 收藏
收藏【即是过客】《XPath合集002》XPath 函数与操作符 —— 从入门到精通:全面掌握网页元素定位技术


 影刀专家
影刀专家 影刀认证工程师发布于 2025-07-21 11:12更新于 2025-07-21 12:122078浏览
影刀认证工程师发布于 2025-07-21 11:12更新于 2025-07-21 12:122078浏览
上期内容:【即是过客】《XPath合集001》XPath 基本语法 —— 从入门到精通:全面掌握网页元素定位技术
XPath 函数与操作符详解(结合影刀RPA实战)
XPath(XML Path Language)是一种用于在XML和HTML文档中查找节点的查询语言。在影刀RPA自动化流程中,XPath常用于网页元素定位,帮助RPA精准抓取数据或操作UI元素。
本文将详细介绍XPath的常用函数、操作符、字符串处理和数值运算,并结合影刀RPA的实际应用场景,提供图文示例和练习题,帮助你快速掌握XPath的核心用法。
1. 常用XPath函数
(1) contains():检查字符串是否包含指定内容
功能:判断一个字符串是否包含另一个字符串。
语法:contains(string, substring)
示例:
//span[contains(text(), '影刀')]解释:选择所有文本内容包含“影刀”的 <div> 元素。
影刀RPA应用场景:
- 在网页中查找包含“影刀RPA”关键词的标题或按钮。
图文示例:
contains()示例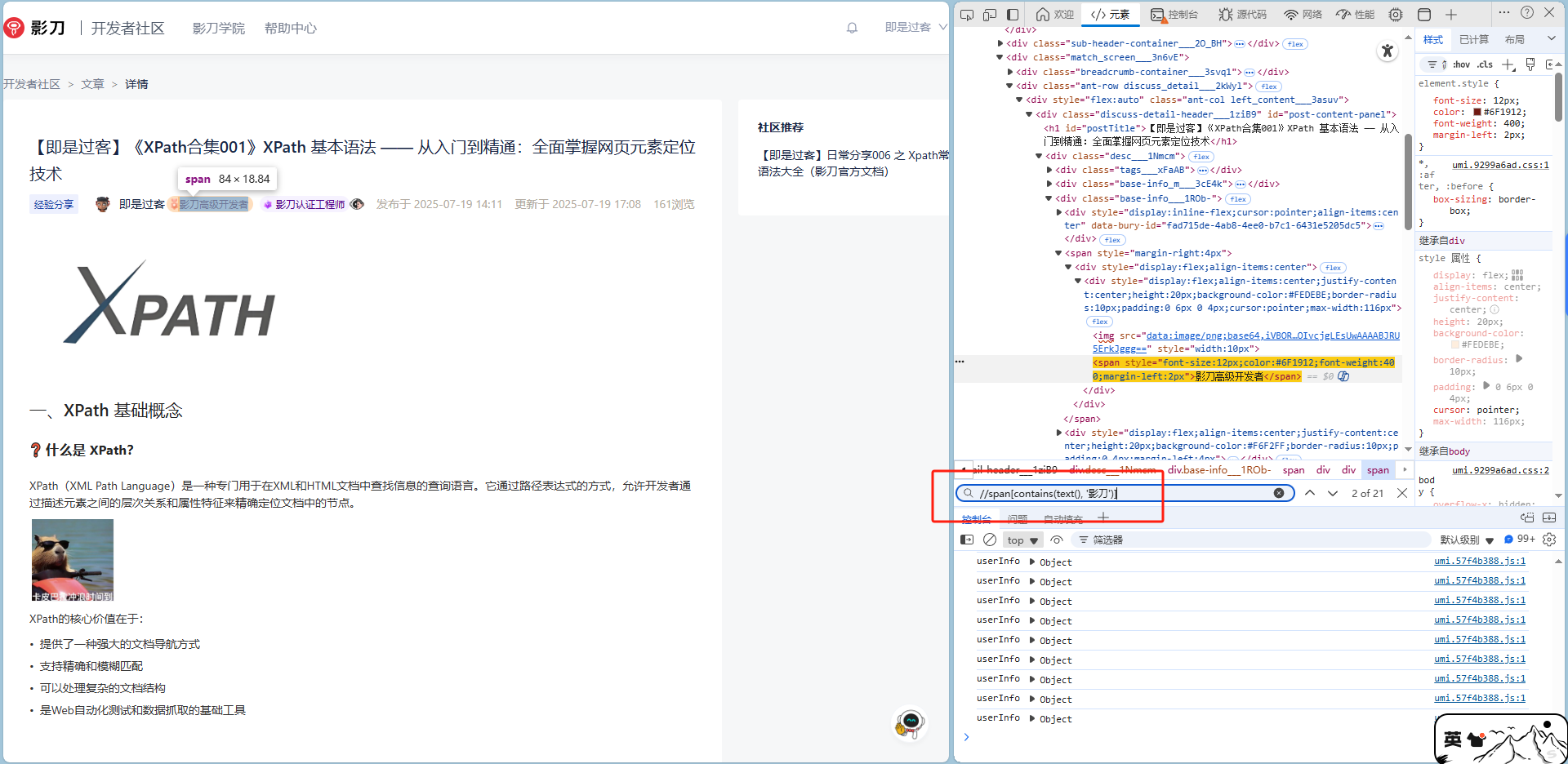
(假设网页中有多个 <span>,其中部分包含“影刀”,XPath会精准匹配这些元素。)
(2) starts-with():检查字符串是否以指定内容开头
功能:判断一个字符串是否以另一个字符串开头。
语法:starts-with(string, prefix)
示例:
//a[starts-with(@href,'https://')]解释:选择所有 href 属性以“ https://”开头的 <a> 元素(即所有HTTPS链接)。
影刀RPA应用场景:
- 在网页中筛选所有外部链接(如“ https://”开头的URL)。
- 查找以特定前缀开头的文本(如“订单-”开头的订单号)。
图文示例:
starts-with()示例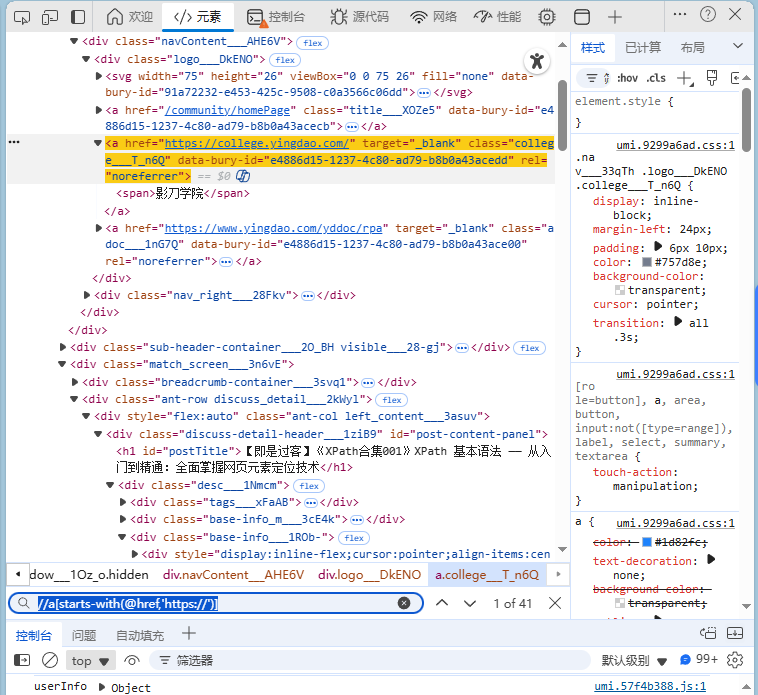
(假设网页中有多个链接,XPath会匹配所有以“ https://”开头的URL。)
(3) text():获取元素的文本内容
功能:选择元素的纯文本内容(不包括HTML标签)。
语法://element[text()='xxx']
示例:
//div[text()='编辑']解释:选择文本内容为“提交”的 <div> 元素。
影刀RPA应用场景:
- 在网页表单中定位“提交”按钮。
- 在表格中查找特定文本的单元格。
图文示例:
text()示例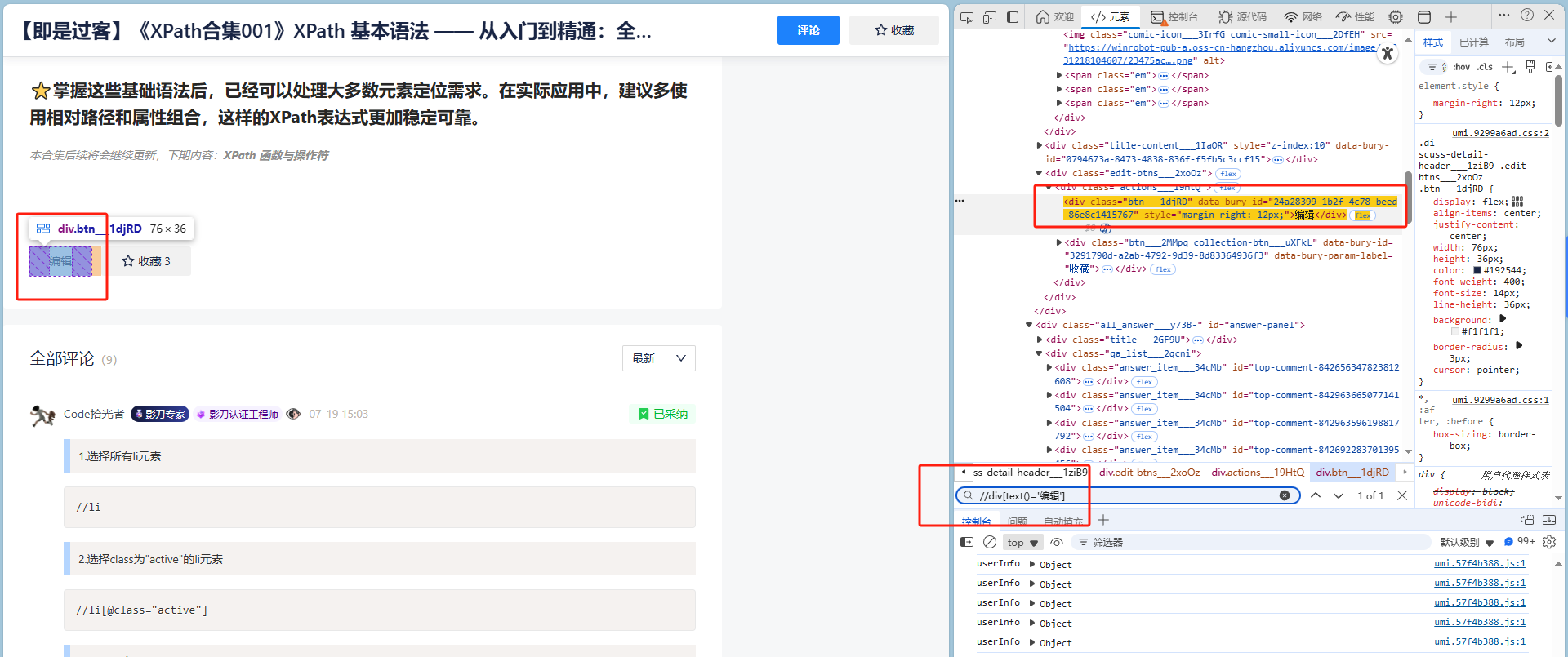
(假设网页中有多个 <div>,XPath会精准匹配“编辑”按钮。)
(4) count():计算节点数量
功能:统计符合条件的节点数量。
语法:count(//element)
示例:
count(//img)解释:计算文档中所有 <img> 元素的数量。
影刀RPA应用场景:
- 统计网页中某个区块的元素数量(如商品列表项数)。
- 判断某个表格是否有数据(如
count(//tr) > 0)。
图文示例:
count()示例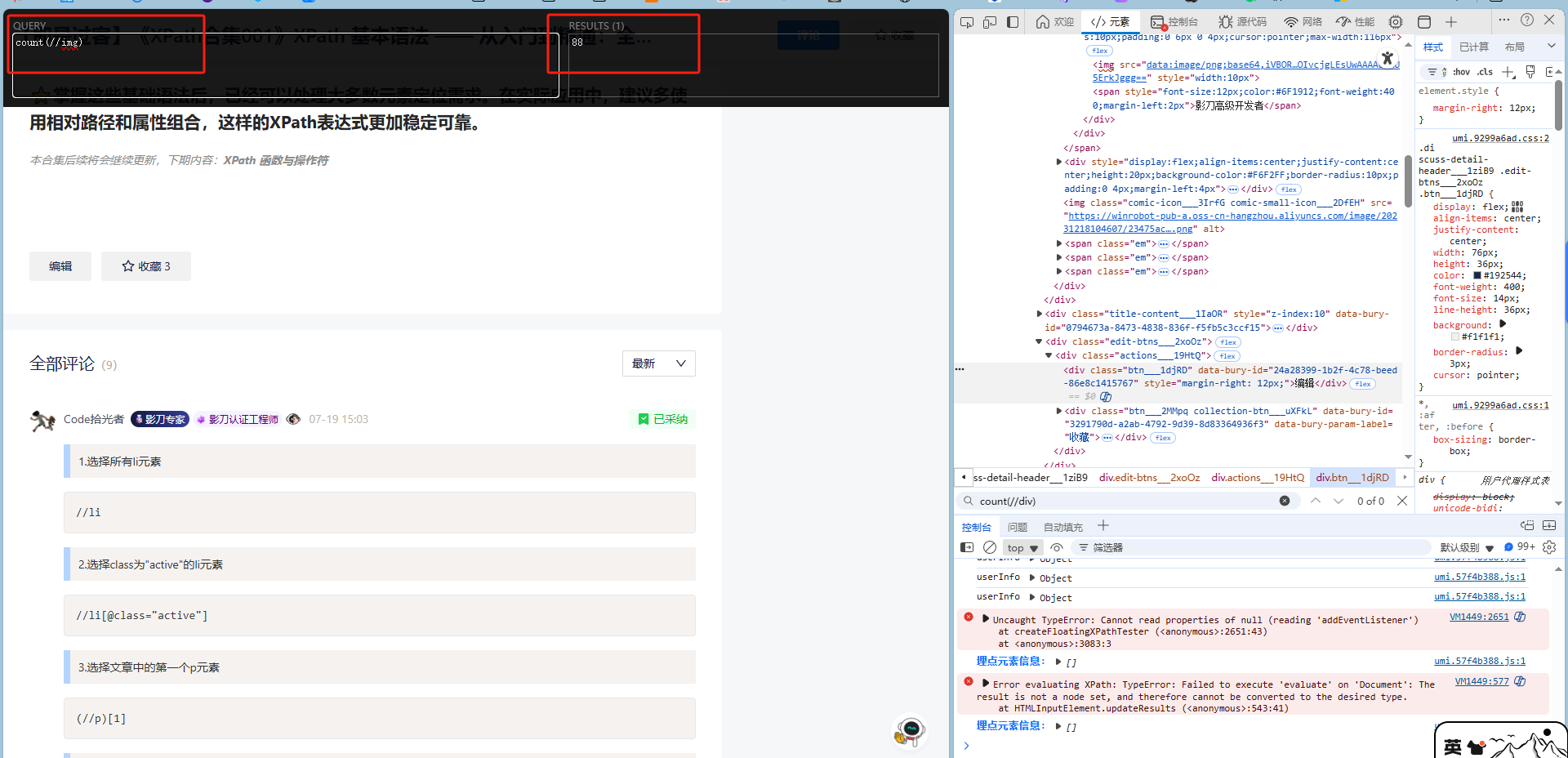
(假设网页中有88个 <img>,XPath会返回数字88。)
2. XPath操作符
(1) and:逻辑与(所有条件必须满足)
功能:组合多个条件,所有条件必须为真时,整个表达式才为真。
语法://element[@attr1='value1' and @attr2='value2']
示例:
//h1[@id="postTitle" and contains(text(),"XPath合集")]解释:选择 id 为“postTitle”且 文本包含“XPath合集”的 <h1> 元素。
影刀RPA应用场景:
- 在登录表单中精准定位“用户名”输入框(避免误选其他输入框)。
- 在表格中筛选同时满足多个条件的行(如“状态=已完成”且“优先级=高”)。
图文示例:
and操作符示例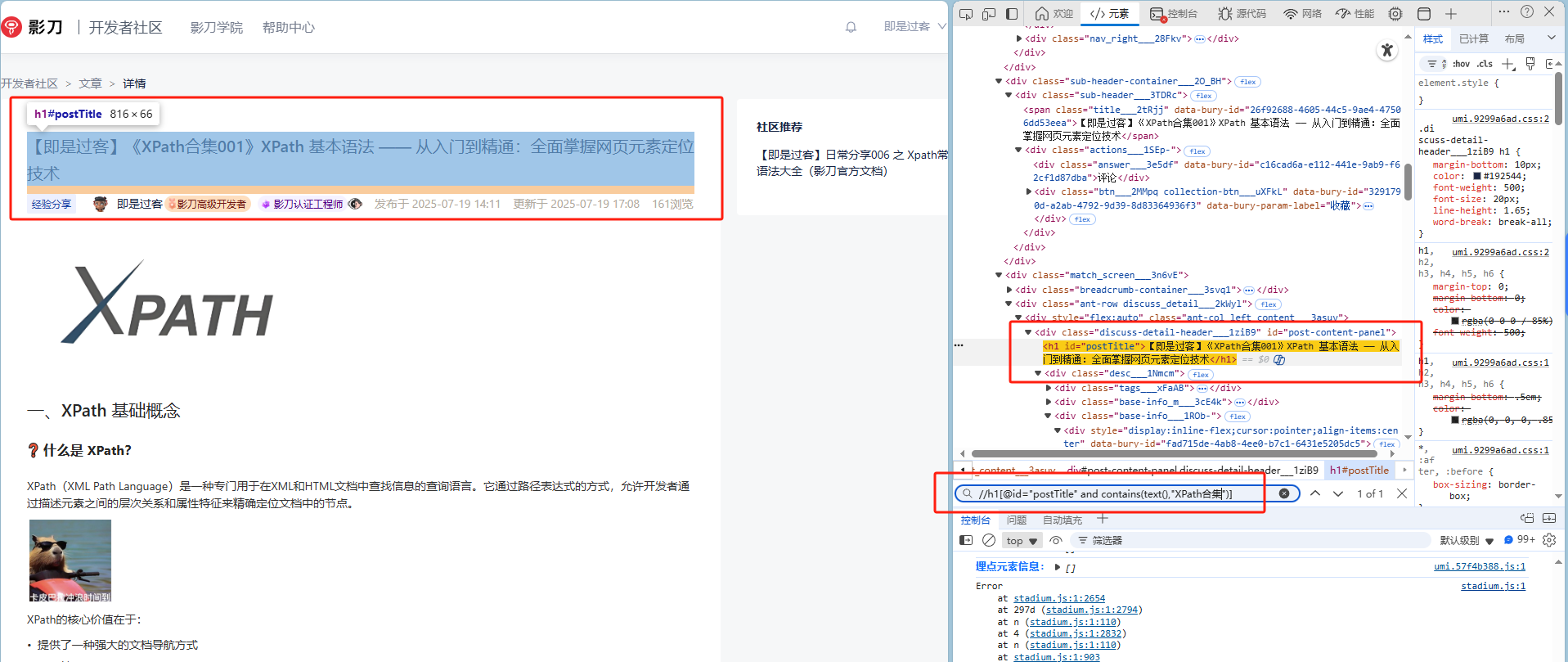
(假设网页中有多个 <h1>,XPath会精准匹配符合条件的元素。)
(2) or:逻辑或(满足任意一个条件即可)
功能:组合多个条件,只要有一个条件为真,整个表达式就为真。
语法://element[@attr1='value1' or @attr2='value2']
示例:
//span[text()="影刀高级开发者" or text()="影刀认证工程师"]解释:选择 span 文本为“影刀高级开发者”或“影刀认证工程师”的 <span> 元素。
影刀RPA应用场景:
- 在网页中匹配不同样式的按钮(如“主要按钮”和“次要按钮”)。
- 在表格中筛选满足任意一个条件的行(如“状态=已完成”或“状态=待审核”)。
图文示例:
or操作符示例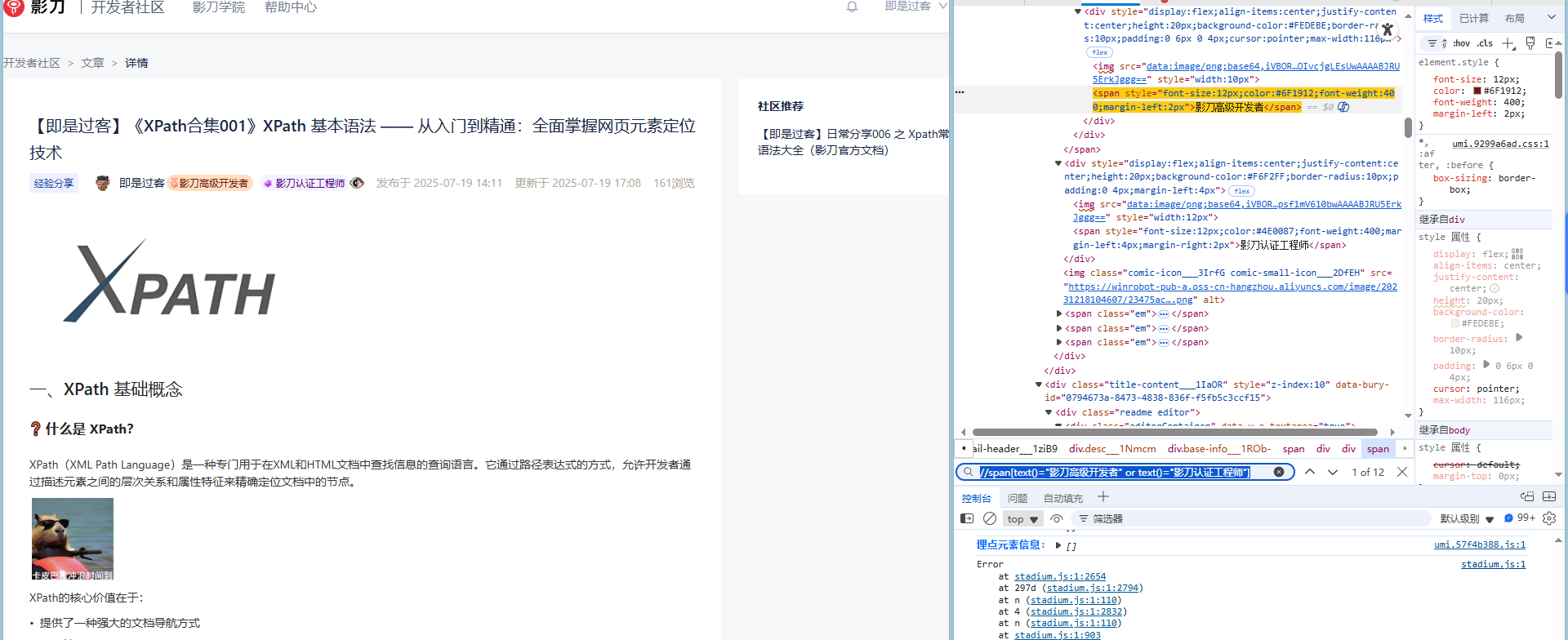
(假设网页中有多个 <span>,XPath会匹配符合条件的span元素。)
(3) not():逻辑非(排除符合条件的节点)
功能:排除满足条件的节点。
语法://element[not(@attr='value')]
示例:
//a/span[not(text()="影刀学院")]解释:选择a标签下 文本 不为“影刀学院”的 <span> 元素。
影刀RPA应用场景:
- 在网页中排除隐藏元素(如“display:none”的元素)。
- 在表格中筛选未标记为“已删除”的数据行。
图文示例:
not()操作符示例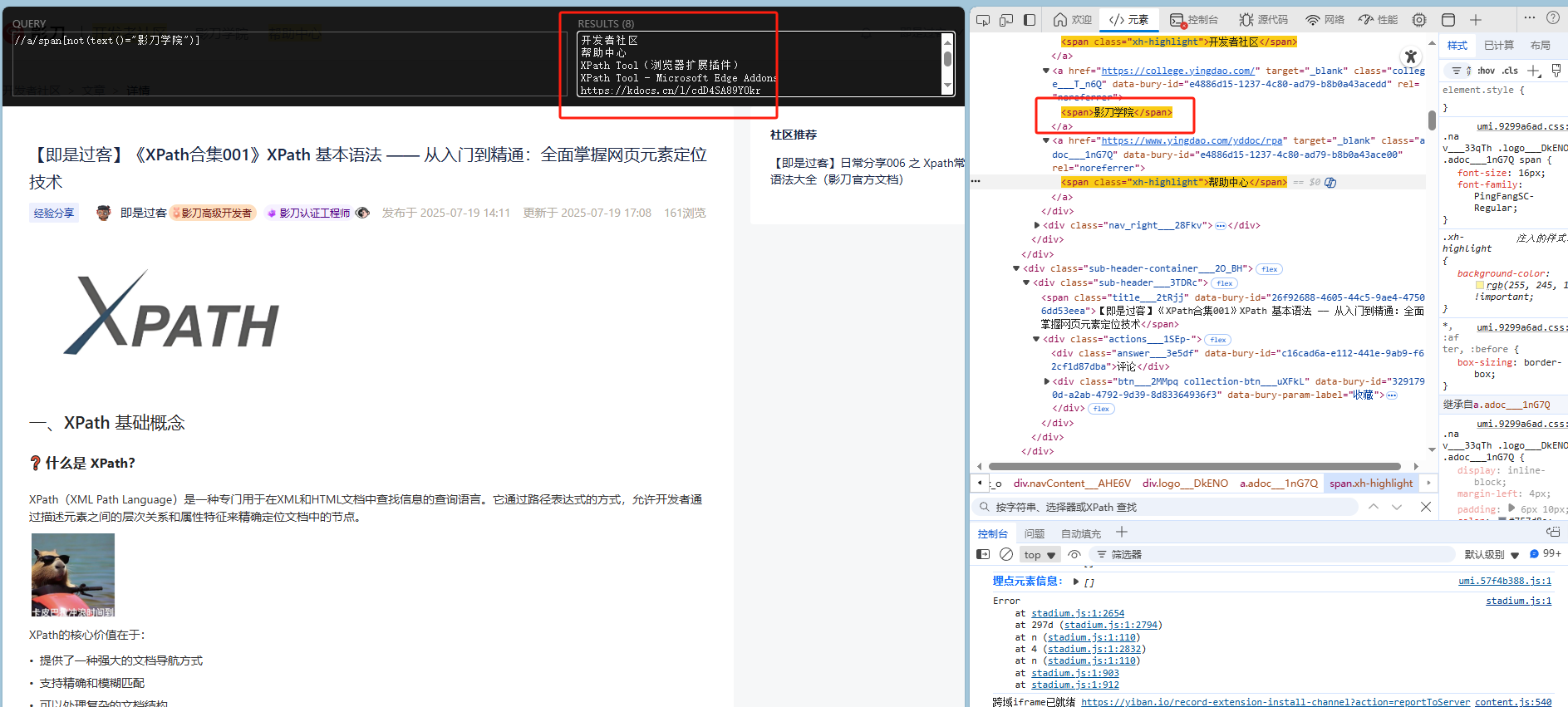
(假设网页中有多个 <span>,XPath会排除 文本 不为“影刀学院”的 <span> 元素,只返回其他符合条件的 <span>。)
3. 字符串处理函数
(1) substring():提取字符串的一部分
功能:从字符串中截取指定位置的部分。
语法:substring(string, start, length)
示例:
substring('影刀RPA', 1, 2)解释:从“影刀RPA”中截取第1到第2个字符(即“影刀”)。
影刀RPA应用场景:
- 从长文本中提取关键信息(如订单号前缀)。
- 在表格中截取部分文本进行匹配(如“订单-12345”截取“订单”部分)。

(2) string-length():计算字符串长度
功能:返回字符串的字符数。
语法:string-length(string)
示例:
string-length('影刀RPA')解释:返回“影刀RPA”的长度(5个字符)。
影刀RPA应用场景:
- 判断文本是否过长(如限制输入框字符数)。
- 在表格中筛选特定长度的文本(如“订单号=10位数字”)。

4. 数值运算函数
(1) sum():计算数值总和
功能:对一组数值求和。
语法:sum(//element)
示例:
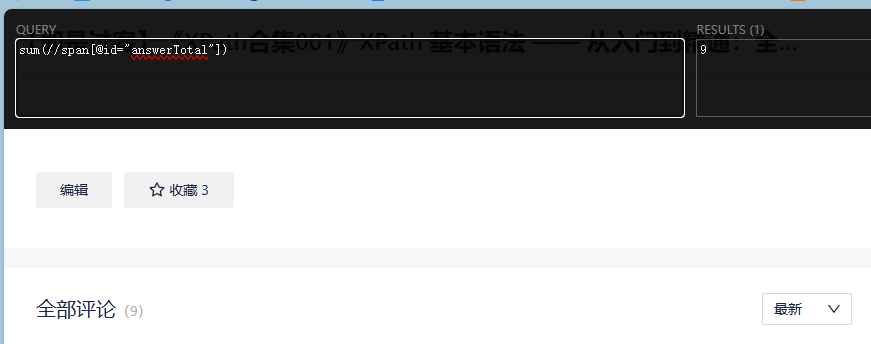
sum(//span[@id="answerTotal"])解释:计算所有 <span> id为 answerTotal 的数值总和。
影刀RPA应用场景:
- 计算购物车总价。
- 统计表格中某列数值的总和(如销售额汇总)。
(2) floor():向下取整
功能:返回小于或等于数值的最大整数。
语法:floor(number)
示例:
floor(3.7)解释:返回3(向下取整)。
影刀RPA应用场景:
- 计算商品数量(如“3.7件”取整为3件)。
- 在表格中处理浮点数数据(如“价格=3.7元”取整为3元)。

(3) ceiling():向上取整
功能:返回大于或等于数值的最小整数。
语法:ceiling(number)
示例:
ceiling(3.2)解释:返回4(向上取整)。
影刀RPA应用场景:
- 计算所需资源(如“3.2GB内存”向上取整为4GB)。
- 在表格中处理浮点数数据(如“价格=3.2元”取整为4元)。

5. 练习题(结合影刀RPA实战)
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>XPath 练习测试页面</title>
</head>
<body>
<ul>
<li>影刀RPA</li>
<li>自动化</li>
<li>数据抓取</li>
<li>流程自动化</li>
<li>影刀RPA教程</li>
</ul>
<div class="container">
<h3>这是一个容器</h3>
<p>这是第一个段落。</p>
<p>这是第二个段落。</p>
<span>这是一个span(不会被选中)</span>
</div>
<div class="footer">
<p>版权所有 © 2025 影刀RPA</p>
<p>联系我们:****@yingdao.com</p>
</div>
<p>以下是测试链接:</p>
<ul>
<li><a href=" http://example.com ">HTTP链接1</a></li>
<li><a href=" https://example.com ">HTTPS链接(不应被选中)</a></li>
<li><a href=" http://test.com ">HTTP链接2</a></li>
<li><a href="/relative/path">相对路径(不应被选中)</a></li>
</ul>
<div class="visible">可见的div(应被选中)</div>
<div class="hidden">隐藏的div(不应被选中)</div>
<div class="visible another-class">多class的可见div(应被选中)</div>
<div style="display:none;">通过style隐藏的div(XPath无法直接检测)</div>
<div>
<p>这是一个额外的段落,用于测试其他XPath表达式。</p>
</div>
</body>
</html>
(对应上面的HTML结构)
- 选择所有包含"影刀RPA"的<li>元素(提示:使用contains()函数)
- 选择class为"container"的<div>中的所有<p>元素(提示:使用层级选择和class属性)
- 选择class为"footer"的<div>中的文本内容(提示:直接定位元素后提取文本)
- 选择所有href以" http://"开头的<a>元素(提示:使用starts-with()函数)
- 选择所有class不为"hidden"的<div>元素(提示:使用not()函数排除特定class)
总结
XPath 是影刀RPA中非常重要的网页元素定位工具,掌握函数、操作符、字符串处理和数值运算,可以让你更精准地抓取数据或操作UI元素。
下一步建议:
- 在影刀RPA中尝试使用XPath定位网页元素。
- 结合实际业务场景,编写更复杂的XPath表达式。
- 多练习,熟悉XPath的灵活用法!
希望本文能帮助你快速掌握XPath的核心知识!🚀
收藏18



