关于WPS的EXCEL表格中,获取嵌入的单元格图片的分享 收藏
收藏
评论
收藏关于WPS的EXCEL表格中,获取嵌入的单元格图片的分享
楚
2024-06-13 11:05·浏览量:3013
楚
楚子风
思路来源于csdn的贴子
贴子地址: java poi 获取excel中的图片(包含wps中嵌入单元格图片)
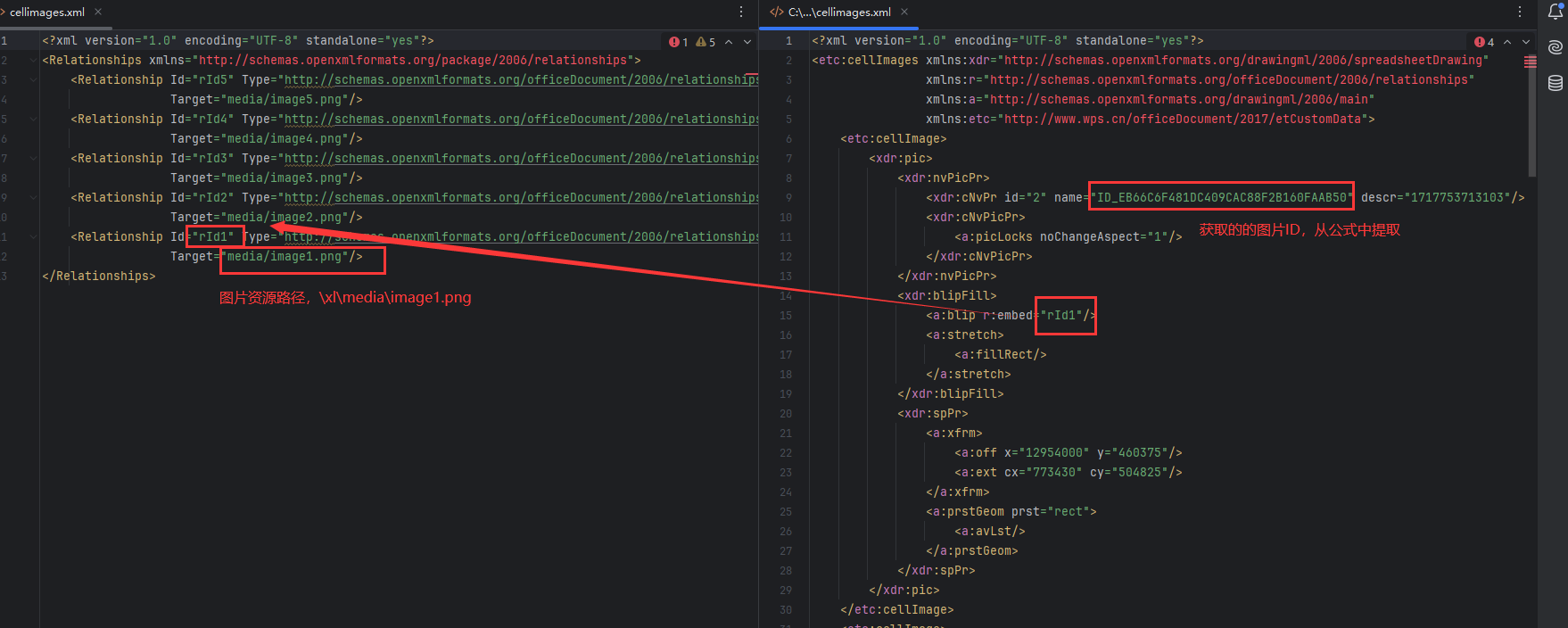
- 先把excel作为zip读取
- 获取\xl\cellimages.xml的内容,找出图片ID对应的r:embed
- 获取\xl\_rels\cellimages.xml.rels 找出r:embed对应的图片资源路径 Target
- 复制Target路径的图片到指定路径
附上Python代码:
# -*- coding: utf-8 -*-
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import xml.etree.ElementTree as ET
import zipfile
import os
import xml.etree.ElementTree as ET
import shutil
import re
from xbot import excel
def 从excel提取嵌入图片(关键词, excel路径, 图片保存路径,临时路径):
try:
# 使用正则表达式检查关键词格式
pattern = r'=DISPIMG\("([^"]+)"\,\d+\)'
match = re.match(pattern, 关键词)
if not match:
raise ValueError("关键词格式不正确")
# 提取图片ID
图片ID = match.group(1)
# 解压Excel文件
with zipfile.ZipFile(excel路径, 'r') as zip_ref:
zip_ref.extractall(临时路径)
# 获取XML文件路径
xml文件路径 = os.path.join(临时路径, 'xl', 'cellimages.xml')
# 获取关系文件路径
关系文件路径 = os.path.join(临时路径, 'xl', '_rels', 'cellimages.xml.rels')
# 解析嵌入XML文件,提取嵌入ID列表
命名空间_embed = {
'xdr': 'http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing',
'a': 'http://schemas.openxmlformats.org/drawingml/2006/main',
}
tree_embed = ET.parse(xml文件路径)
root_embed = tree_embed.getroot()
嵌入ID列表 = [pic.find('.//a:blip', 命名空间_embed).get(
'{http://schemas.openxmlformats.org/officeDocument/2006/relationships}embed')
for pic in root_embed.findall('.//xdr:pic', 命名空间_embed)
if pic.find('.//xdr:cNvPr[@name="{}"]'.format(图片ID), 命名空间_embed) is not None]
# 解析关系XML文件,获取目标路径
命名空间_relations = {'rels': 'http://schemas.openxmlformats.org/package/2006/relationships'}
tree_relations = ET.parse(关系文件路径)
root_relations = tree_relations.getroot()
目标路径 = {关系元素.get('Id'): 关系元素.get('Target')
for 关系元素 in root_relations.findall('.//rels:Relationship', 命名空间_relations)}
图片路径 = os.path.join(临时路径, "xl", 目标路径[嵌入ID列表[0]])
shutil.copy(图片路径, 图片保存路径)
# 删除临时解压文件夹
shutil.rmtree(临时路径)
print(目标路径[嵌入ID列表[0]])
return 目标路径[嵌入ID列表[0]]
except Exception as e:
print("发生错误:", e)
# 删除临时解压文件夹
shutil.rmtree(临时路径)
return None
def 从excel批量提取嵌入图片(关键词列表, excel路径, 图片保存路径, 临时路径):
try:
# 解压Excel文件
print(关键词列表)
with zipfile.ZipFile(excel路径, 'r') as zip_ref:
zip_ref.extractall(临时路径)
for 关键词 in 关键词列表:
# 检查关键词格式
if not isinstance(关键词, str) or not 关键词.startswith('=DISPIMG("ID_') or not 关键词.endswith('",1)'):
print(f"关键词格式不正确或不是字符串: {关键词}")
continue
# 提取图片ID
图片ID = 关键词[10:45]
# 获取XML文件路径
xml文件路径 = os.path.join(临时路径, 'xl', 'cellimages.xml')
# 获取关系文件路径
关系文件路径 = os.path.join(临时路径, 'xl', '_rels', 'cellimages.xml.rels')
# 解析嵌入XML文件,提取嵌入ID列表
命名空间_embed = {
'xdr': 'http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing',
'a': 'http://schemas.openxmlformats.org/drawingml/2006/main',
}
tree_embed = ET.parse(xml文件路径)
root_embed = tree_embed.getroot()
嵌入ID列表 = [pic.find('.//a:blip', 命名空间_embed).get(
'{http://schemas.openxmlformats.org/officeDocument/2006/relationships}embed')
for pic in root_embed.findall('.//xdr:pic', 命名空间_embed)
if pic.find('.//xdr:cNvPr[@name="{}"]'.format(图片ID), 命名空间_embed) is not None]
# 解析关系XML文件,获取目标路径
命名空间_relations = {'rels': 'http://schemas.openxmlformats.org/package/2006/relationships'}
tree_relations = ET.parse(关系文件路径)
root_relations = tree_relations.getroot()
目标路径 = {关系元素.get('Id'): 关系元素.get('Target')
for 关系元素 in root_relations.findall('.//rels:Relationship', 命名空间_relations)}
图片路径 = os.path.join(临时路径, "xl", 目标路径[嵌入ID列表[0]])
shutil.copy(图片路径, 图片保存路径)
# 删除临时解压文件夹
shutil.rmtree(临时路径)
print(f"成功提取图片: {图片保存路径}")
return True
except Exception as e:
print("发生错误:", e)
# 删除临时解压文件夹
shutil.rmtree(临时路径)
return False
def main(args):
pass
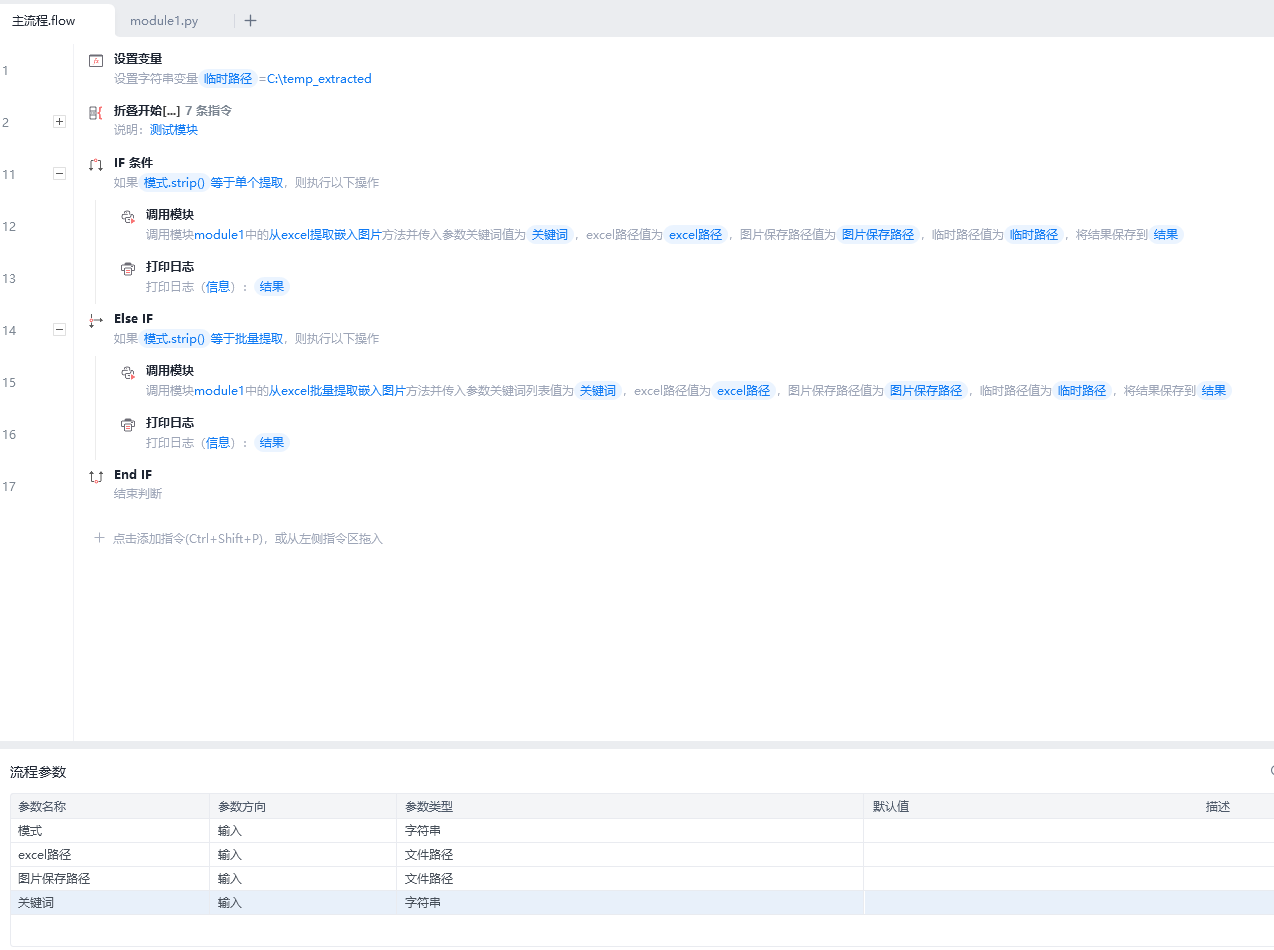
代码写的比较丑陋,大佬勿喷
收藏2全部评论(1)
最新
发布评论
评论




