 收藏
收藏二维列表按“多列”去重:提升数据处理效率的利器
一、引言
在数据提取、分析的自动化中,经常会遇到需要对数据进行去重处理的情况,特别是在处理表格类型数据(二维)时,尽管影刀RPA也提供了“二维列表按列去重”功能,但该功能只能依据某一个字段(列)作为去重依据,而用户的实际使用场景常常更为复杂,会需要根据多个列的组合来识别和去除重复项。本文将介绍的就是一种高效的去重方法,即二维列表按“多列”去重,帮助用户提高数据处理的效率。
二、解决思路
该需求虽然没有现成的封装的指令,但好在实现的逻辑较为清晰,我选择使用“自定义Python模块”的方式解决:
1、定义函数:创建一个名为remove_duplicates的函数,它接收两个参数:一个二维列表matrix和要查重的列索引列表columns_to_check。
2、初始化数据结构:在函数内部,定义两个数据结构:
seen:一个字典,用于存储要查重列的值作为键(key),和首次出现该值组合的行索引作为值(value)。
to_delete:一个列表,用于存储需要删除的行索引。
3、遍历二维列表:使用enumerate遍历matrix的每一行,enumerate同时提供了行索引row_index和行数据row。
4、生成键值:对于每一行,根据columns_to_check指定的列索引,从当前行中提取相应的值,并将这些值组合成一个元组row_key。
5、检查重复:使用row_key作为键在seen字典中进行查找:
如果row_key已存在于seen中,说明当前行的数据在之前已经出现过,因此将当前行的索引row_index添加到to_delete列表中。
如果row_key不存在于seen中,将row_key和当前行的索引row_index作为键值对存入seen字典。
6、删除重复行:在所有行都检查完毕后,为了避免在删除过程中改变列表的索引,从to_delete列表中按从大到小的顺序遍历索引,并使用del语句删除matrix中的对应行。
7、返回结果:删除重复行后,返回更新后的matrix列表。
具体使用方法如下:
1、新建Python模块,插入以下代码:
def remove_duplicates(matrix, columns_to_check):
# 创建一个字典,用于存储要查重列的值和对应的行
seen = {}
# 记录需要删除的行
to_delete = []
# 遍历每一行
for row_index, row in enumerate(matrix):
# 检查要查重的列
row_key = tuple(row[col] for col in columns_to_check)
# 如果该行在字典中已存在,则标记为需要删除
if row_key in seen:
to_delete.append(row_index)
else:
seen[row_key] = row_index
# 从后向前删除,以避免索引越界问题
for row_index in sorted(to_delete, reverse=True):
del matrix[row_index]
return matrix
3、调用此模块,并传入要处理的二维列表和用列表存储、需要去重的多个列号(例如:[1,2,5],需点亮)
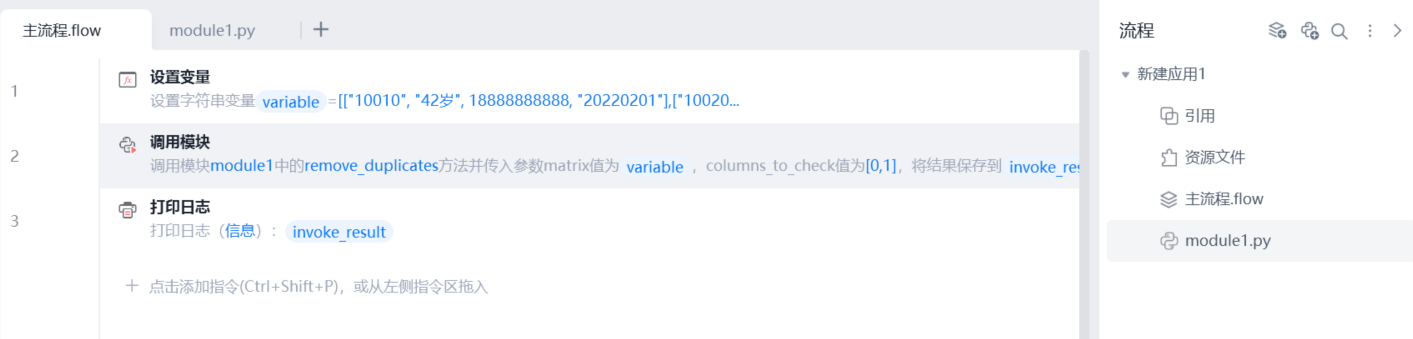
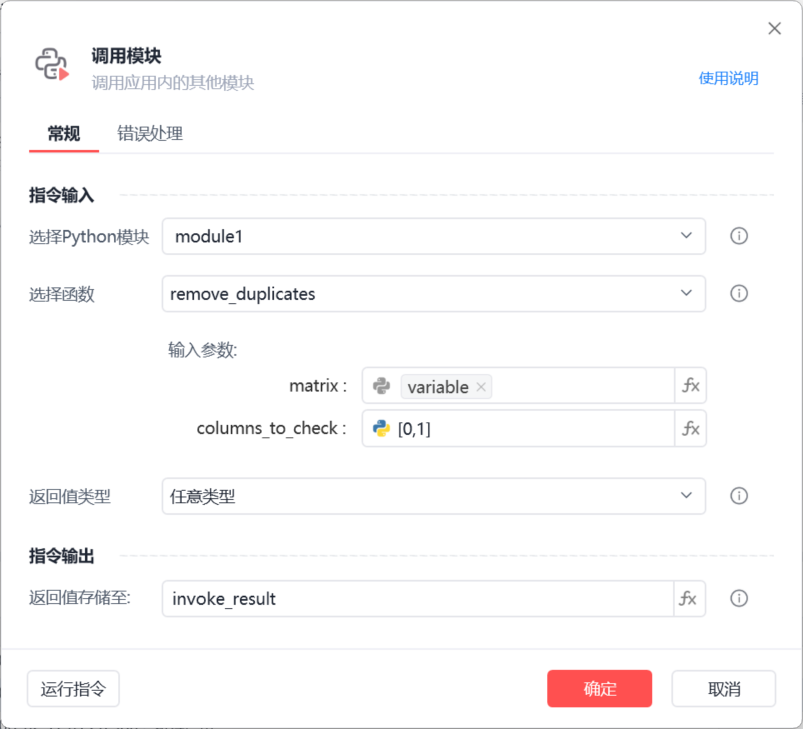
列表“多列去重”去重后的二维列表将以返回值的方式获取
结果展示:
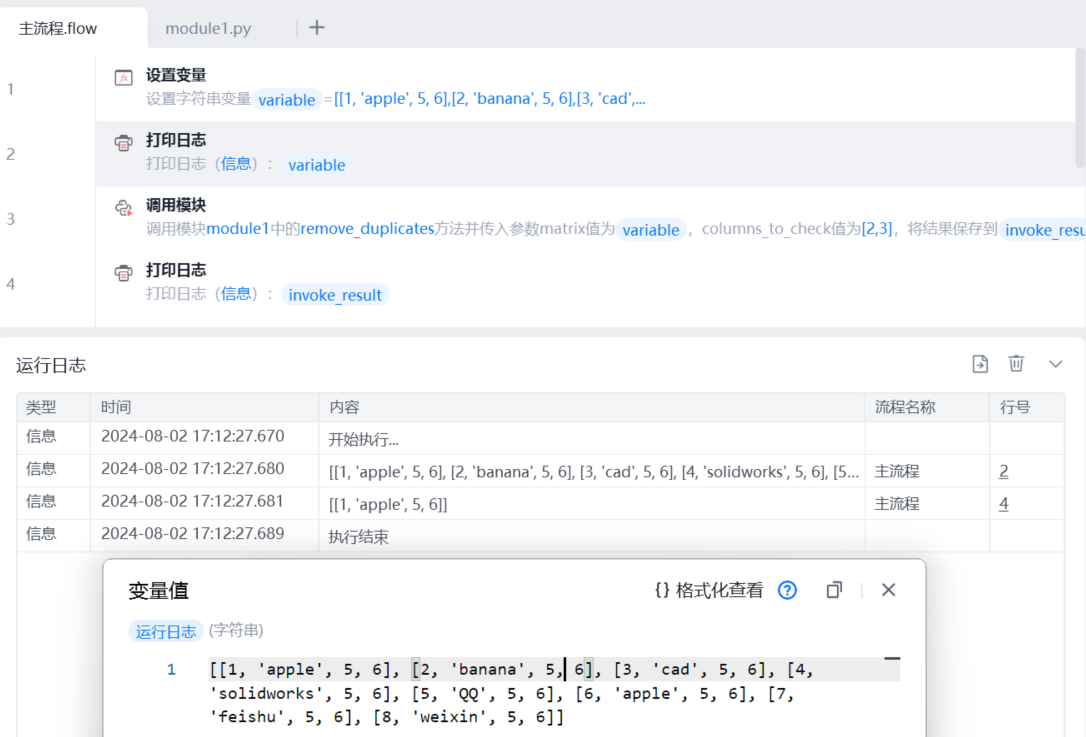
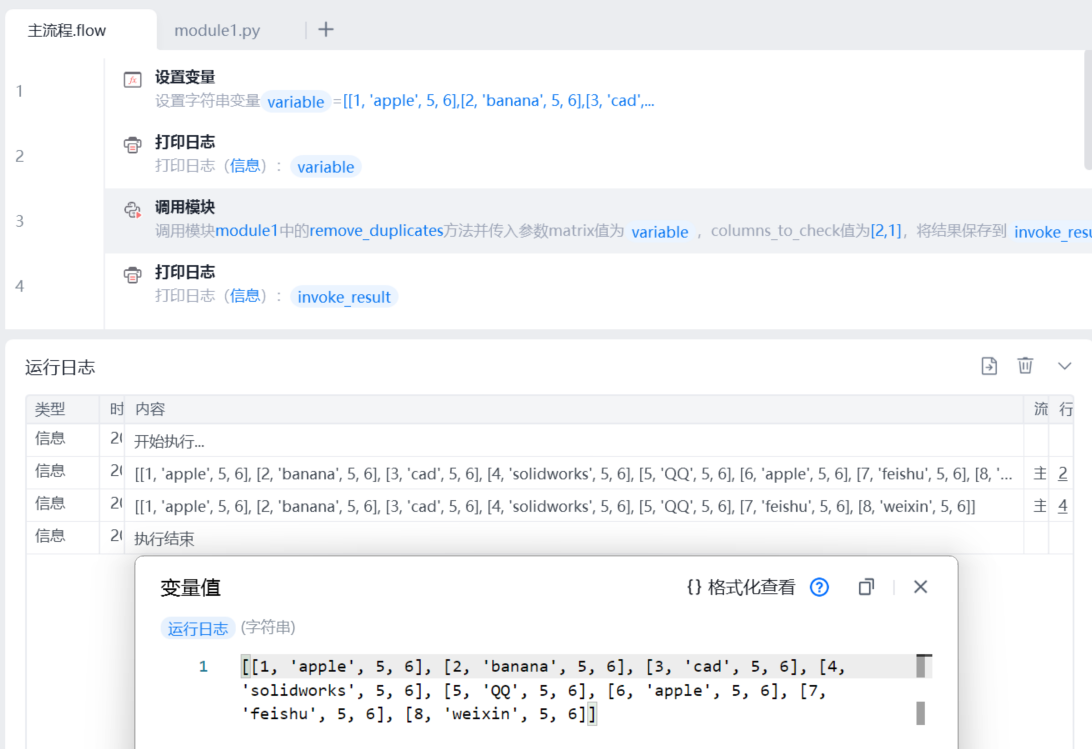
收藏3



