飞书云文档知识库多层级表格信息读取(代码+影刀指令) 收藏
收藏
评论
收藏飞书云文档知识库多层级表格信息读取(代码+影刀指令)

2024-08-19 17:26·浏览量:2107
土豆
一、背景
飞书使用的体验还是相当不错的,用户量也多起来了。作为企业信息管理重要一环的知识库,飞书也集成了非常多的接口,那么如何获取各个空间和空间下的文件呢?以下用代码结合影刀指令来操作知识库里面的表格作为演示
二、需求
空间下有多个电子表格,电子表格的子级也有多个文件,都需要读取其中的内容
三、实现过程
3.1 接口代码
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
def main(args):
pass
import requests
import json
# 获取tenant_access_token
def get_tenant_token(app_id,app_secret):
url = f"https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
payload = {
"app_id": app_id ,
"app_secret":app_secret
}
headers = {
'Content-Type': 'application/json; charset=utf-8'
}
response = requests.request("POST", url, headers=headers, data = json.dumps(payload))
# 检查响应
if response.status_code == 200:
# print('请求成功:', response.text)
return json.loads(response.text)["tenant_access_token"]
else:
print('请求失败:', response.status_code)
# 获取知识库空间列表,得到space_id
def get_wiki_list(tenant_access_token):
url = "https://open.feishu.cn/open-apis/wiki/v2/spaces"
payload={}
headers = {
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("GET", url, headers=headers, data=payload)
# 检查响应
if response.status_code == 200:
# print('请求成功:', response.text)
return json.loads(response.text)["data"]["items"]
else:
print('请求失败:', response.status_code)
# 获取知识库空间内目录(文件/文件夹),得到父级的node_token(用来请求子级)
# 如果本身是个文件(表格/文档),要读取文件的内容,使用obj_token
def get_wiki_folder(tenant_access_token,space_id):
url = f"https://open.feishu.cn/open-apis/wiki/v2/spaces/{space_id}/nodes"
payload={}
headers = {
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("GET", url, headers=headers, data=payload)
# 检查响应
if response.status_code == 200:
# print('请求成功:', response.text)
return json.loads(response.text)["data"]["items"]
else:
print('请求失败:', response.status_code)
# 获取父文件(文件夹)的所有子文件(文件夹)丢node_token
def get_wiki_child(tenant_access_token,folder_token):
url = f"https://open.feishu.cn/open-apis/drive/v1/files?folder_token={folder_token}"
payload={}
# payload={
# folder_token:folder_token
# }
headers = {
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("GET", url, headers=headers, data=payload)
# 检查响应
if response.status_code == 200:
# print('请求成功:', response.text)
return json.loads(response.text)["data"]["files"]
else:
print('请求失败:', response.status_code)
# 替换为自己的id和secret,后续有影刀代码的实现过程
# app_id = "cli_a***607b900b"
# app_secret ="XGyn5hbS***HL5B38Ld"
# tenant_access_token = get_tenant_token(app_id,app_secret)
# print(tenant_access_token)
# 用其中一个知识库表格文件来测试
# space_id = get_wiki_list(tenant_access_token)[0]["space_id"]
# print(space_id)
# folder_token_list = get_wiki_folder(tenant_access_token,space_id)
# # print(folder_token_list)
# # 用其中一个知识库表格文件来测试
# folder_node_token = folder_token_list[1]["node_token"]
# print(folder_node_token)
# # 得到所有子文件信息,下一步做读取信息操作,用得到的token可以结合影刀gpt指令使用
# child_list = get_wiki_child(tenant_access_token,folder_node_token)
# print(child_list)3.2 影刀实现
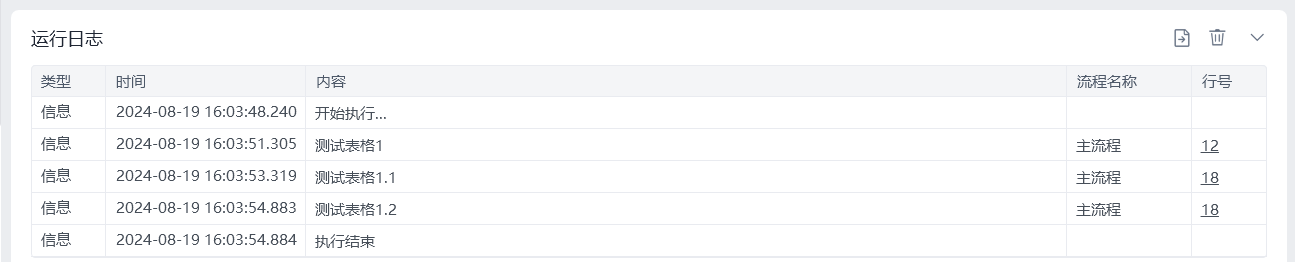
3.2.1 实现效果
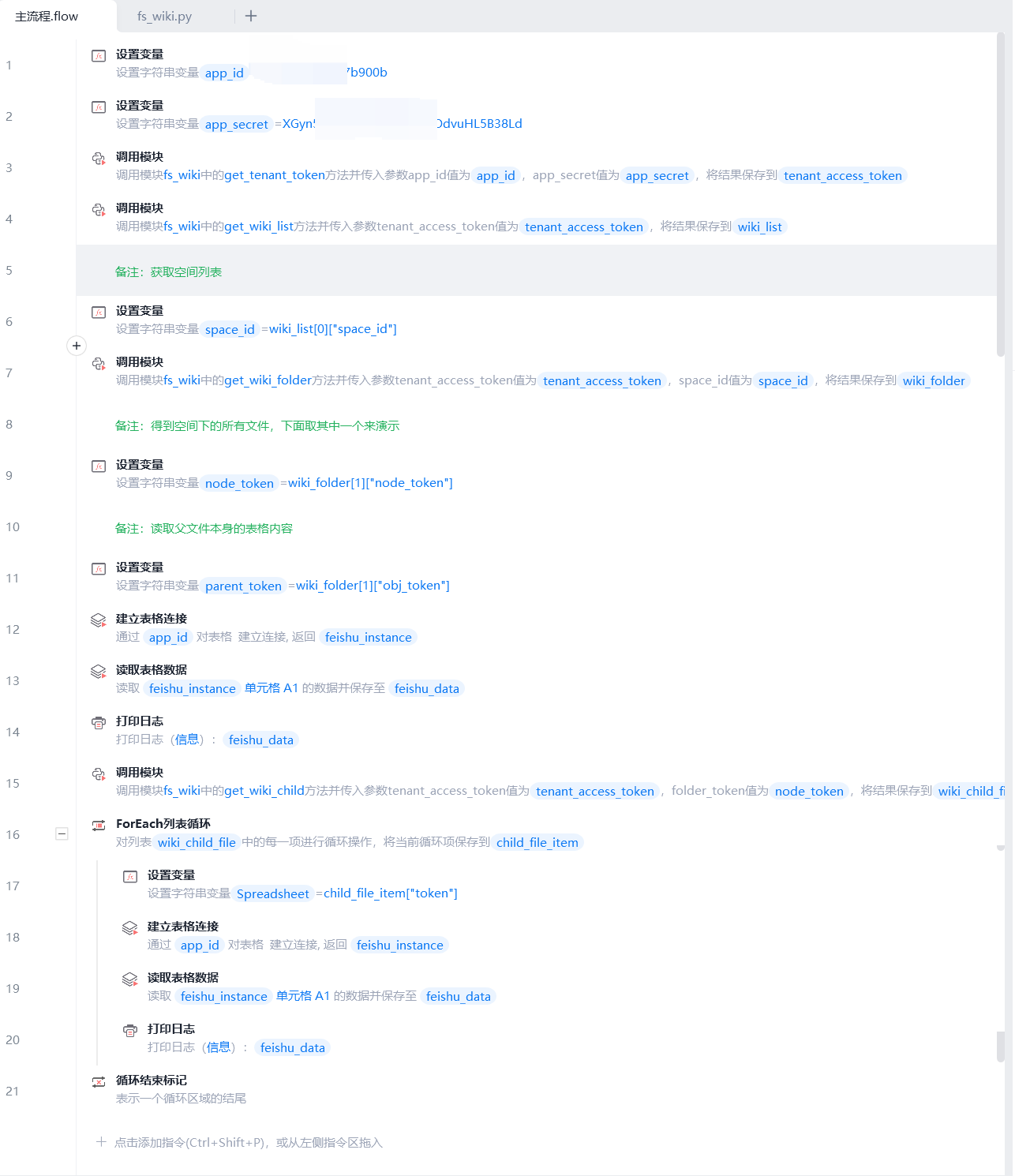
3.2.2 代码截图
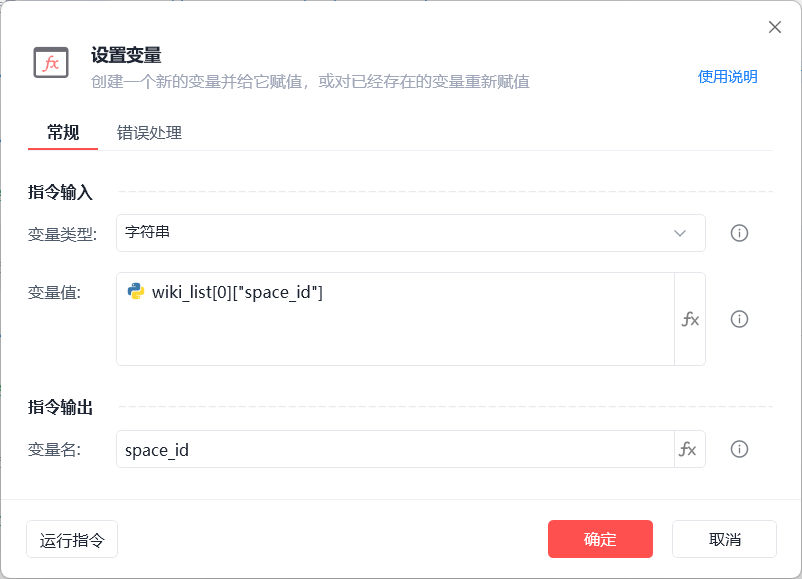
3.2.3 关键代码截图
以下这几个变量本质都是列表,我取了其中一个出来演示,实际使用可以根据业务来调整
- 获取其中一个空间id的变量设置wiki_list[0]["space_id"]
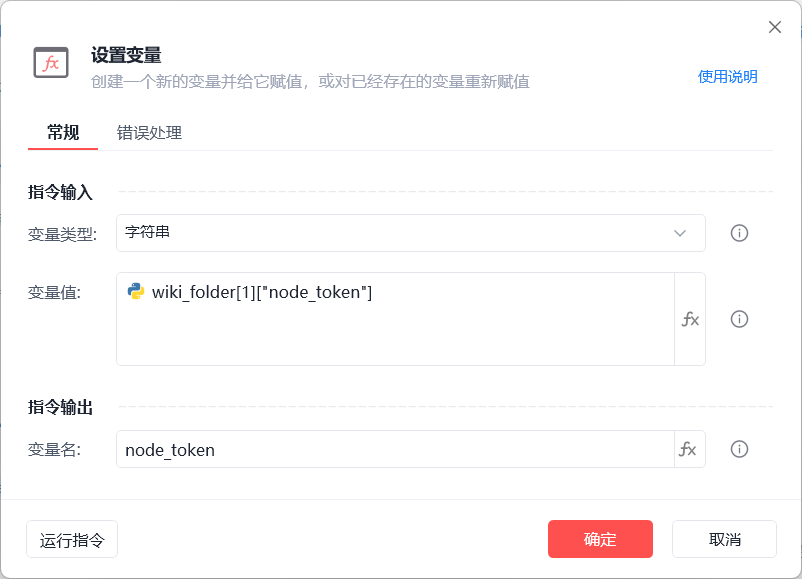
- 获取空间下其中一个文件演示wiki_folder[1]["node_token"]
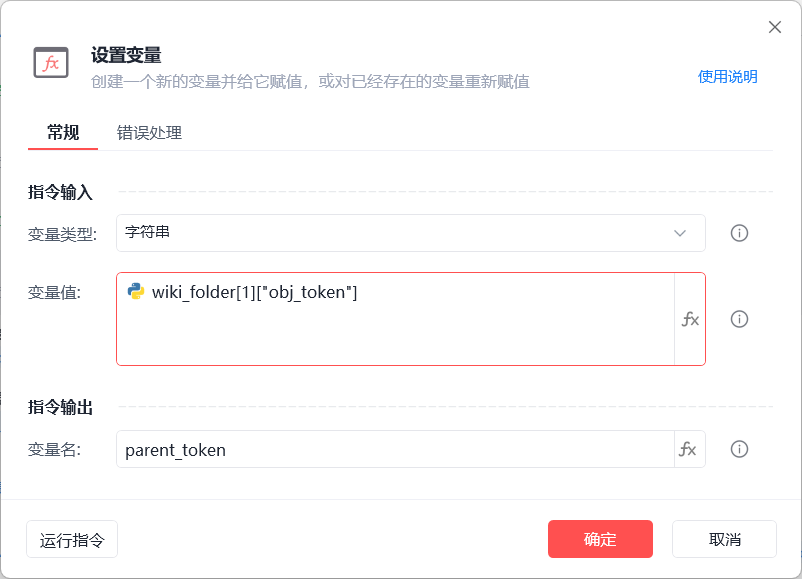
- 读取父文件本身的内容wiki_folder[1]["obj_token"]
四、飞书配置
4.1 官方文档
https://open.feishu.cn/document/server-docs/docs/wiki-v2/wiki-overview
https://open.feishu.cn/document/server-docs/docs/wiki-v2/wiki-overview
4.2 配置关键点
4.2.1 给应用配置相应权限
wiki:wiki
wiki:wiki.readonly
4.2.2 给应用添加机器人能力并添加到知识库管理员
https://open.feishu.cn/document/server-docs/docs/wiki-v2/wiki-qa
https://open.feishu.cn/document/server-docs/docs/wiki-v2/wiki-qa
收藏2全部评论(1)
最新
发布评论
评论




