【第二弹】企业微信的智能表格接收外部数据,通过http实现 收藏
收藏
评论
收藏【第二弹】企业微信的智能表格接收外部数据,通过http实现

2026-05-29 09:04·浏览量:225
早日下班
 影刀高级开发者
影刀高级开发者上次只说了如何实现http实现已创建的智能表格追加数据,但是没有说怎么把我现有的数据转换成http请求体的数据格式
回顾
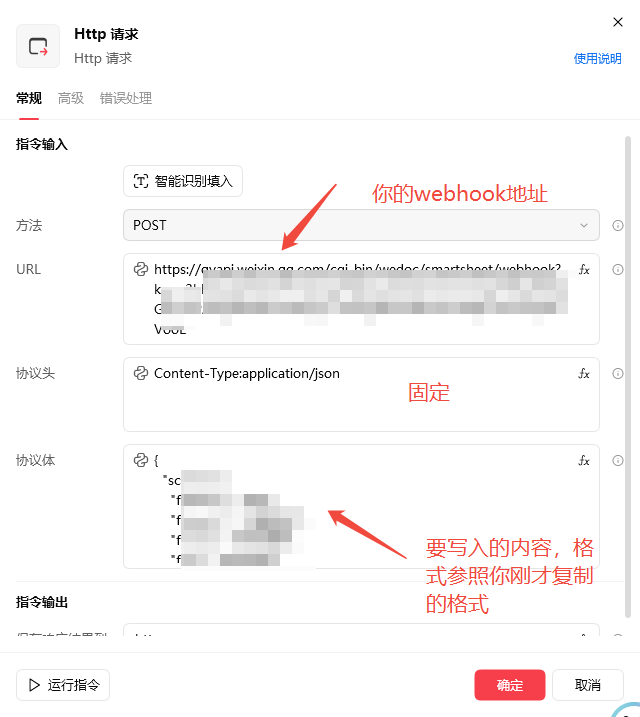
今天就来解决http里面的协议体,直接上代码
1.添加Python模块,把这个复制过去
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
def main(args):
# 1. 准备格式样例(就是您之前给的那个 JSON 对象)
template = {
"schema": {
"f9VGvU": "数据来源",
"fJGWk7": "地区公司",
"fRvN4k": "项目",
"fa2nec": "剩余库存数量",
"fzatfC": "销售量",
"fDT8zi": "日期"
},
"add_records": [
{
"values": {
"f9VGvU": "测试文本", # 文本
"fJGWk7": "测试文本", # 文本
"fRvN4k": "测试文本", # 文本
"fa2nec": 1, # 数字
"fzatfC": 44, # 数字
"fDT8zi": "1735660800000" # 日期时间戳
}
}
]
}
# 2. 您的实际数据(二维列表)
data = [
["数据来源", "地区公司", "项目", "剩余库存数量", "销售量", "日期"],
["优选", "湖南公司", "长沙", 2, 32, "2026-05-28"],
["优选", "辽宁公司", "沈阳", 21, 66, "2026-05-28"]
]
# 3. 直接转换
api_payload = prepare_smartsheet_payload(data, template)
print(api_payload)
# api_payload 的 schema 将与 template 中的完全一致,
# add_records 中的值会自动转换为对应的类型
import pandas as pd
from datetime import datetime
def prepare_smartsheet_payload(data, template):
"""
根据模板样例自动推断字段类型,将二维列表数据转换为智能表格 API 格式。
:param data: 二维列表,首行表头,后续数据行
:param template: 格式样例字典,包含 "schema" 和 "add_records"
(至少一条示例记录,如您提供的完整 JSON 对象)
:return: {"schema": ..., "add_records": [...]}
"""
# 1. 提取 schema 和示例值
schema = template.get("schema", {})
example_vals = template.get("add_records", [{}])[0].get("values", {})
if not schema or not example_vals:
return None
# 建立 标题->ID 映射
title_to_id = {v.strip(): k for k, v in schema.items()}
# 2. 根据示例值推断字段类型
def infer_type(fid, title, ex_val):
# 纯数字字符串且长度>=10 → 日期时间戳
if isinstance(ex_val, str) and ex_val.isdigit() and len(ex_val) >= 10:
return "date"
# int/float → 数字
if isinstance(ex_val, (int, float)):
return "number"
# 其他 → 文本
return "text"
field_types = {}
for fid, title in schema.items():
field_types[fid] = infer_type(fid, title, example_vals.get(fid))
# 3. 数据清洗与转换
if len(data) < 2:
return None
header = [str(c).strip() for c in data[0]]
df = pd.DataFrame(data[1:], columns=header)
# 只保留 schema 中存在的列
available_titles = [t for t in title_to_id if t in df.columns]
df = df[available_titles]
def convert(val, fid):
ftype = field_types[fid]
if pd.isna(val) or val == "":
return 0 if ftype == "number" else ""
s = str(val).strip()
# 日期字段:解析并输出毫秒时间戳字符串
if ftype == "date":
# 已经是时间戳数字字符串
if s.isdigit():
return s
# 常见日期格式
for fmt in ("%Y-%m-%d %H:%M:%S", "%Y-%m-%d"):
try:
dt = datetime.strptime(s, fmt)
return str(int(dt.timestamp() * 1000))
except ValueError:
continue
try:
dt = pd.to_datetime(s, errors='coerce')
if pd.notna(dt):
return str(int(dt.timestamp() * 1000))
except:
pass
return s # 解析失败,原样返回
# 数字字段:支持百分数、无效符号处理
if ftype == "number":
if s.endswith('%'):
try:
num = float(s[:-1]) / 100.0
return int(num) if num.is_integer() else num
except ValueError:
pass
if s in ('-', '--', 'N/A', 'null', 'None'):
return 0
try:
num = float(s)
return int(num) if num.is_integer() else num
except (ValueError, TypeError):
return 0
# 文本字段:直接返回字符串
return s
# 4. 构建 add_records
add_records = []
for _, row in df.iterrows():
values = {}
for title, fid in title_to_id.items():
if title not in row:
continue
converted = convert(row[title], fid)
# 保留数字0,跳过空字符串
if field_types[fid] == "number" or converted != "":
values[fid] = converted
add_records.append({"values": values})
print('结果')
print({"schema": schema, "add_records": add_records})
return {"schema": schema, "add_records": add_records}2.调用prepare_smartsheet_payload函数,提供两个参数。
data:数据格式是二维列表,就是需要添加的数据记录
template:数据格式是字典,就是从企业微信粘贴过来的
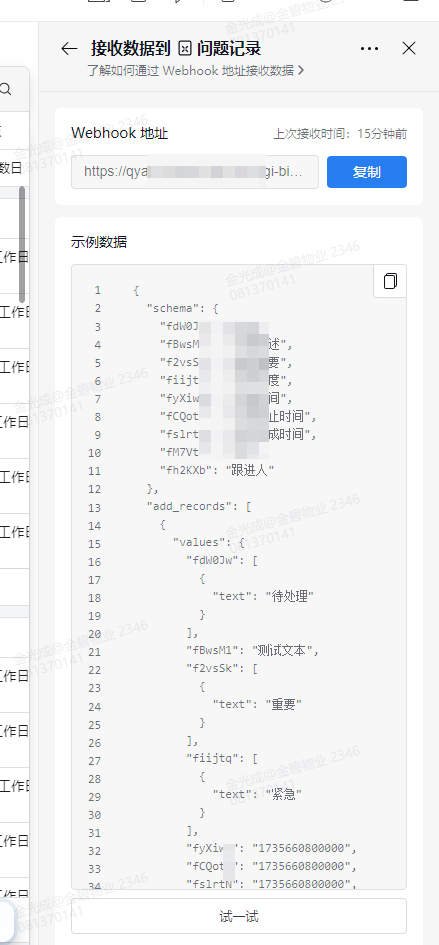
注意:template第二个参数就直接复制智能表格的示例数据即可,记得把换行符替换掉。
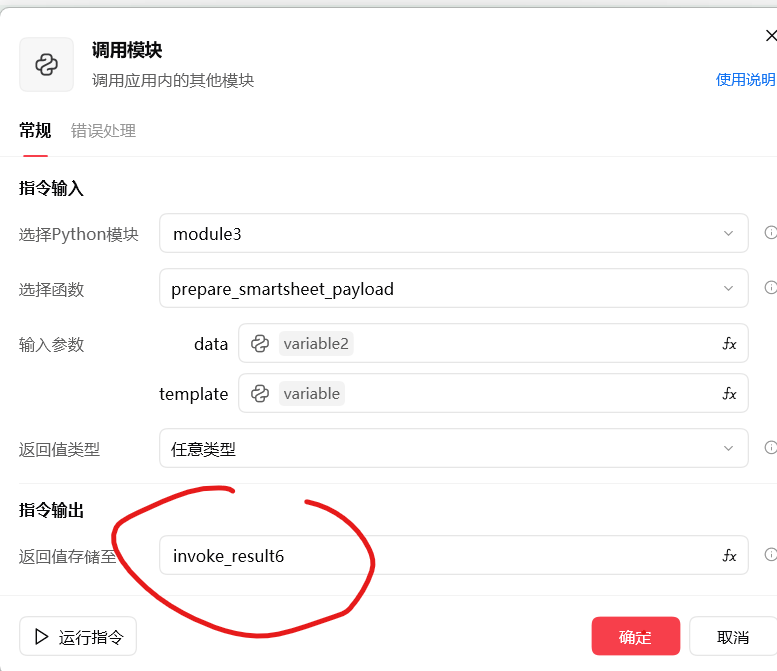
3.把这个调用的结果输出给刚刚的http指令就可以了。
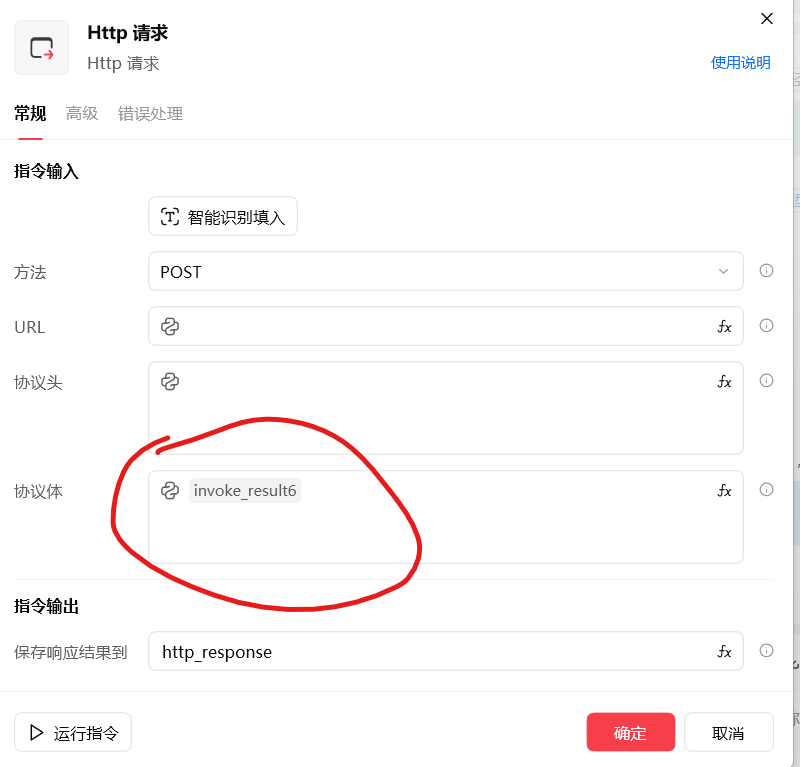
先把结果转换一下,传给http指令就可以了

【第一弹】参考:企业微信的智能表格接收外部数据,通过http
收藏2全部评论(1)
最新
发布评论
评论




