 收藏
收藏基于faster-whisper的字幕解析(语音识别)本地部署经验分享

一、背景
本文主要介绍一下faster-whisper这个强大语音识别库,避免调用各种大厂识别api使用次数不够的问题,给大家提供一个思路。
后续会再更新一篇结合字幕解析和影刀做视频自动化剪辑的经验分享,这里算是做一下前置步骤了解一下。
简介
faster-whisper是基于OpenAI的Whisper模型的高效实现,它利用CTranslate2,一个专为Transformer模型设计的快速推理引擎。这种实现不仅提高了语音识别的速度,还优化了内存使用效率。faster-whisper的核心优势在于其能够在保持原有模型准确度的同时,大幅提升处理速度,这使得它在处理大规模语音数据时更加高效。
性能对比
在性能方面,faster-whisper展现了显著的优势。例如,在使用Large-v2模型和GPU进行13分钟音频的转录测试中,faster-whisper仅需54秒,而原始Whisper模型需要4分30秒。这一显著的性能提升,意味着在实际应用中,faster-whisper能够更快地处理大量数据,特别是在需要实时或近实时语音识别的场景中。
适用场景推荐
faster-whisper适用于多种场景,特别是那些需要快速、准确的语音识别的应用。例如,在客户服务中,它可以用于实时语音转文字,提高响应速度和服务质量。在医疗领域,faster-whisper可以辅助医生快速转录病历,提高工作效率。此外,它还适用于实时会议记录、多语言翻译、教育辅助等多个领域。
二、本地部署
1.python安装
安装faster-whisper很简单,但是需要python3.8以上,官方推荐版本是3.10.6或者3.10.9,建议去官方找对应版本下载,安装的时候记得勾选Add python to PATH即可
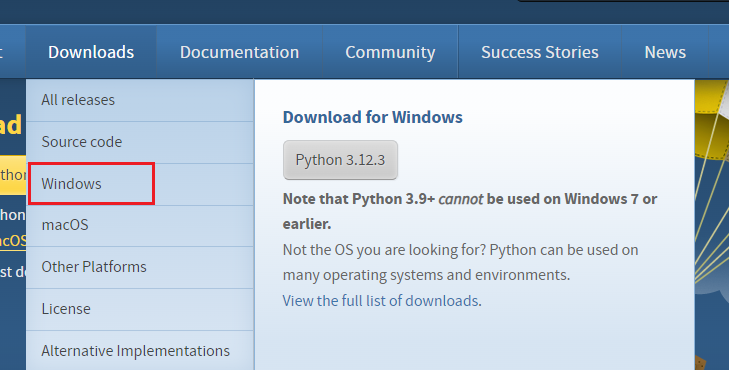
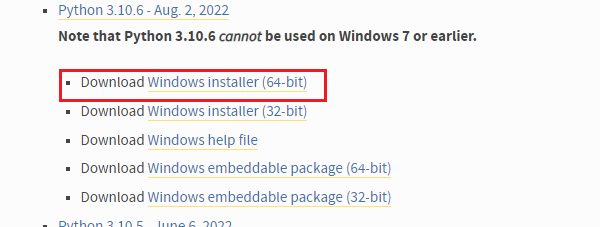
安装成功之后,WIN+R 在cmd窗口里输入python -V 出现Python版本就是安装完成了,如有其他问题百度一下吧,python安装有太多详细教程了,这里略过

2.安装相关的库
# pip install faster-whisper
# pip install zhconv
因为读取出来的是繁体所以需要转换一下,用zhconv库来处理
3.下载语音识别模型到本地
# large-v3模型:https://huggingface.co/Systran/faster-whisper-large-v3/tree/main
# large-v2模型:https://huggingface.co/guillaumekln/faster-whisper-large-v2/tree/main
# large-v2模型:https://huggingface.co/guillaumekln/faster-whisper-large-v1/tree/main
# medium模型:https://huggingface.co/guillaumekln/faster-whisper-medium/tree/main
# small模型:https://huggingface.co/guillaumekln/faster-whisper-small/tree/main
# base模型:https://huggingface.co/guillaumekln/faster-whisper-base/tree/main
# tiny模型:https://huggingface.co/guillaumekln/faster-whisper-tiny/tree/main
4.简易代码实现语音识别
from zhconv import convert
from faster_whisper import WhisperModel
# faster_whisper使用示例
#指定模型大小,可选"small"、"medium"、"large"
path = r"D:\下载\视频\识别模型\large_v3"
audio_file = r"D:\下载\视频\test.wav"
#加载模型
model = WhisperModel(model_size_or_path=path, device="cpu", compute_type="int8")
#识别音频文件
segments,info = model.transcribe(audio_file,beam_size=5,language = 'zh')
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, convert(segment.text,'zh-cn')))
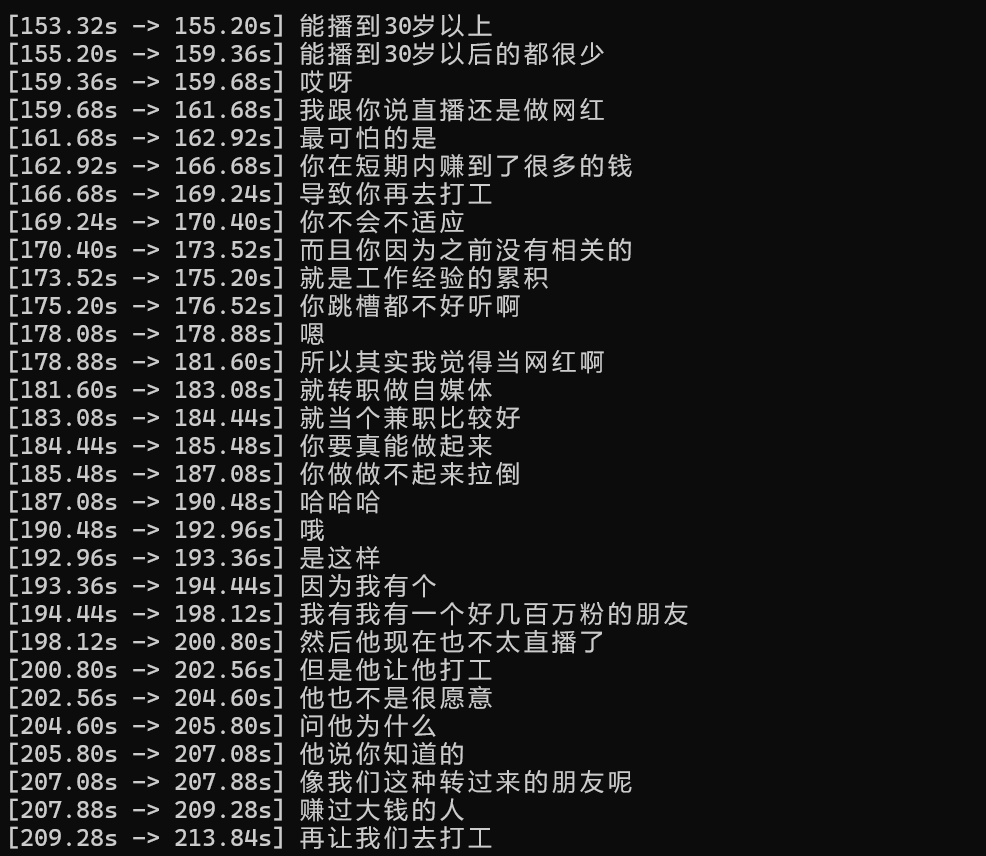
识别效果
5.最终优化版本-生成srt文件
纯CPU运行会慢很多......8分钟的视频差不多需要8分钟识别....有优化方案欢迎评论区交流
# faster-whisper生成srt
from datetime import timedelta,datetime
from zhconv import convert
from faster_whisper import WhisperModel
path = r"D:\下载\视频\识别模型\large_v3"
audio_file = r"D:\下载\视频\test.wav"
output_file = r"D:\下载\视频\test.srt"
#加载模型
model = WhisperModel(model_size_or_path=path, device="cpu", compute_type="int8")
#识别音频文件
segments,info = model.transcribe(audio_file,beam_size=5,language = 'zh')
subtitles = []
for segment in segments:
# 计算开始时间和结束时间
#将秒数转换为时间格式
start = str(timedelta(seconds=int(segment.start)))
end = str(timedelta(seconds=int(segment.end)))
# 构建字幕文本
subtitle_text = f"【{start} -> {end}】: {convert(segment.text,'zh-cn')}"
print(subtitle_text)
subtitles.append(subtitle_text)
# 将字幕文本写入到指定文件中
with open(output_file, "w", encoding="utf-8") as f:
for subtitle in subtitles:
f.write(subtitle + "\n")




