 收藏
收藏影刀RPA自动化之网页数据采集
网页数据采集的各种情况
1. 解析HTML文档获取数据
2. 直接通过API请求获取数据【JSON字符串或其它】
在这两种情况下,又有
1. 不需要身份验证,直接可获得数据
2. 需要身份验证,登录后才能获取数据
现在以爬取【 http://bi.powcodes.cn/question/41?team=BLG 】中数据为例,
登录: 用户名:test@powcodes.cn 密码:@test123
有以下方法:
方法一:解析HTML代码
1. 使用影刀可视化流程,打开网址,输入用户名和密码,点击登录
2. 获取网页元素,解析或者直接使用数据抓取指令
方法二:使用HTTP请求
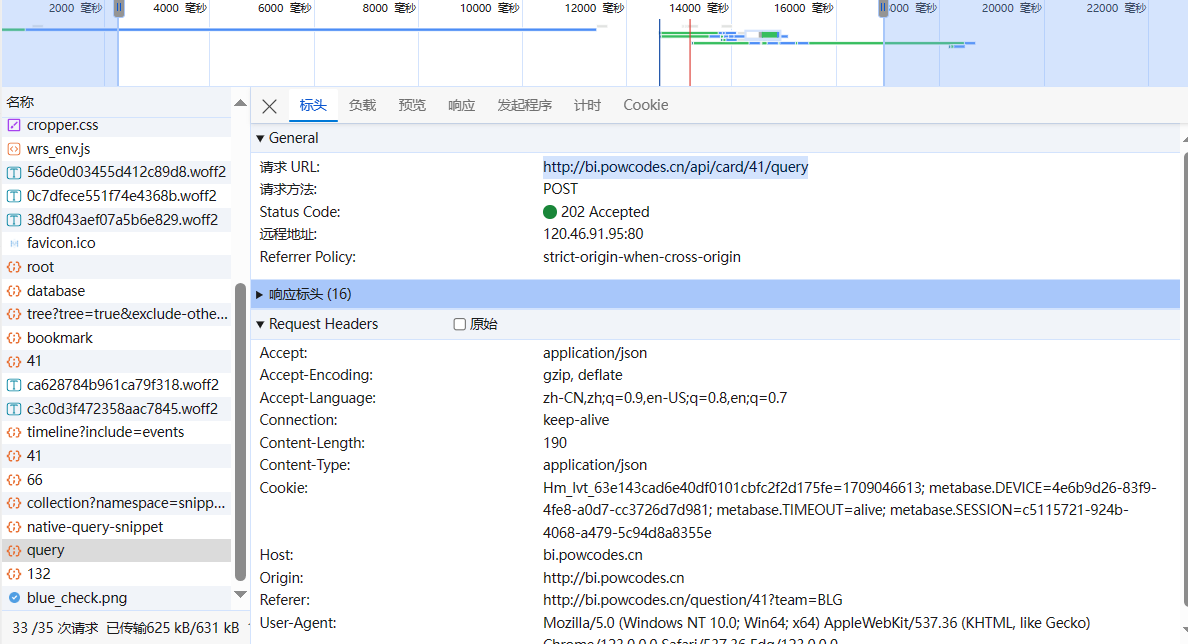
1. 打开开发者工具,发现页面请求数据的API是 http://bi.powcodes.cn/api/card/41/query ,POST请求
2. 直接使用影刀HTTP请求指令,并将请求头复制到HTTP请求指令的参数中【这儿可以使用获取页面cookie的代码】
方法三:JavaScript代码执行http请求
function (element, input) {
var xmlHttp = new XMLHttpRequest();
xmlHttp.open('POST', 'http://bi.powcodes.cn/api/card/41/query',false);
xmlHttp.setRequestHeader('content-type', 'application/json');
xmlHttp.send();
xmlHttp.onreadystatechange = function() {
if (xmlHttp.readyState == 4 && xmlHttp.status == 202) {
console.log('成功');
}else {
//请求失败的回调函数
console.log('保存失败');
}
}
return xmlHttp.responseText;
}网站反爬机制
大部分网站都会设置一些反爬机制,来防止服务器资源被消耗和数据被盗取
封IP:识别出异常的IP地址并进行封锁。
封User-Agent:通过识别请求头中的User-Agent值来拒绝爬虫访问。
封Cookie:服务器通过校验请求头中的Cookie值来区分正常用户和爬虫程序。
JavaScript渲染:动态渲染页面内容,使爬虫无法直接获取数据。
验证码验证:超过一定访问次数后,要求输入验证码以继续访问。
Ajax异步传输:通过异步技术传输数据,使爬虫直接抓取时信息为空。
CSS偏移:通过CSS样式混淆文本内容,使爬虫抓取到的数据不准确。
SVG映射:使用SVG图形代替文字,防止爬虫读取内容。
我所遇到的问题:
一般真人查看的数据量或点击频率在某一段时间是有个阈值的,超过了这个阈值,可能就会被IP封禁或需要验证
1. IP封锁【解决方法:使用IP池,或者直接使用翻墙工具】
2. 数据采集过程中突然需要验证是否是真人【一般会弹出验证码框或者直接网页跳转,验证了才能继续访问】【解决方法:在代码中加入处理机制,根据出现的情况,采用相应的方法】
收藏7



