 收藏
收藏【元素捕获】新手学习Xpath教程总汇
前提:在RPA产品中,掌握元素捕获的技能很重要,不仅需要学完课程,还得积累经验。加上元素捕获本身是复杂且多变的,网页结构一旦变化,捕获的元素就会失效,还有的元素按照普通的捕获方法,直接捕获不到。这时候,我们不得不考虑更高级的捕获元素的方式。那么XPath无疑是最好的解决方案。
问题来了,零基础,看不懂Html?搞不清楚XPath复杂的语法结构,怎么办?
先不要慌,影刀官方给咱们准备专门的课程,建议先看完高级课程的【第一课 从头开始的HTML之旅】【第四课 XPath-定位元素的终极秘诀?】,咱们再进行实战。

XPath基本语法和定义,也可以参考菜鸟Xpath教程系统学习下
网址:https://www.runoob.com/xpath/xpath-tutorial.html
以下是我学习课程之后,我认为比较值得动手尝试下的部分笔记
(一)根据相同长辈(父级、祖先)元素定位获取元素
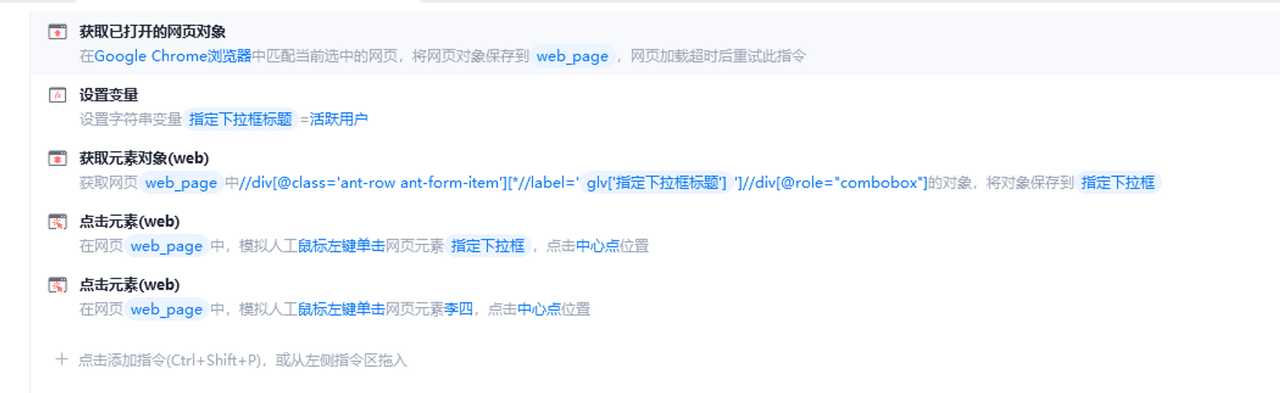
例子:通过下拉框旁边的标题文本选定定位
(1)影刀的默认获取元素方式:
思路:
(1)捕获相似元素:两个下拉框和对应的标题的祖先元素“下拉框和对应的标题_指定”,把全局变量”指定下拉框标题” 传入到元素的属性innerText中
(2)捕获下拉框相似元素组
(3)获取关联父元素”下拉框和对应的标题_指定”的下拉框元素”指定下拉框”
(4)对下拉框进行操作
(2)xpath方式:
完整的XPath表达式://div[@class='ant-row ant-form-item’][*//label='活跃用户']//div[@role='combobox']
拆解步骤:
1. 找到一个祖先元素,这个祖先元素的XPath路径是://div[@class='ant-row ant-form-item’]。
2. 祖先元素带有label文本标签为”活跃用户“,[*//label='活跃用户']
3.在找到的这个祖先元素中,继续查找后代元素中的div元素,且这个div元素具有role属性为"combobox"。这个后代div元素的XPath路径是://div[@role='combobox']。
综合起来,这个XPath表达式的作用是先找到一个特定条件的祖先元素,然后在这个祖先元素中查找符合另一个条件的后代元素。
备注:在XPath中,祖先元素指的是当前元素的所有父级元素,以及这些父级元素的父级元素,依此类推,直到文档根节点。
实操案例:
1、获取label名称为“下拉框”的对象
XPath表达式
//div[@class='ant-row'][3]/div[@class='ant-col ant-col-12'][*//label='下拉框']//span[@class="ant-form-item-children"]/select
2.获取下拉框,文本为“香蕉”的选项
根据位置
//div[@class="ant-form-item-control"]//select//option[3]
根据文本
//div[@class="ant-form-item-control"]//select//option[text()="苹果"]
完整流程:
暂缺
3.如何用XPath定位网页弹窗实战
//*[contains(@class,"close")]//ancestor::div[not(contains(@placeholder,"请输入"))]/*[contains(@class,"close")]

//*[contains(@data-testid,"close")]/ancestor::div[not(contains(@placeholder,"请输入"))]/*[contains(@data-testid,"close")]
自己尝试的小案例:
//*[contains(@data-testid,"beast-core-modal-icon-close")]
(二)手机Xpath
手机XPath教程:https://www.bilibili.com/video/BV1ZV4y1v7z1/?p=3&vd_source=ec9af2c01d92fd325b92f67f94527cc5
(三)XPath轴
以下是XPath中常用的一些轴:
- child(子节点轴):选取当前节点的所有子元素节点。
- parent(父节点轴):选取当前节点的父节点。
- ancestor(祖先节点轴):选取当前节点的所有祖先节点(父、祖父等)。
- descendant(后代节点轴):选取当前节点的所有后代节点(子、孙等)。
- following-sibling(后续同级节点轴):选取当前节点之后的所有同级节点。
- preceding-sibling(前序同级节点轴):选取当前节点之前的所有同级节点。
- following(后续节点轴):选取文档中当前节点的结束标签之后的所有节点。
- preceding(前序节点轴):选取文档中当前节点的开始标签之前的所有节点。
以下是一些XPath轴的用法示例:
假设我们有以下简单的XML文档结构:
现在我们来举例说明如何使用XPath中的轴来选择不同类型的节点:
- child(子节点轴):选取当前节点的所有子元素节点。例如,/bookstore/book/child::title 会选取所有book元素的子元素title。
- parent(父节点轴):选取当前节点的父节点。例如,/bookstore/book/title/parent::book 会选取title元素的父节点book。
- ancestor(祖先节点轴):选取当前节点的所有祖先节点(父、祖父等)。例如,/bookstore/book/title/ancestor::bookstore 会选取title元素的祖先节点bookstore。
- descendant(后代节点轴):选取当前节点的所有后代节点(子、孙等)。例如,/bookstore/descendant::title 会选取bookstore元素的所有后代元素title。
- following-sibling(后续同级节点轴):选取当前节点之后的所有同级节点。例如,/bookstore/book[1]/following-sibling::book 会选取第一个book元素之后的所有同级book元素。
- preceding-sibling(前序同级节点轴):选取当前节点之前的所有同级节点。例如,/bookstore/book[2]/preceding-sibling::book 会选取第二个book元素之前的所有同级book元素。
- following(后续节点轴):选取文档中当前节点的结束标签之后的所有节点。例如,/bookstore/book[1]/title/following::author 会选取第一个book元素中title元素之后的所有节点author。
- preceding(前序节点轴):选取文档中当前节点的开始标签之前的所有节点。例如,/bookstore/book[2]/author/preceding::title 会选取第二个book元素中author元素之前的所有节点title。
补充的学习资料:
网页中通过xpath,说明文档链接
https://www.yingdao.com/yddoc/language/zh-cn/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98/%E7%BD%91%E9%A1%B5%E8%87%AA%E5%8A%A8%E5%8C%96%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98/%E7%BD%91%E9%A1%B5%E4%B8%AD%E9%80%9A%E8%BF%87xpath%E5%AE%9A%E4%BD%8D%E5%85%83%E7%B4%A0.html?
XPath课程完整文档:
https://zhuanlan.zhihu.com/p/697606107
xpath&影刀日常场景元素捕获
https://www.yingdao.com/community/detaildiscuss?id=993ff3e2-306e-43c4-a292-e847de406a3a
菜鸟Xpath教程
https://www.runoob.com/xpath/xpath-tutorial.html
【牛刀小试】
影刀商城:https://shop.yingdao.com/list/table-list
收藏11



