视频切片+文案分析(语音识别+gpt) 收藏
收藏
评论
收藏视频切片+文案分析(语音识别+gpt)

2024-07-19 11:20·浏览量:1248
土豆
背景
广告投流场景,会有短视频分析需求,不仅要做视频的切片保存还要把字幕/文案抓下来分析。在一个视频不超过1分钟的情况下,人工做需要大量的时间,这边基于前面的语音识别库做一个案例分享,可以给大家提供一个思路,详细代码我就不放了,直接复制BUG很多,有很多需要部署调试的,有兴趣的小伙伴请联系相应的技术支持~
实现流程
1.语音识别
https://www.yingdao.com/community/detaildiscuss?id=71db0d16-b9be-4aba-8725-eac933ec8117&tag=&from=userCenter&sort=createTime&page=1
https://www.yingdao.com/community/detaildiscuss?id=71db0d16-b9be-4aba-8725-eac933ec8117&tag=&from=userCenter&sort=createTime&page=1
2.视频切片
# 根据秒数截图并保存文件
def cut_video_by_seconds(vedio_file,img_out_path,img_name,seconds):
# 打开视频文件
cap = cv2.VideoCapture(vedio_file)
# 获取视频的帧率
fps = cap.get(5)
# 指定时间戳(单位:秒)
timestamp = seconds
# 计算所需帧的索引位置
frame_index = int(timestamp * fps)
# 设置视频当前帧位置
cap.set(cv2.CAP_PROP_POS_FRAMES, frame_index)
# 读取当前帧
ret, frame = cap.read()
# filename = os.path.join(img_out_path, f'{img_name}.jpg')
# cv2.imwrite(filename, frame)
# 将帧保存为图像文件
cv2.imencode('.jpg', frame)[1].tofile(f"{img_out_path}\\{img_name}.jpg")
# 释放视频对象
cap.release()
3.gpt文案分析
-影刀的gpt指令,这是最便捷的。
-影刀的ap产品
-免费的gpt,例如kimi
4.最终效果
-生成的图片,图片名是自定义的

-最终生成的excel文件
以下是保存下来的文件模板
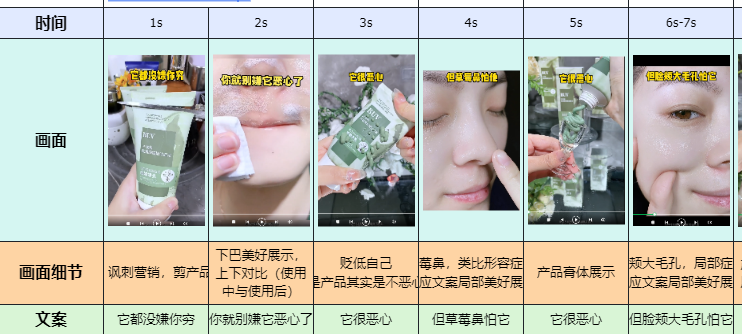
-文案分析

收藏9全部评论(1)
最新
发布评论
评论




