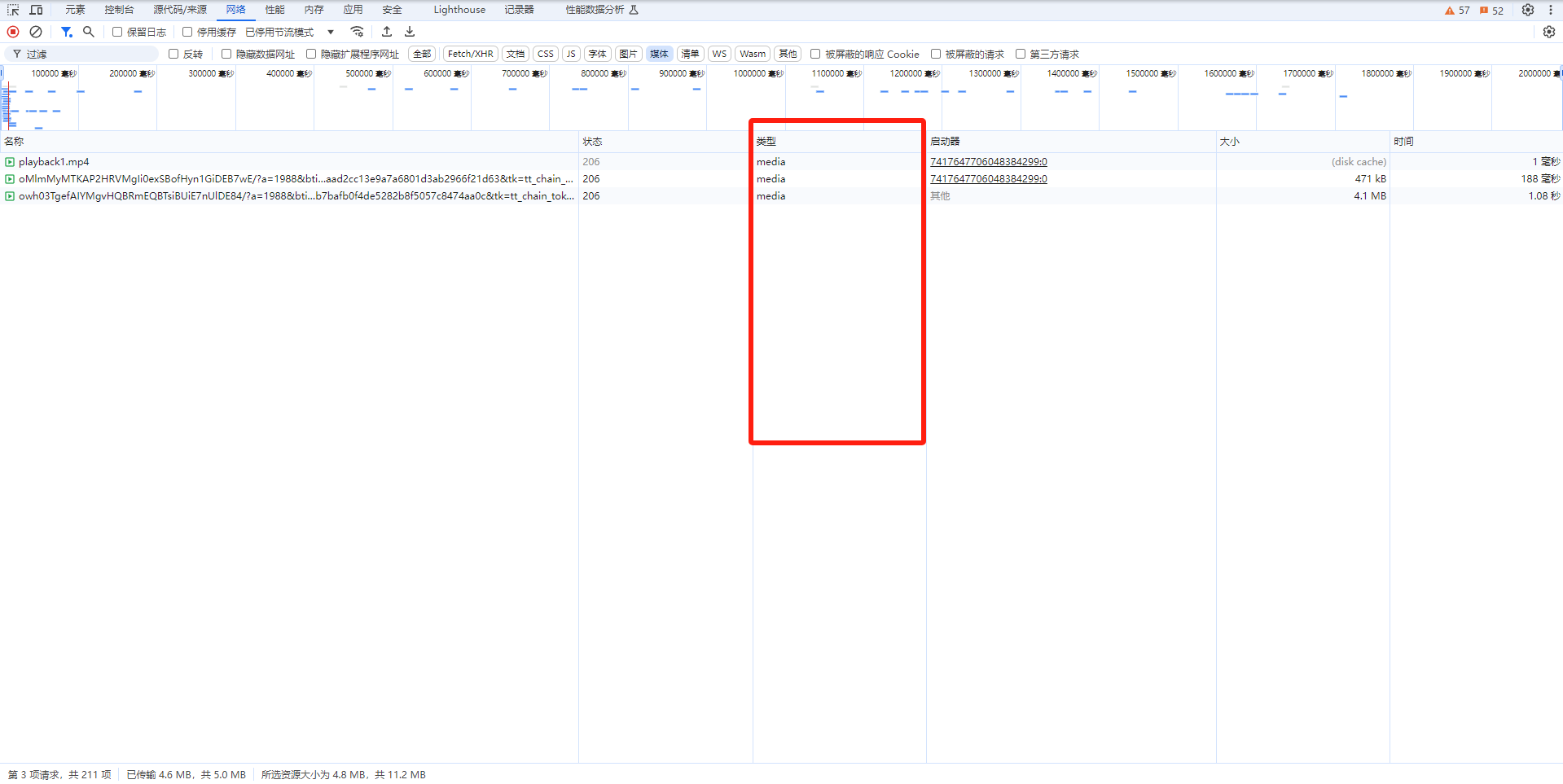
在浏览器的开发者工具的 Network 面板中(这里以chrome为例),找到媒体文件对应的网页请求,右键-”将内容保存为 HAR 文件“,使用文本编辑器打开,可以看到文件中有一串很长的字符,如下:

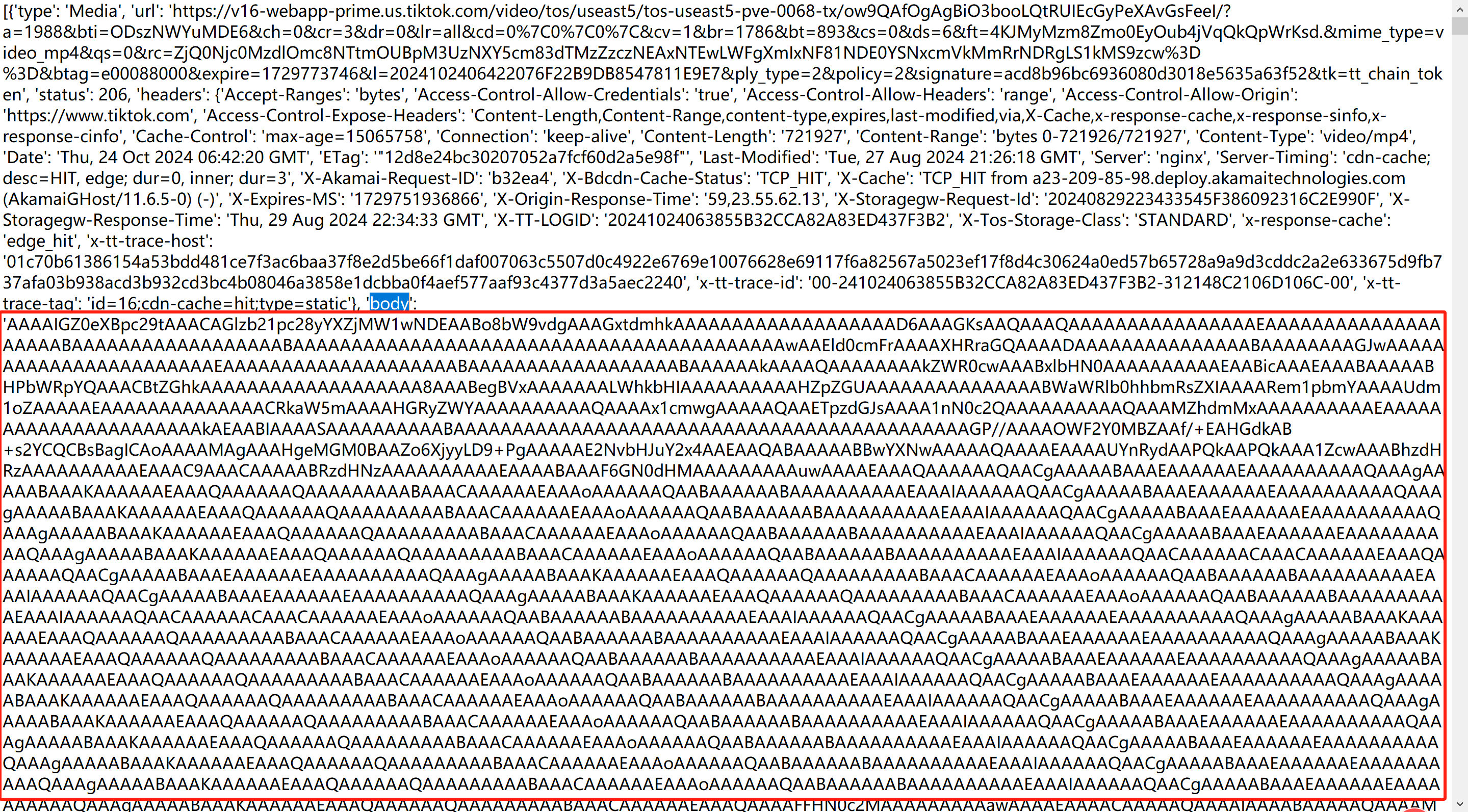
在最后可以看到这串字符其实是base64编码的数据:
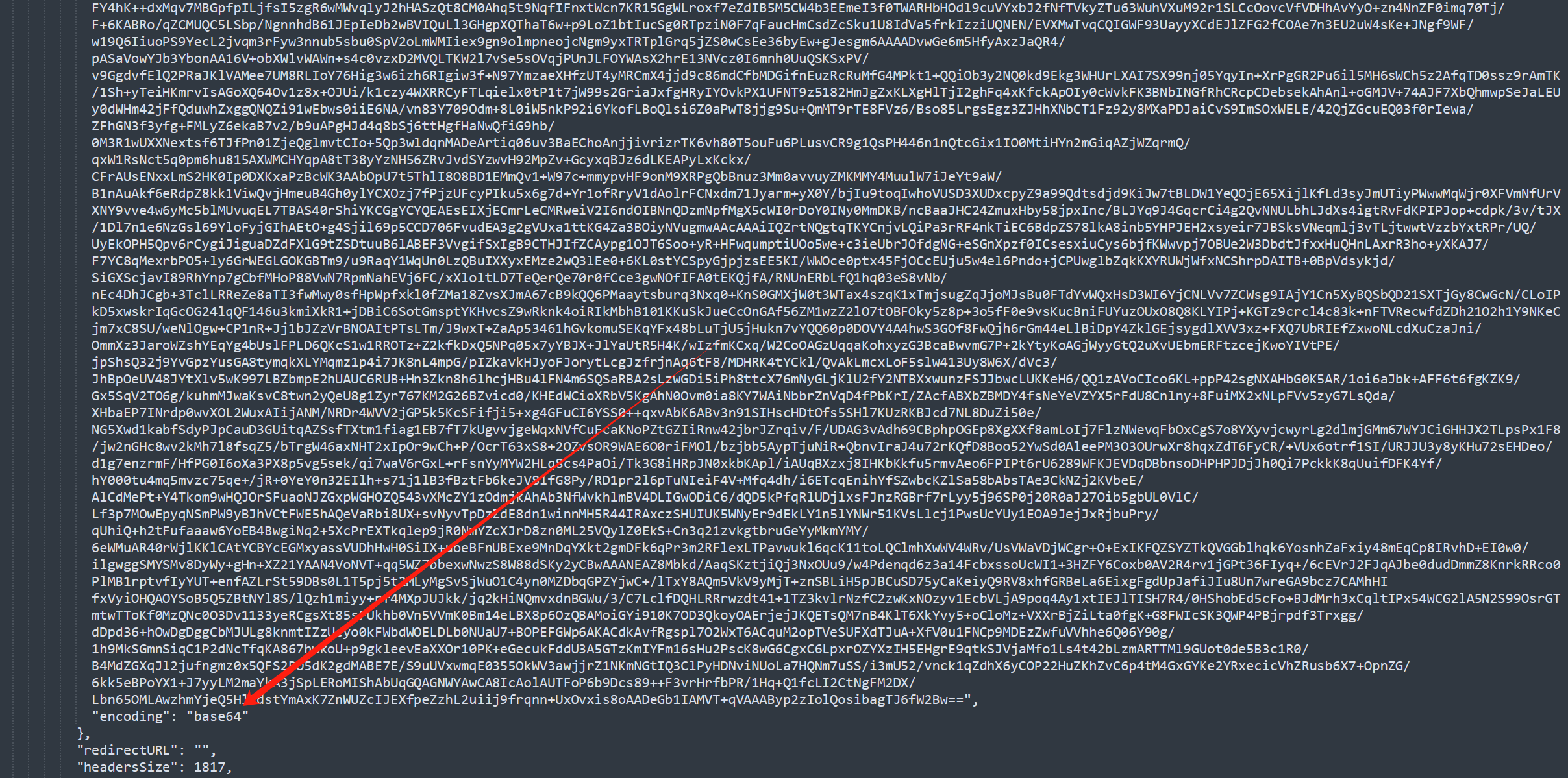
我们猜测把这段数据从base64解码写入为文件,即可还原为mp4文件。
这里附上base64转mp4文件的代码:
import base64
def base64_to_mp4(base64_string, output_file):
"""将 Base64 编码的字符串转换为 MP4 文件。
Args:
base64_string: Base64 编码的字符串。
output_file: 输出 MP4 文件的路径。
"""
try:
# 解码 Base64 字符串
decoded_data = base64.b64decode(base64_string)
# 将解码后的数据写入文件
with open(output_file, 'wb') as f:
f.write(decoded_data)
print(f"MP4 文件已保存到: {output_file}")
except Exception as e:
print(f"转换失败: {e}")
把base64编码和文件保存路径传入函数中执行,验证了我们的猜想,确实可以成功生成mp4文件。
具体实现:
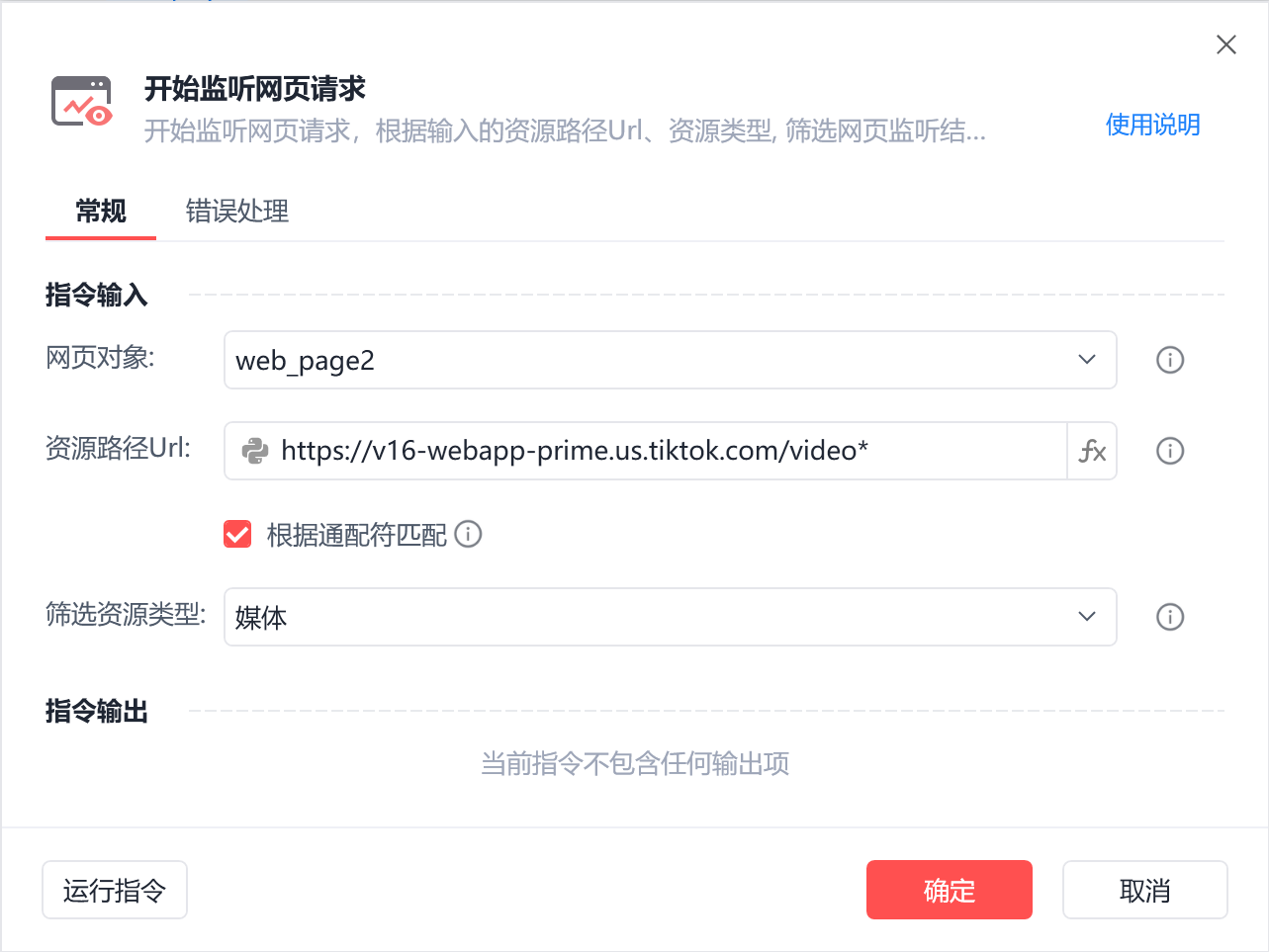
1、使用网页监听获取网页请求数据:

本案例中是监听tiktok的视频页,监听的url为:https://v16-webapp-prime.us.tiktok.com/video*
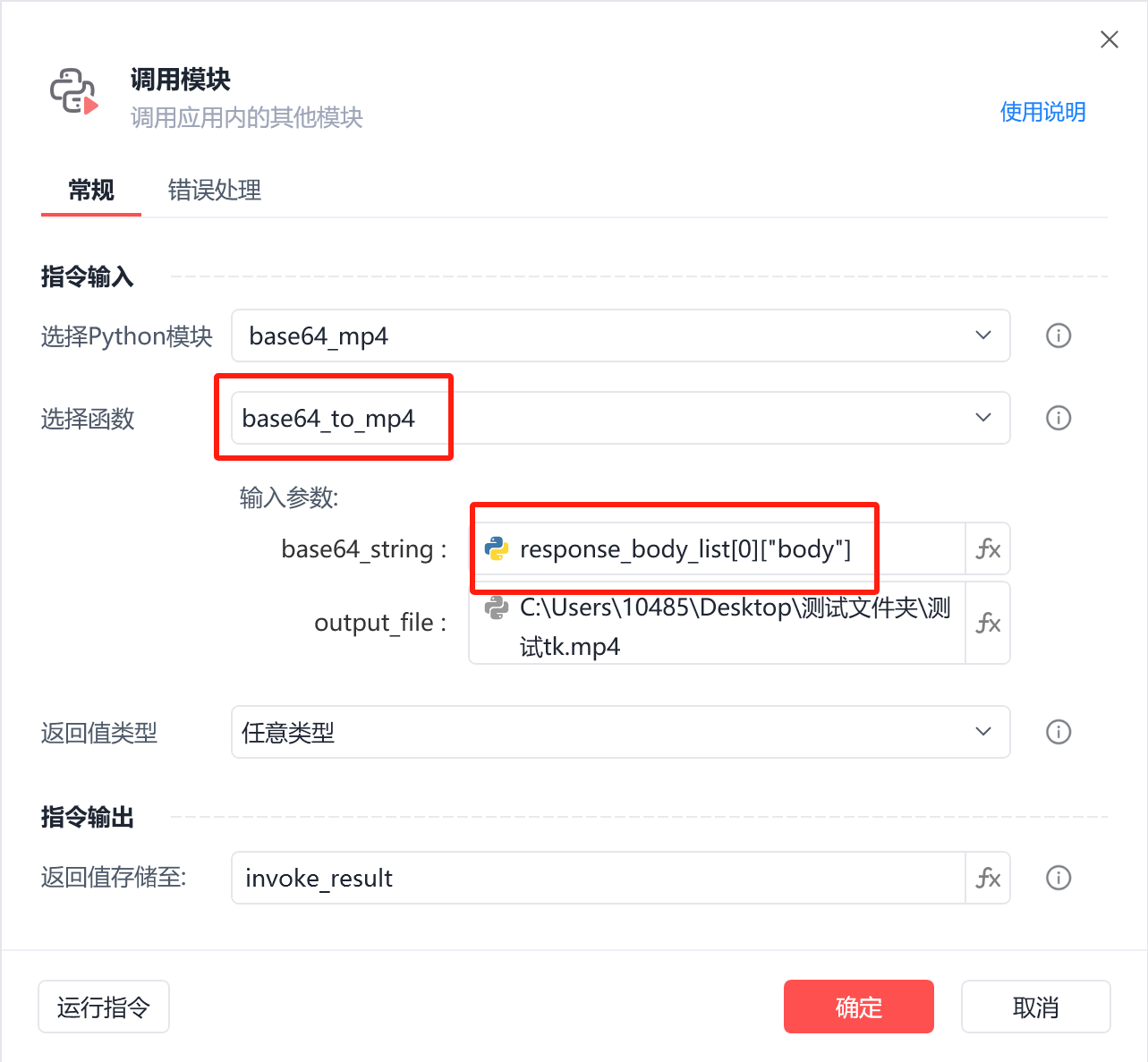
2、提取监听结果中的base64编码内容,传入上面提供的函数中:
从监听结果查找发现,base64编码内容就在监听结果的body里面:
调用函数:
一个简单的demo就搭建完成啦!

PS:如果有小伙伴未学习过网页监听,可以移步到我们专题课程中学习一下哈。传送门: https://www.bilibili.com/video/BV1hg41127Xg/
收藏9全部评论(1)
最新
发布评论
评论




