 收藏
收藏NO.033-你迟早会遇到~记录天猫店铺价格界面解密的全过程!——By.杭州组
作者:云潮
关键词:文字加密,字体库加密
一、问题背景
对于资讯服务类网站或者电商网站来说,数据是核心资产,就像大众点评,58 同城,天猫,药房网这样的网站。如何防止数据被批量窃取,也就成了这些网站永恒的话题。本文我以天猫为例,聊聊它 Web 端的加密手段:字体库加密。重点谈谈以下几点内容。
- 什么是字体库加密?
- 什么是字形和字符编码?
字体库加密
字体库加密是一种通过使用 CSS 自定义字体,使得页面源码中的数据与显示出来的数据不同的一种加密方式。其原理很简单,改变字体库中文字的字符编码,使得文字无法解析,达到加密的效果。页面显示的时候,使用自定义的字体库文件,文字显示正常。
直观点,我们打开天猫网站,随便找一个店铺,查看店铺的商品信息,我们发现,页面上显示的商品价格和我们在控制台看到的地址不一致。
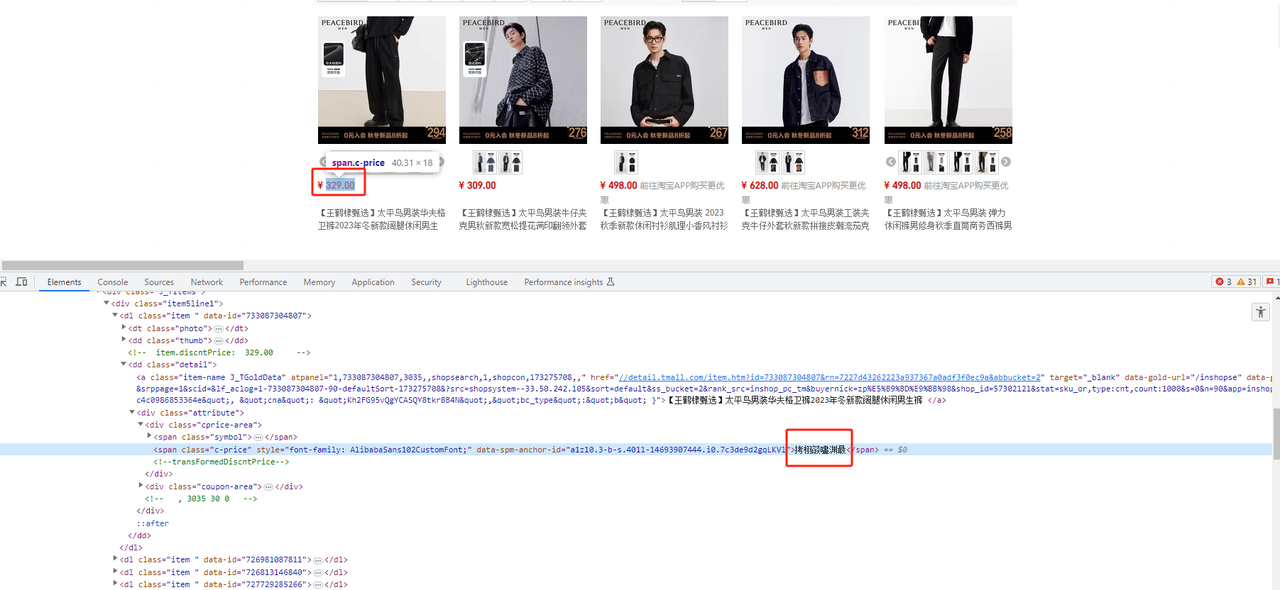
这就是字体库加密的作用。通过影刀去捕获元素,然后获取元素信息,获得数据明显错误,甚至是乱码。
那么,天猫是如何做到这一点的呢?
字形和字符编码
我们从头来看,一个文字是如何显示在页面上的呢?我们在 CSS 中定义了字体库,页面会按照CSS的内容去加载字体库。
<style type="text/css">
@font-face {
font-family: 'AlibabaSans102CustomFont';
src: url('https://webfontcdn.taobao.com/webfont/1f489de8-e9bc-4d96-93de-f475686639ab7375358770356543788.woff') format("woff");
}
</style>接下来的问题就是,字体库中有什么?
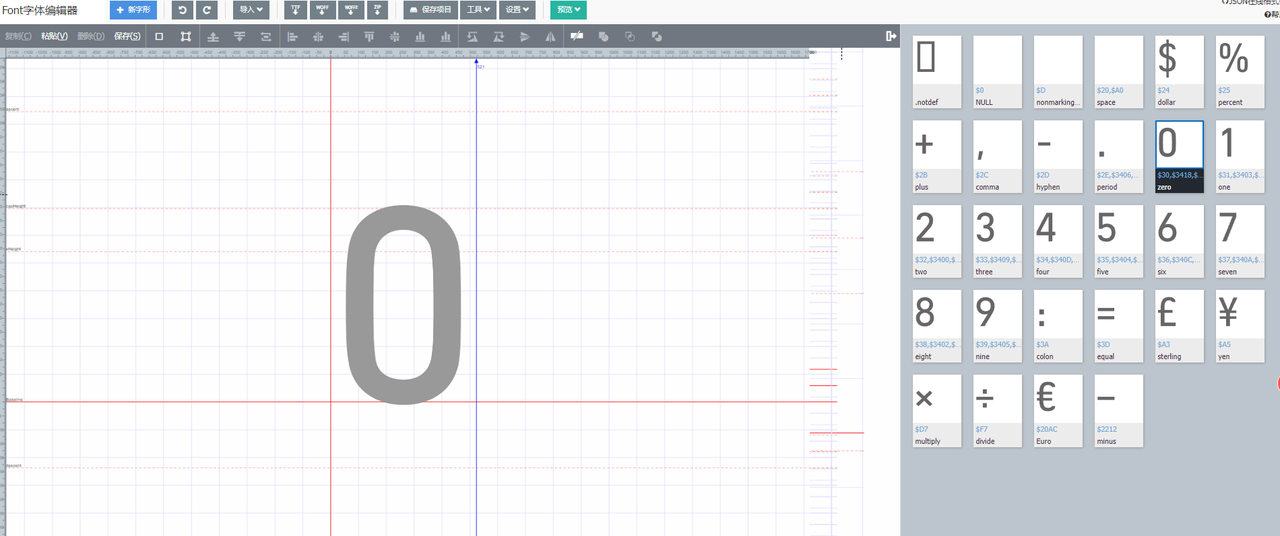
一个文字可以分为字形和字符编码,字形就是这个文字长什么样子,字符编码就是这个文字的唯一编码,用来索引这个文字。字体库就是一系列文字的字形和字符编码的集合。根据字形的不同风格形成了不同的字体,比如宋体,楷体,隶书等等。我们可以通过FontEditor字体编辑器网站查看这些字体文件的字形和编码,如下是 “0” 在AlibabaSans102CustomFont中的字形。
详细了解字体加密原理可以参考前端反爬小技巧之字体库加密
二、实现步骤
示例网址:太平鸟男装旗舰店
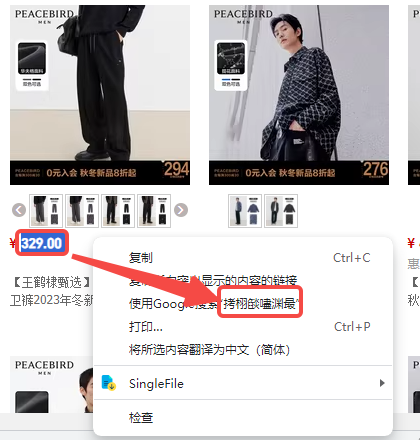
通过复制发现天猫店铺的价格数字只能通过肉眼看见,复制以后会乱码,我们打开控制台查看
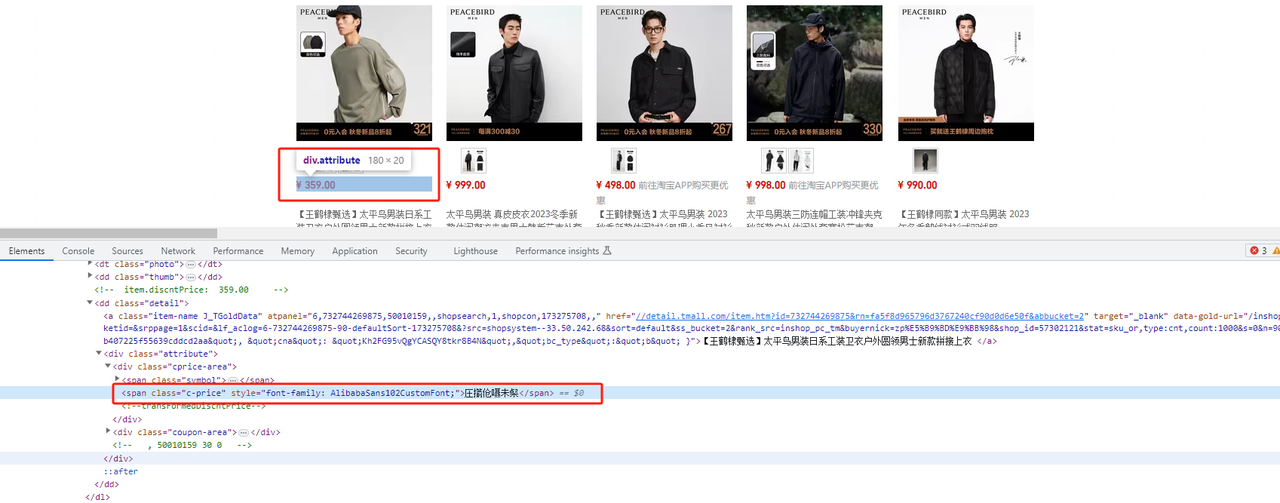
控制台显示也是乱码,同时发现该乱码文字指定了font-family: AlibabaSans102CustomFont字体去显示,所以想要获取正确的文本内容,我们需要获取AlibabaSans102CustomFont字体中的文字的字形和字符编码对应关系。
1.直接复制字体名称去搜索,发现该字体通过CSS加载,我们可以通过字体的url把字体文件下载到本地。

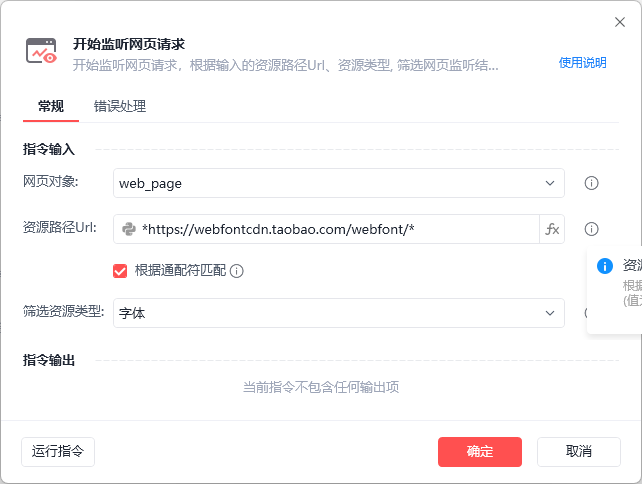
如何通过影刀去下载这个字体呢,我们可以通过网页监听实现,先获取需要监听的url
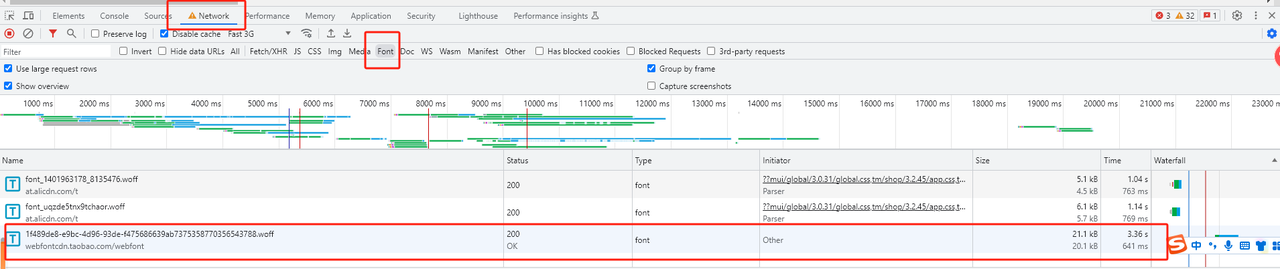
在影刀中的流程如下

关键指令截图
2.拿到字体文件以后接下来我们需要找到字形与编码的对应关系
先用字体编辑器打开字体文件

我们发现虽然该字体的字数比较少,但是单个字形对应的编码个数实在是太多了,无法手动去构建这个映射关系。
为了更好的找出字形与编码的对应关系,我们先通过fontTools把woff文件转成xml文件
from fontTools.ttLib import TTFont
font = TTFont(r"C:\Users\yd666\Desktop\1f489de8-e9bc-4d96-93de-f475686639ab7375358770356543788.woff")
xml = font.saveXML(r"C:\Users\yd666\Desktop\1f489de8-e9bc-4d96-93de-f475686639ab7375358770356543788.xml")xml文件如下:
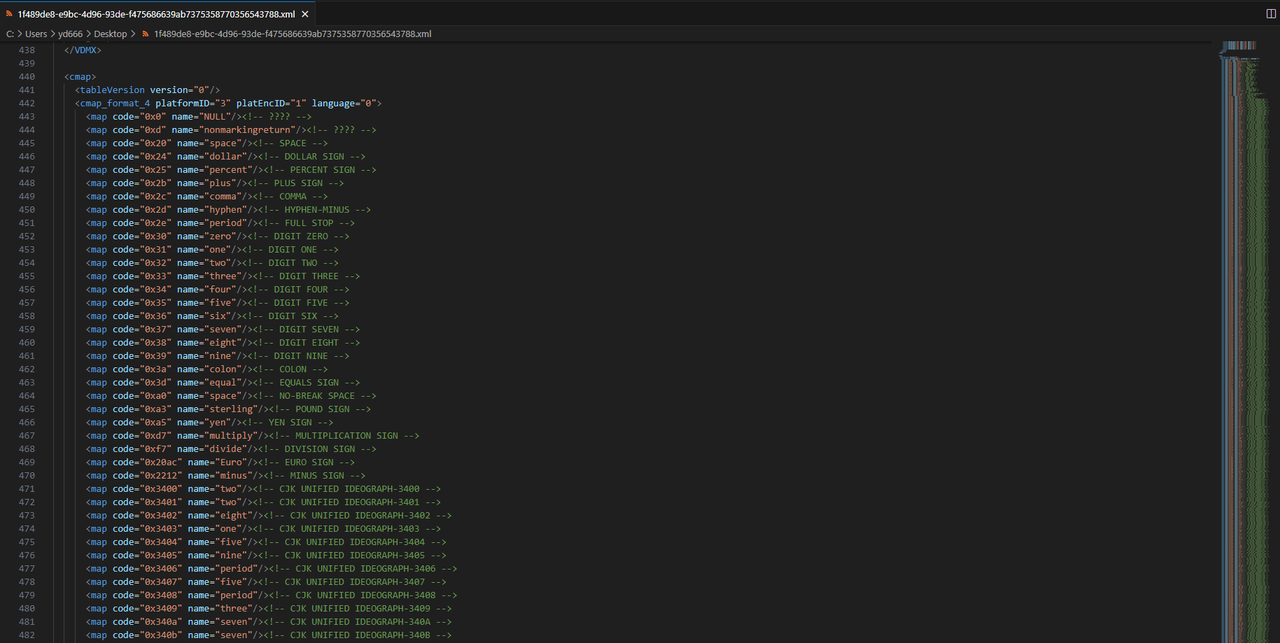
<map code="0x30" name="zero"/><!-- DIGIT ZERO -->
通过观察我们发现在一个map节点中,code的值就是编码,name的值是字形对应的英文,我们只要构建一个数字跟英文对应的字典即可。
获取解密的字典{编码:字形文字}def decode_dict(font_path):
number_dict = {
'zero': "0",
'one': "1",
'two': "2",
'three': "3",
'four': "4",
'five': "5",
'six': "6",
'seven': "7",
'eight': "8",
'nine': "9",
"period":".",
"comma":","
}
font = TTFont(font_path)
# 获取Cmap字典
cmap_order = font["cmap"].getBestCmap()
#print(type(cmap_order))
#根据cmap的规律生成对应的解密字典
new_dict = { key: number_dict[value] for key, value in cmap_order.items() if value in number_dict.keys()}
#print(new_dict)
return new_dictord() 是一个内置函数,通常在编程语言中使用,用于返回给定字符的Unicode码点(code point)。
获取解密字典以后,我们通过ord()函数获取乱码文字的unicode编码,然后去解密字典中找到对应的文字
def decode_text(web_element_attribute,decode_dict):
list_text=[]
for i in web_element_attribute:
code=ord(i)
name=decode_dict[code]
list_text.append(name)
return "".join(list_text)完整流程:
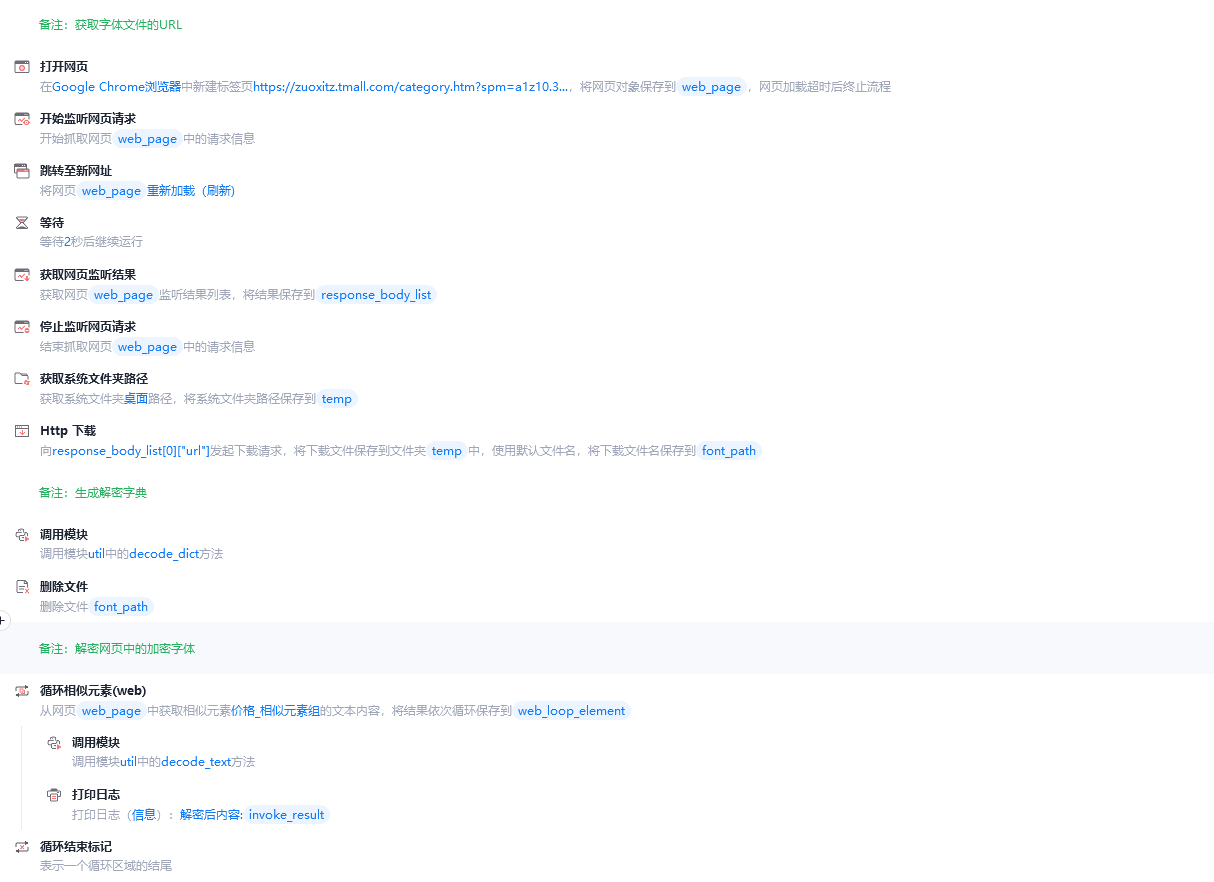
三、实现效果
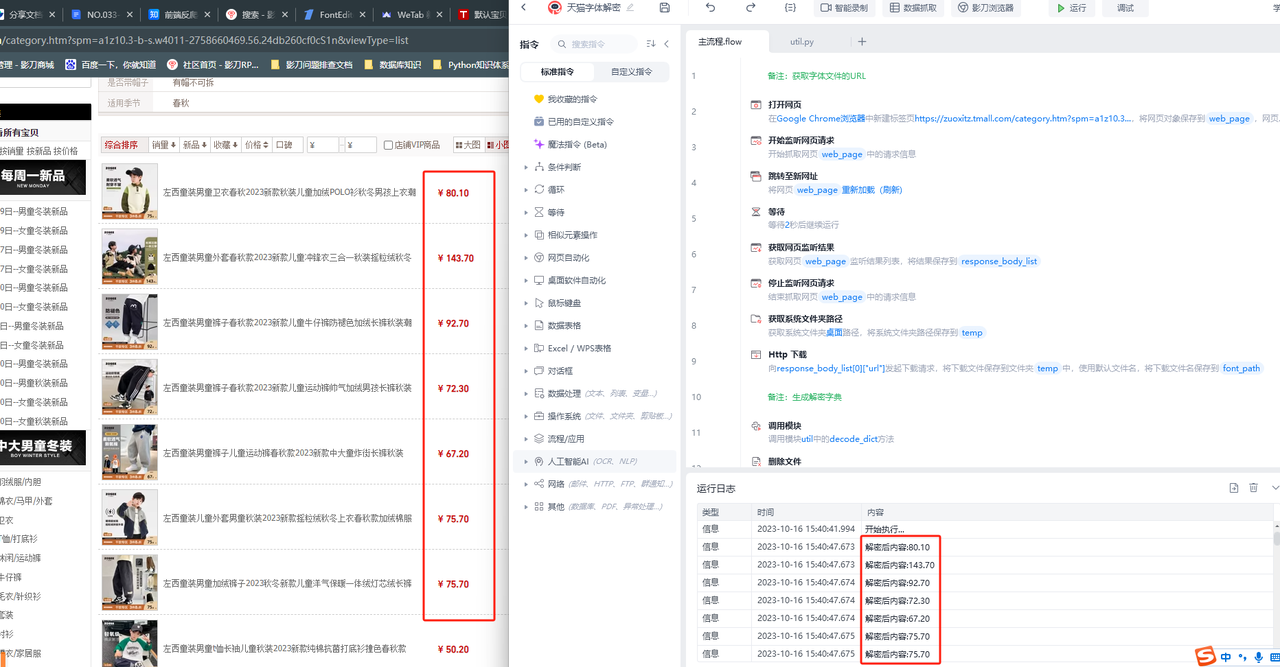
收藏25



