Umi-OCR:免费、离线、速度飞快的OCR文本识别 收藏
收藏
评论
收藏Umi-OCR:免费、离线、速度飞快的OCR文本识别

2025-09-24 18:04·浏览量:1291
RPA梦工厂
 影刀专家
影刀专家前言
话不多说,先收藏

github地址: Umi-OCR
- 速度方面:我只能说快如闪电
- 使用方面:简单
- 准确程度:符合我的要求,满足大部分没问题。
- 免费就是神,免费又快又准就是神中神
使用
下载Umi-OCR:打开: https://github.com/hiroi-sora/Umi-OCR
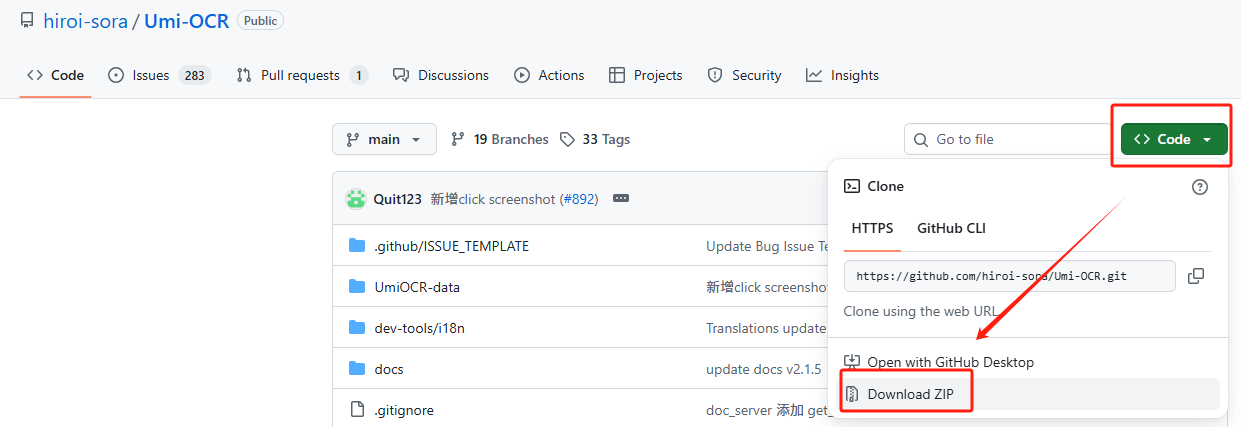
下载完成后解压之后打开解压:
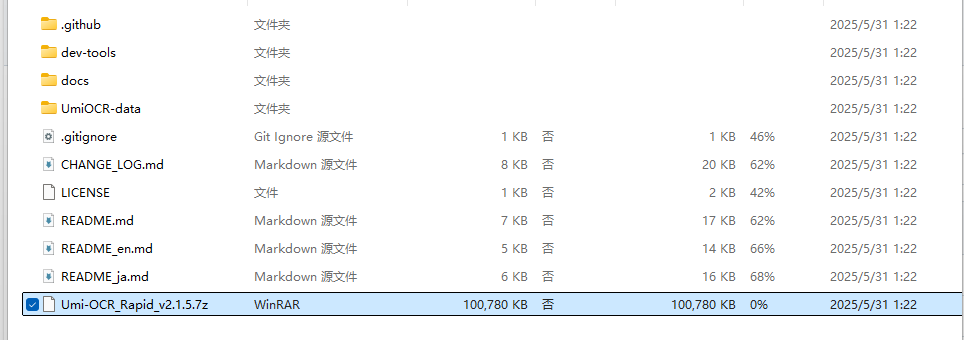
解压完成:

打开之后选择高级:
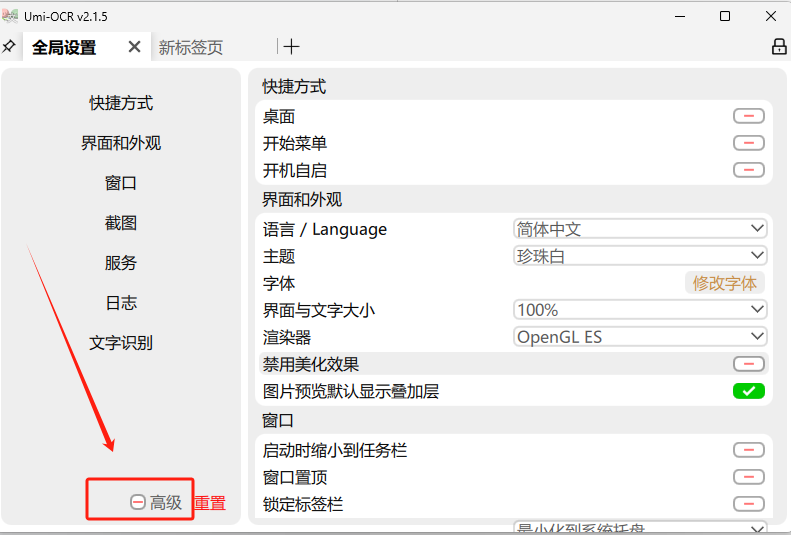
有多个接口,需要自行下载:
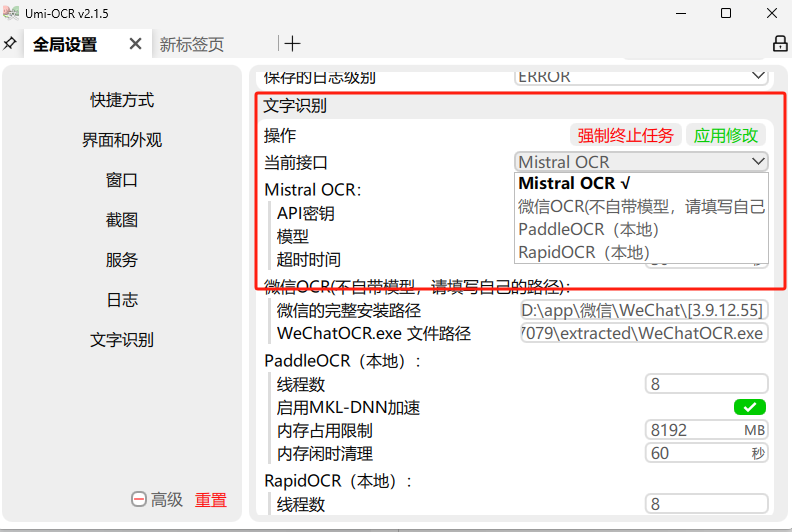
下载地址: https://github.com/hiroi-sora/Umi-OCR_plugins?tab=readme-ov-file ,依次下载到指定文件夹就行。
在影刀使用:
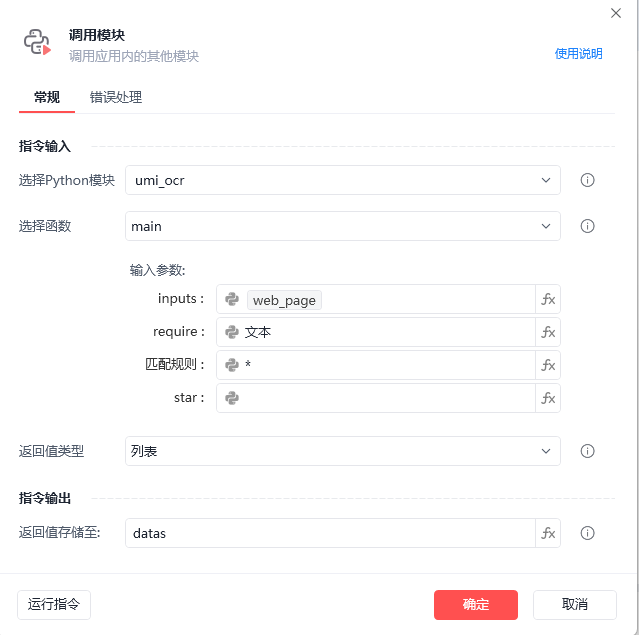
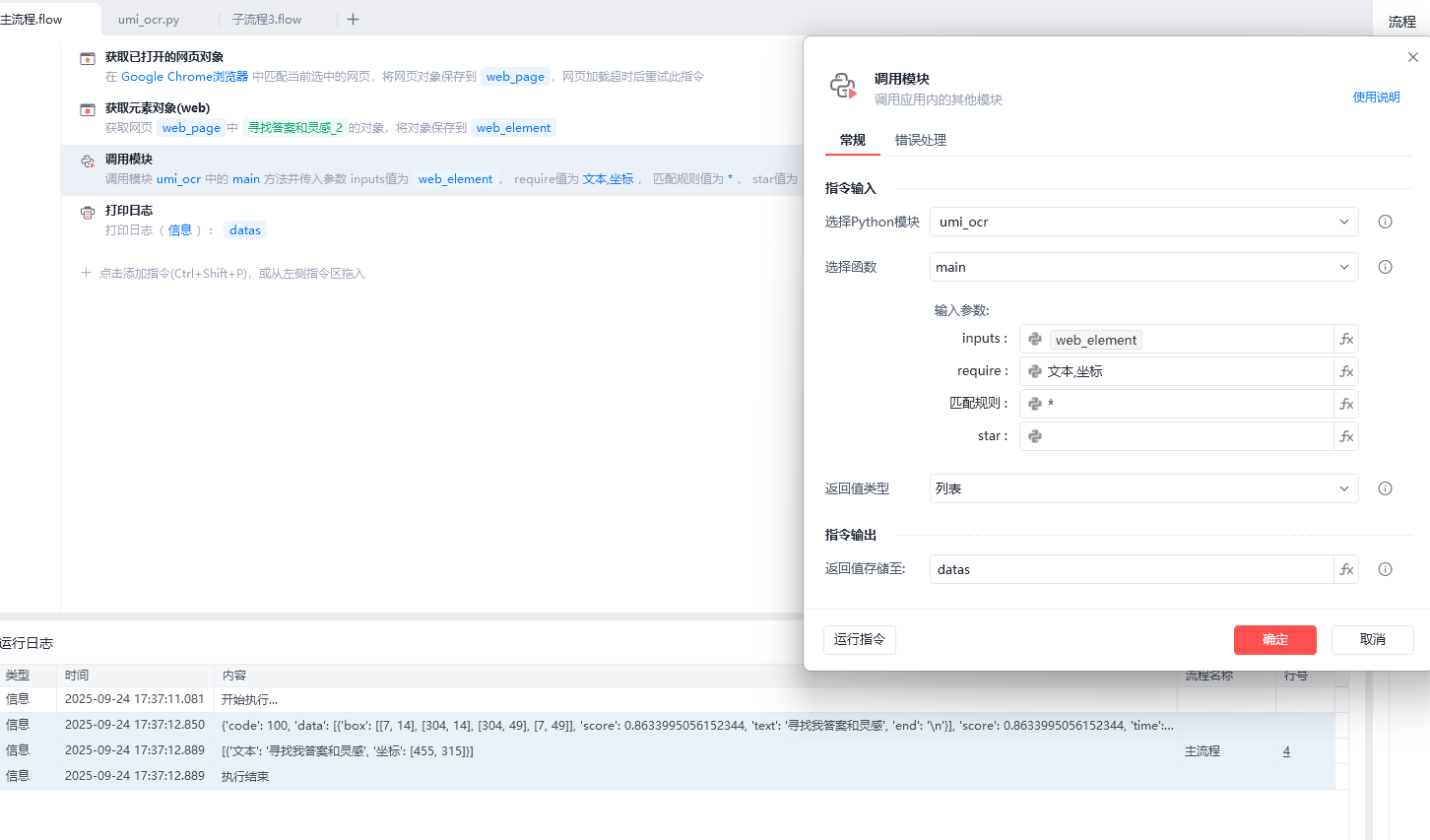
参数说明:
inputs:
需要识别的图片 (支持输入:本地图片、网页对象、窗口对象、网页元素、窗口元素、全屏(全屏输入:空列表)、区域)
require:获取的内容 (包含:识别的文本、中心坐标、位置信息)
输入举例:(文本、坐标、位置)多个参数英文逗号隔开
- 文本
- 文本,坐标
匹配规则:
筛选识别结果里面不需要的文本,使用正则筛选(获取全部输入:*)
举例:
- 回答 识别结果只要等于==回答
- *回答* 识别结果包含回答
- * 不筛选获取全部
star:起始坐标(可不理会,只要是适配点击文本使用,留空就行)
代码:
from . import package
from .package import variables as glv
from xbot import print, sleep, win32, web
import base64, fnmatch, json, os, shutil, time, requests, xbot,glob
def umi_OCR(img_path):
img_base64 = [base64.b64encode(f.read()).decode() for f in [open(img_path, "rb")]][0]
res = requests.post(
"http://127.0.0.1:1224/api/ocr",
json={
"base64": img_base64,
"options": {"data.format": "json"}
}
).json()
print(res)
print(res["time"])
return res
def screenshot(inputs, filepath):
"""
inputs: 可以输入以下: 网页对象/桌面对象、网页元/桌面对象、系统全屏/指定区域
filepath: 指定截图保存路径。 默认路径:桌面+时间戳.png
"""
if not filepath:
filepath = os.path.join(os.path.expanduser("~"), "Desktop", f"{int(time.time())}.png")
if isinstance(inputs, str) and os.path.isfile(inputs):
shutil.copy2(inputs, filepath)
elif "xbot.web" in str(type(inputs)) or "xbot.win" in str(type(inputs)):
try:
save_path, filename = os.path.split(filepath)
inputs.screenshot(save_path, filename=filename)
except:
win32.screenshot.save_window_to_file(0, filepath, "png")
elif isinstance(inputs, list):
args = () if inputs == [0,0,0,0] else tuple(inputs)
win32.screenshot.save_screen_to_file(filepath, "png", *args)
else:
raise ValueError(f"无法识别的 inputs 类型: {type(inputs)}")
return filepath
def 文本匹配(文本, 匹配规则):
try:
for 模式 in (m.strip() for m in 匹配规则.split(",") if m.strip()):
if 模式 == "*" or fnmatch.fnmatch(文本, 模式):
return 文本
except:
pass
return ""
def main(inputs,require, 匹配规则,star):
img_path = screenshot(inputs, "")
res = umi_OCR(img_path)
os.remove(img_path)
# 初始 star
star = star or [0, 0]
if "xbot.web" in str(type(inputs)) or "xbot.win" in str(type(inputs)):
try:
star = inputs.get_bounding(True)[:2]
except:
star = [0, 0]
temp_data = []
for i in res["data"]:
文本 = 文本匹配(i["text"], 匹配规则)
if not 文本:
continue
x1, y1 = i["box"][0]
x2, y2 = i["box"][2]
坐标 = [(x1 + x2) // 2 + star[0], (y1 + y2) // 2 + star[1]]
位置 = {
"左边": x1 + star[0], "顶部": y1 + star[1],
"右边": x2 + star[0], "底部": y2 + star[1],
"宽度": x2 - x1, "高度": y2 - y1,
"中心x坐标":坐标[0],"中心y坐标":坐标[1]
}
temp_data.append({"文本": 文本, "坐标": 坐标, "位置": 位置})
# 排序:始终按纵坐标、再横坐标
temp_data.sort(key=lambda x: (x["坐标"][1], x["坐标"][0]))
fields = [f.strip() for f in require.split(",")]
single_field = len(fields) == 1
# 构建返回
datas = []
for item in temp_data:
if single_field:
datas.append(item[fields[0]])
else:
datas.append({f: item[f] for f in fields})
return datas注意点:
- 对网页元素和窗口对象识别的时候,元素要在可视区域
- 运行代码时:umi-ocr要运行
收藏47全部评论(1)
最新
发布评论
评论




