语音转文字 By openai-whisper 收藏
收藏
评论
收藏语音转文字 By openai-whisper

K2022
2025-03-15 20:30·浏览量:5969K2022
 影刀认证工程师发布于 2024-02-17 21:29更新于 2025-03-15 20:305969浏览
影刀认证工程师发布于 2024-02-17 21:29更新于 2025-03-15 20:305969浏览概述:
Whisper是Openai开源的通用语音识别模型
Whisper是端到端的语音系统,相比于之前的端到端语音识别,其特点主要是:
- 多语种:英语为主,支持99种语言,包括中文。
- 多任务:语音识别为主,支持VAD、语种识别、说话人日志、语音翻译、对齐等。
- 数据量:68万小时语音数据用于训练,从公开数据集或者网络上获取的多种语言语音数据,远超之前语音识别几百、几千、最多1万小时的数据量。下面会展开介绍。
- 鲁棒性:主要还是源于海量的训练数据,并在语音数据上进行了常见的增强操作,例如变速[1]、加噪、谱增强[2]等。
- 多模型:提供了从tiny到large,从小到大的五种规格模型,适合不同场景。如下图所示(速度逐级递减,精度逐级递增):

其中 tiny到medium除了通用版本还有纯英文版本(后缀.en)
使用的话推荐使用:
small
medium
large
这个3个模型(俗称小杯,中杯,大杯)
其中大杯(large)有3个版本 最新版是larg-V3(使用大杯建议用V3版本)
安装:
要使用64位的影刀哟
安装openai-whisper,20230124这个版本其他版本不支持python3.7或者影刀上安装使用报错 (使用python310的影刀直接安装即可)
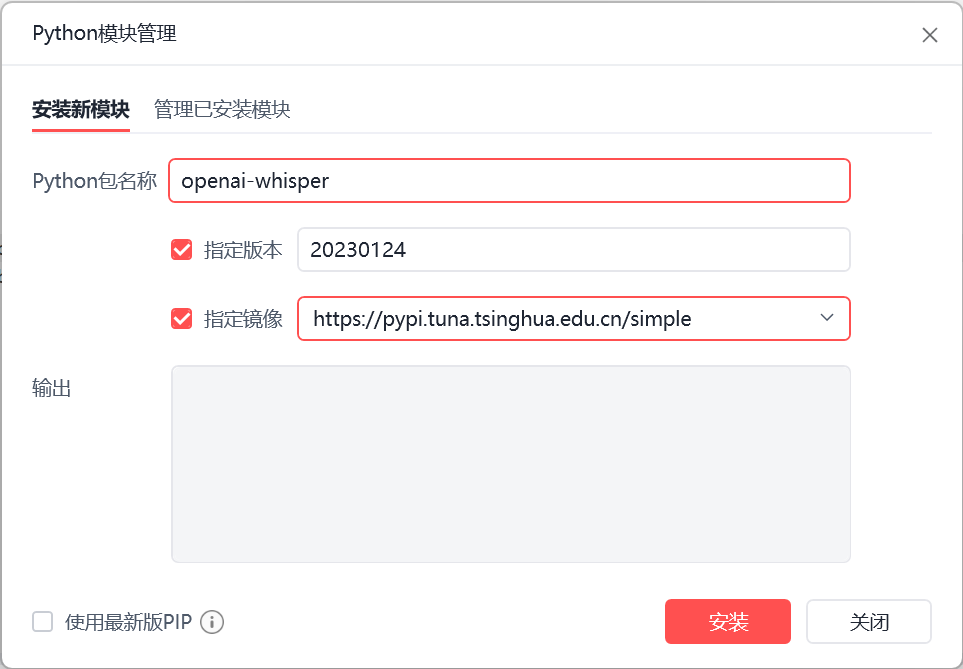
Whisper还依赖 FFMPEG 所有使用前还需要下载 FFMPEG(需要配置 系统环境变量(PATH) )
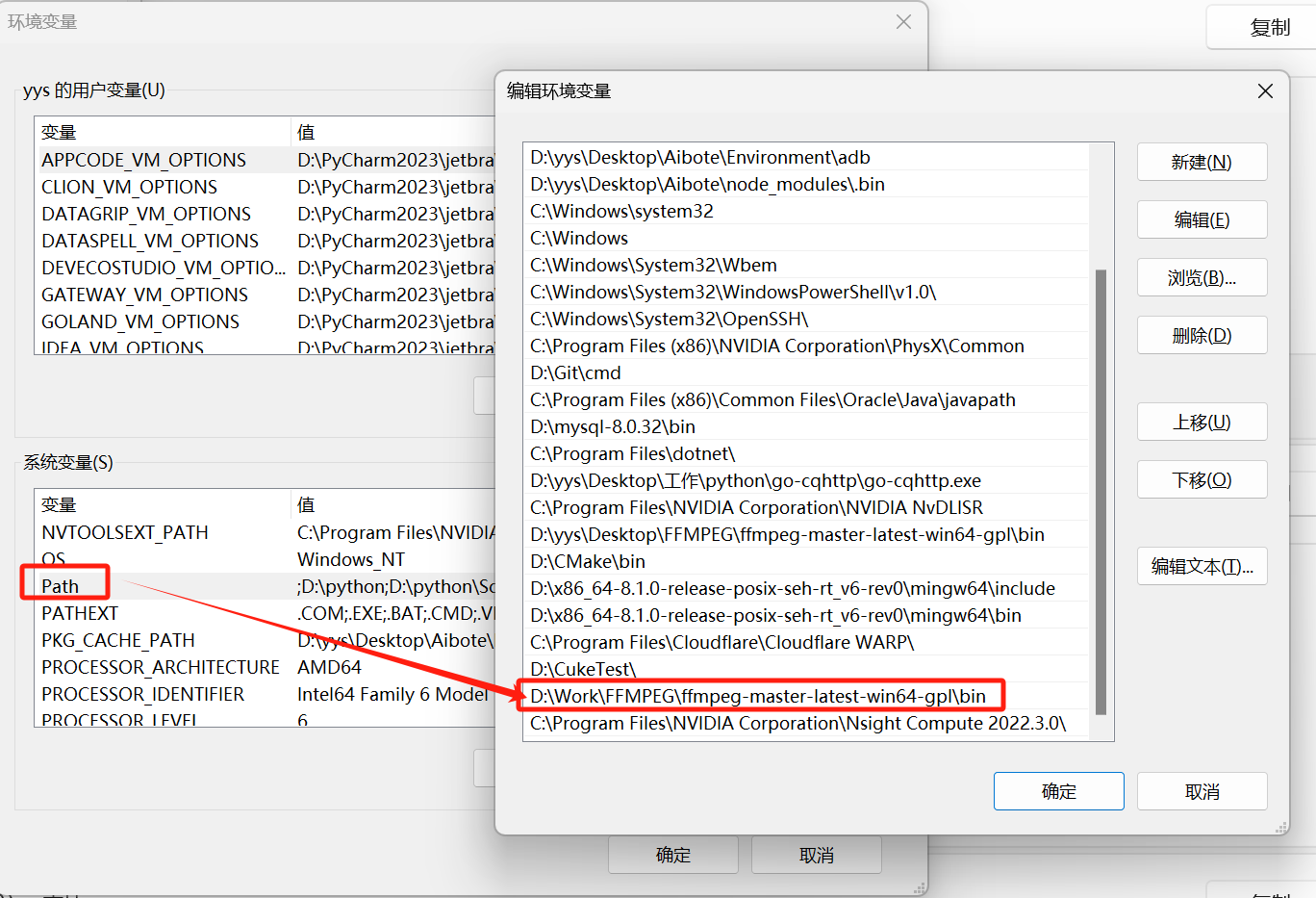
下载地址: https://github.com/BtbN/FFmpeg-Builds/releases
如果没法正常访问Github可以下载一个Steam++(可以加速) 官网地址址:https://steampp.net/
使用示例(第一次使用会自动下载模型要等会,有的模型比较大下载的时间会比较长):
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import whisper
def main(args):
# name 模型的名称或路径 download_root 指定模型下载位置 默认路径 C:\Users\用户名\.cache\whisper
model = whisper.load_model(name="small",download_root="D:\Work\文字转语音")
# initial_prompt 指定格式 防止出现简繁混合的情况
result = model.transcribe(r"D:\Work\文字转语音\audio\20240217132255.mp3",initial_prompt="简体中文")
print(result["text"])
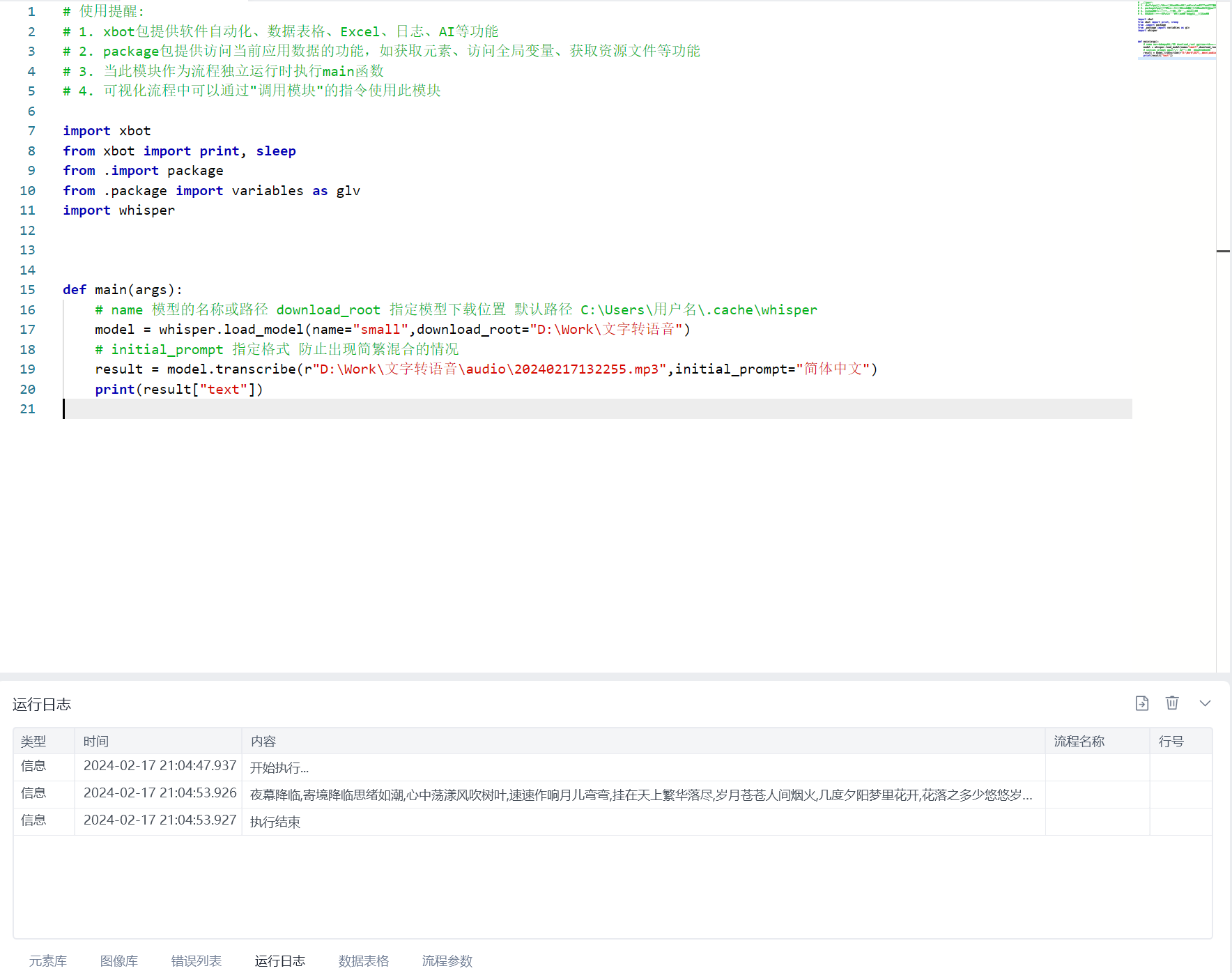
Whisper支持CPU和GPU两种模式默认为CPU 上面就是使用的CPU
GPU模式:
使用前需要安装pytroch cuda 等依赖库
使用此命令在影刀的python虚拟环境中使用命令行安装
具体步骤看这里:进入影刀应用虚拟环境 命令行安装python依赖库 具体步骤(By 语音转文字贴 GPU模式依赖库安装步骤补充)
python -m pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117依赖安装完成后即可使用GPU模式
使用示例(就改个参数):
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import whisper
def main(args):
# name 模型的名称或路径 download_root 指定模型下载位置 默认路径 C:\Users\用户名\.cache\whisper device CPU或GPU模式
model = whisper.load_model(name="small",download_root="D:\Work\文字转语音",device="cuda")
# initial_prompt 指定格式 防止出现简繁混合的情况
result = model.transcribe(r"D:\Work\文字转语音\audio\20240217132255.mp3",initial_prompt="简体中文")
print(result["text"])
项目地址
https://github.com/openai/whisper?tab=readme-ov-file
收藏17全部评论(1)
最新
发布评论
评论




