Excel嵌入单元格的图片提取方法 收藏
收藏
评论
收藏Excel嵌入单元格的图片提取方法
恒
2024-06-06 14:05·浏览量:7183
恒
恒星
背景:
当我们Excel中的图片是嵌入单元格的时候,影刀的指令(导出单元格的图片)是无法成功提取到图片的,该指令只适合用于悬浮状态的图片。这时就需要新的方式来提取图片了。
解决思路:
如图,嵌入到单元格的图片,实际上是对应了一个公式,可以看到公式内有一个ID,或许可以从这个ID入手。
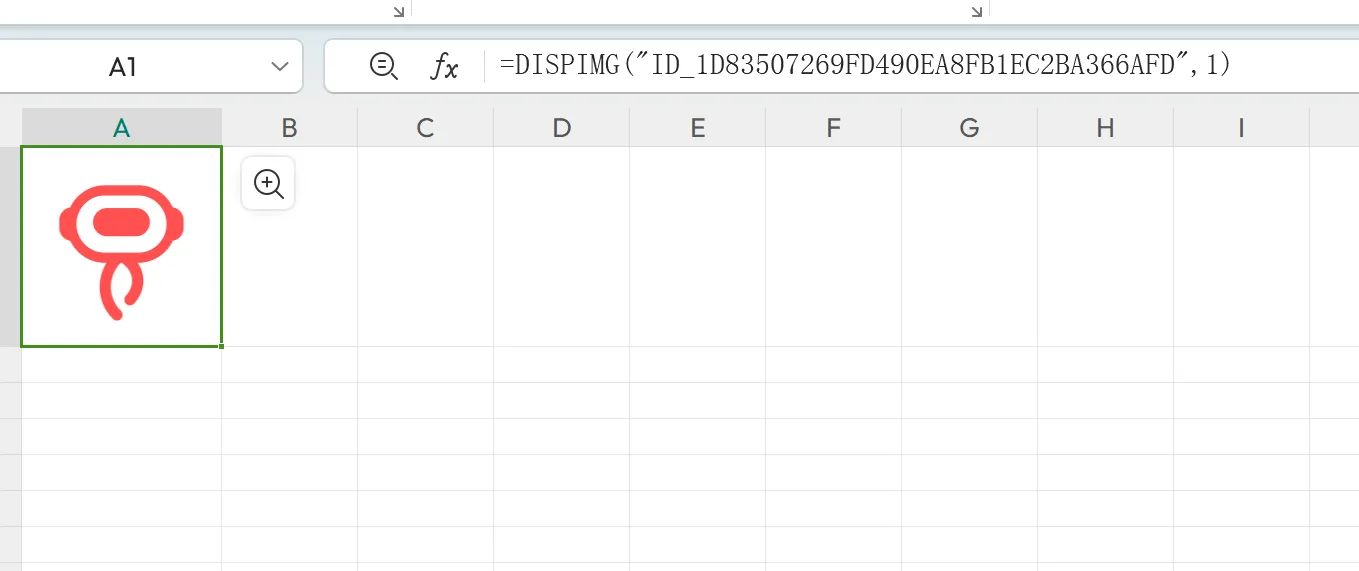
分析:
总所周知,xlsx其实是一个压缩文件,我们可以解压缩看到里面的东西。
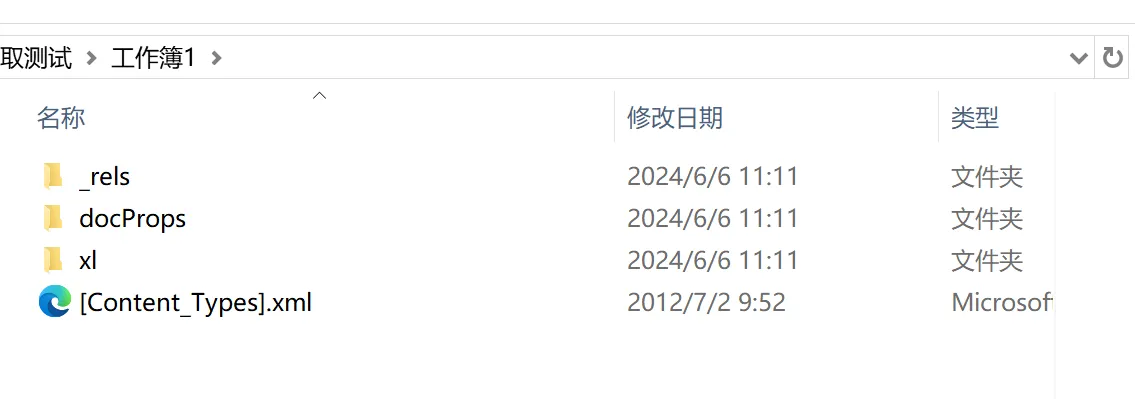
在这个路径下可以找到Excel文件内的图片文件:工作簿1\xl\media
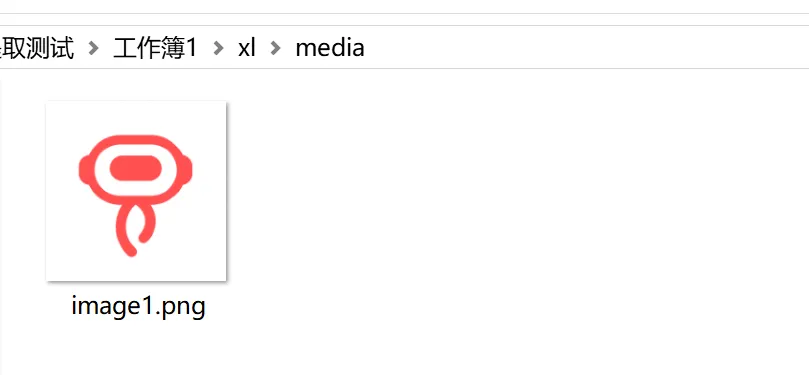
但是这里图片文件名与公式中的ID不一致,需要找到对应关系。
1、找对应关系:
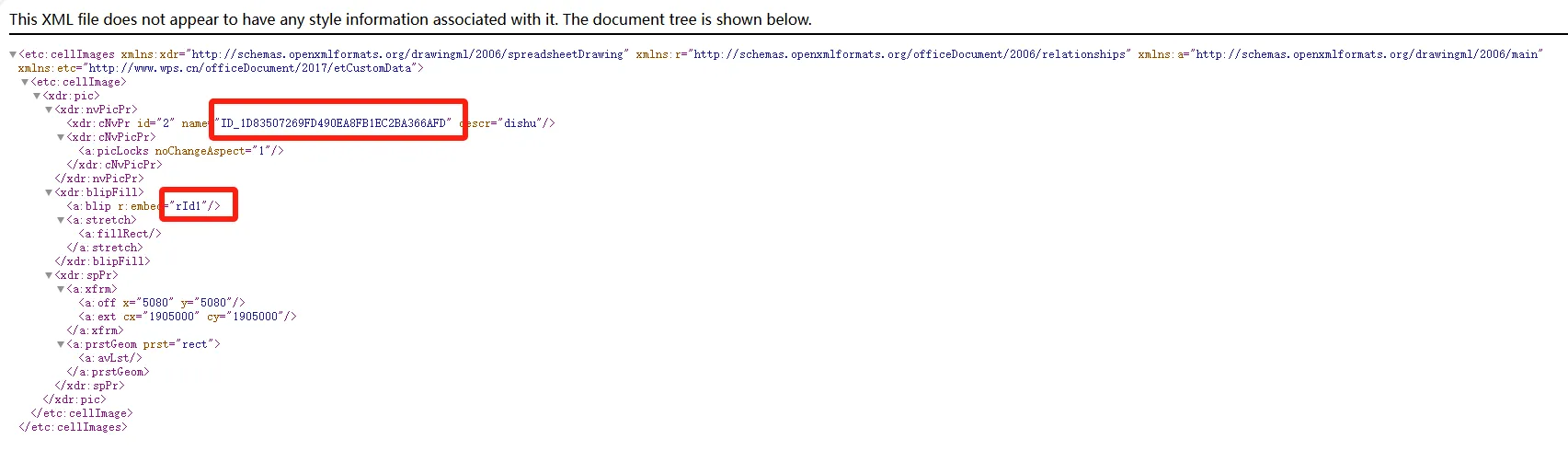
在“工作簿1\xl\cellimages.xml”这个文件里可以看到ID对应了一个rId
在“工作簿1\xl\_rels\cellimages.xml.rels”这个文件里可以看到rId对应了一个图片路径

看到这里,可以得到公式里的ID与图片路径的映射关系:ID-->rId-->图片路径
2、根据映射关系提取图片并重命名为公式中的ID
最后,用代码解析文件,获得映射关系字典,把“工作簿1\xl\media”中的图片重命名为公式中的ID,保存至一个图片文件夹内,待使用。
这样,公式与图片就直接对应上了,后续需要如何处理图片就可以很方便地操作了。
具体代码:
import os
import zipfile
import shutil
import xml.etree.ElementTree as ET
import re
"""
功能:提取xlsx文件中的图片,以ID命名,保存到指定文件夹中
参数:file_path : xlsx文件路径
save_image_path : 保存图片的文件夹路径
"""
# 创建一个临时文件夹
def create_temp_folder(path):
"""
根据传入的文件路径,在文件所在文件夹目录下创建一个临时文件夹
:param path: xlsx文件路径
:return: 临时文件夹路径
"""
temp_folder = os.path.dirname(path) + "\\临时文件夹"
try:
os.mkdir(temp_folder)
print(f"{temp_folder}文件夹创建成功。")
return temp_folder
except FileExistsError:
print(f"{temp_folder}文件夹已存在。")
return temp_folder
# 解压缩
def extract_file(file_path, target_path):
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(target_path)
return target_path
# 提取xml中第2个标签内容,生成命名空间字典
def extract_name_space(xml_path):
with open(xml_path, "r") as file:
xml_content = file.read()
pattern = r"<.*?>"
matches = re.findall(pattern, xml_content)
pattern = r'\w*?=".*?"'
name_spaces = re.findall(pattern, matches[1])
name_space = {}
for i in name_spaces:
key, value = i.split("=")
# print(key, value)
name_space[key] = value.replace('"', "")
# print(name_space)
return name_space
# 解析cellimages_xml文件中的映射关系,rID-->ID
def extract_attributes(cellimages_xml_path, namespaces):
with open(cellimages_xml_path, 'r', encoding='utf-8') as file:
xml_content = file.read()
# print(xml_content)
xml_to_dict = {}
root = ET.fromstring(xml_content)
# 查找所有的xdr:pic节点
pic_elements = root.findall('.//xdr:pic', namespaces)
for pic_element in pic_elements:
# 在每个xdr:pic内查找xdr:cNvPr节点并提取name属性
cNvPr_element = pic_element.find('.//xdr:cNvPr', namespaces)
if cNvPr_element is not None:
name = cNvPr_element.get('name')
# 同样在xdr:pic内查找a:blip节点并提取r:embed属性
blip_element = pic_element.find('.//a:blip', namespaces)
if blip_element is not None:
r_embed = blip_element.get("{" + namespaces['r'] + "}" + "embed")
xml_to_dict[r_embed] = name
# print(f"cNvPr name: {name}, a:blip r:embed: {r_embed}")
# print(xml_to_dict)
return xml_to_dict
# 解析cellimages_xml_rels文件中的映射关系,rID-->image_index
def extract_attributes_rels(cellimages_xml_rels_path, namespaces):
with open(cellimages_xml_rels_path, 'r', encoding='utf-8') as file:
xml_content = file.read()
# print(xml_content)
xml_rels_to_dict = {}
root = ET.fromstring(xml_content)
# 查找所有的Relationship节点
pic_elements = root.findall('.//xmlns:Relationship', namespaces)
for element in pic_elements:
rID = element.get('Id')
image_index = str(element.get('Target')).replace("media/image", '').replace(".png", '')
xml_rels_to_dict[rID] = image_index
# print(xml_rels_to_dict)
return xml_rels_to_dict
# 构建image_index和ID的映射关系
def creat_imageindex_to_ID_dict(xml_to_dict, xml_rels_to_dict):
imageindex_to_ID_dict = {}
for key_rID, value_ID in xml_to_dict.items():
image_index = xml_rels_to_dict[key_rID]
imageindex_to_ID_dict[image_index] = value_ID
return imageindex_to_ID_dict
# 将图片文件根据image_index和ID的映射关系重命名,并移动到指定文件夹中
def rename_move_image(imageindex_to_ID_dict, media_path, save_image_path):
# 遍历映射关系字典,重命名文件并移动
for image_index, name in imageindex_to_ID_dict.items():
image_path = media_path + "\\image" + image_index + ".png"
new_image_path = media_path + "\\" + name + ".png"
move_to_path = save_image_path + "\\" + name + ".png"
os.rename(image_path, new_image_path)
shutil.move(new_image_path, move_to_path)
print(f"{image_path}重命名并移动文件至:{move_to_path}")
# 主函数
def main(file_path, save_image_path):
'''
参数:
file_path : Excel文件路径
save_image_path : 存放图片的文件夹路径
'''
# 初始化,创建临时文件夹,将xlsx文件解压至临时文件夹中
temp_folder = create_temp_folder(file_path) # 创建临时文件夹
extract_file(file_path, temp_folder) # 解压xlsx文件
# 定义几个要用到的文件夹路径
media_path = temp_folder + "\\xl\\media" # 解压后的图片文件夹
cellimages_xml_path = temp_folder + "\\xl\\cellimages.xml" # xml文件,内有ID_与rID的映射关系
cellimages_xml_rels_path = temp_folder + "\\xl\\_rels\\cellimages.xml.rels" # xml文件,内有imageIndex_与rID的映射关系
# 提取cellimages_xml的命名空间字典
name_space = extract_name_space(cellimages_xml_path)
print("提取cellimages_xml的命名空间字典")
# 读取cellimages_xml文件,得到映射关系字典rID-->image_index
mapping_dict = extract_attributes(cellimages_xml_path, name_space)
print("读取cellimages_xml文件,得到映射关系字典rID-->image_index")
# 提取cellimages_xml_rels的命名空间字典
name_space_rels = extract_name_space(cellimages_xml_rels_path)
print("提取cellimages_xml_rels的命名空间字典")
# 读取cellimages_xml_rels文件,得到映射关系字典rID-->image_index
rID_to_image_index_dict = extract_attributes_rels(cellimages_xml_rels_path, name_space_rels)
print("读取cellimages_xml_rels文件,得到映射关系字典rID-->image_index")
# 创建image_index和ID的映射关系字典
imageindex_to_ID_dict = creat_imageindex_to_ID_dict(mapping_dict, rID_to_image_index_dict)
print("创建image_index和ID的映射关系字典")
# 重命名、移动图片文件
rename_move_image(imageindex_to_ID_dict, media_path, save_image_path)
# 删除临时文件夹
try:
shutil.rmtree(temp_folder)
print(f"{temp_folder}文件夹删除成功。")
except:
print("删除临时文件夹失败。")
if __name__ == '__main__':
file_path = r'C:\Users\10485\Desktop\excel图片提取测试\工作簿1.xlsx'
save_image_path = r'C:\Users\10485\Desktop\excel图片提取测试\图片文件夹'
main(file_path, save_image_path)
全部评论(1)
最新
发布评论
评论




