 收藏
收藏基于文本描述在Excel中高效匹配信息的场景与解决方案
一、基础场景
场景描述
客户向客服反馈需要重新发货的商品名称——>客服在在线表格中填写商品名称,并在仓库表中寻找对应的商品条码——>仓库依据条码完成补发
错误思路
考虑到客服填写的商品名称可能出现简写,设计了一个“匹配”方案(类似于“二、进阶版”中的流程),这让整个过程繁琐且效率很低
优化后的解决方案
- 在“在线表格”中,将商品名称那一列设置为“下拉选项”,用户只需输入商品简称即可快速找到对应的全称。
- 将在线表格保存至本地,并在“商品条码”列批量插入VLOOKUP公式,即能实现快速且准确的查找。
二、进阶场景
场景描述
客户在平台上留下备注——>这些备注会实时同步到商家的ERP系统中——>客服依据这些备注内容找到对应的商品条(但由于客户需求多样,商品名称填写往往不够精确)
2.1 核心逻辑图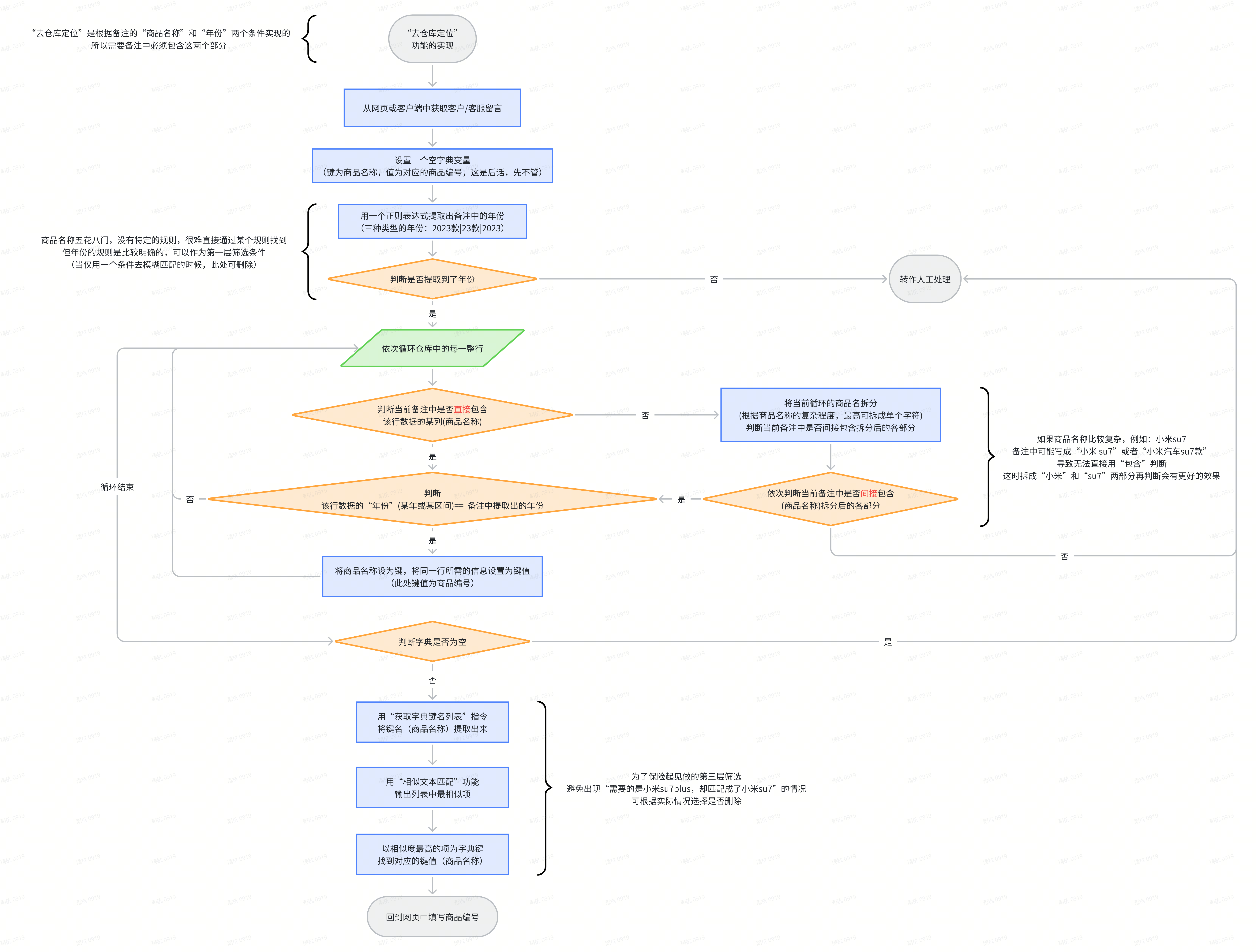
该流程的示例是通过“商品名称”和“年份”(两个条件互为补充),但也适用于单“商品名称”匹配的情况。
2.2 其他方案的思考
虽然为了确保非常高的准确率,我们使用了多层筛选去实现模糊匹配,但毕竟逻辑较为复杂。
为简化流程,我思考了流程中“硬匹配”(直接用“包含”关系)和“软匹配”(将商品名称拆分后逐一用“包含”关系)优化的可能性。经过一段时间的测试与假设(因为已帮助客户将应用落地,不好再拿客户的场景验证新思路 ),我发现这种逻辑与“文本相似匹配”高度一致,其通过引用difflib库中的SequenceMatcher类,能够更好地捕捉文本之间的顺序关系和结构。
),我发现这种逻辑与“文本相似匹配”高度一致,其通过引用difflib库中的SequenceMatcher类,能够更好地捕捉文本之间的顺序关系和结构。
2.2.1 构想一
通过测试发现,“文本相似匹配”在勾选了“只输出最相似的文本”选项时,可以准确的从一个“商品名称”列表中找到对应项,但存在一个问题,由于客户需求多样,留言中也不是必然包含某个商品名称的,如果只是简单的“只输出最相似的文本”,可能会出现留言:“萨达挖的哇s啊方式发我”(无意义留言),却匹配成了“小米su7”的情况。、
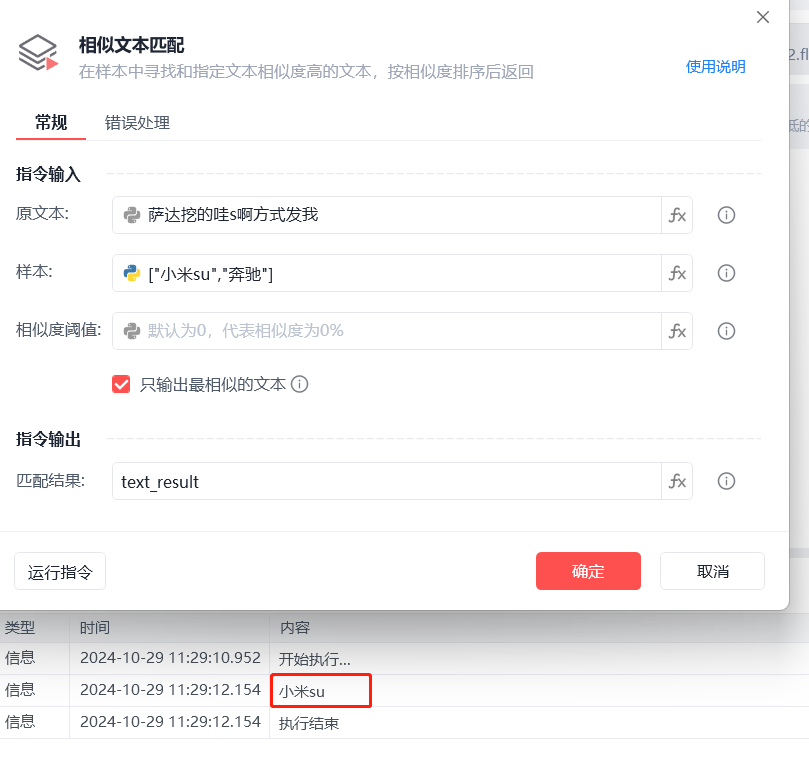
当然,这个也有解决办法,就是设置“相似度阈值”,但这个同样有问题————这个阈值的计算逻辑不是那么的透明,目前我也没有找到一个准确的公式去计算它,目前我依据我这边的场景能给到的参考值是0.3(最好做一些简单的计算,设置一个动态值,例如:
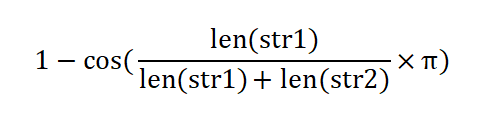
令len/len那部分等于x,则有有个简单的图像: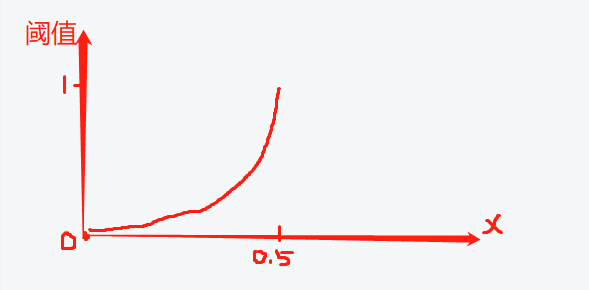 ,前提是len(str1)<len(str2),否则x会>0.5,进而导致计算阈值>1)
,前提是len(str1)<len(str2),否则x会>0.5,进而导致计算阈值>1)
大家也可以用下面的代码测试一下阈值:
import difflib
# 两个待比较的字符串
str2 = "你好,我选择的是小米品牌汽车su款,谢谢"
str1 = "小米su7" # 短的
# 创建SequenceMatcher对象
matcher = difflib.SequenceMatcher(None, str1, str2)
# 计算相似度
similarity_ratio = matcher.ratio()
print(f"相似度比率: {similarity_ratio:.2f}")
# 此示例相似度为0.32这样,就可以将上面那个复杂的流程图,简化为短短几步(需验证)
2.2.1 构想二
不使用“文本相似匹配”指令,改用n-gram匹配方式,通过将“商品名称”拆分为“商”、“品”、“名”、“称”、“商品”、“品名”、“名称”、“商品名”、“品名称“、”商品名称“几个子串,再去判断留言中包含多少个这样的子串,阈值设置就可以更加清晰(但运行速度上可能会受到影响)
收藏1



