网页视频下载,源码中找不到视频链接?这怎么搞?---- by.广州组 收藏
收藏
评论
收藏网页视频下载,源码中找不到视频链接?这怎么搞?---- by.广州组
昕
2023-11-06 17:54·浏览量:3839
昕
昕怡
有意思的 视频下载 时没有下载按钮?源码中没有链接?
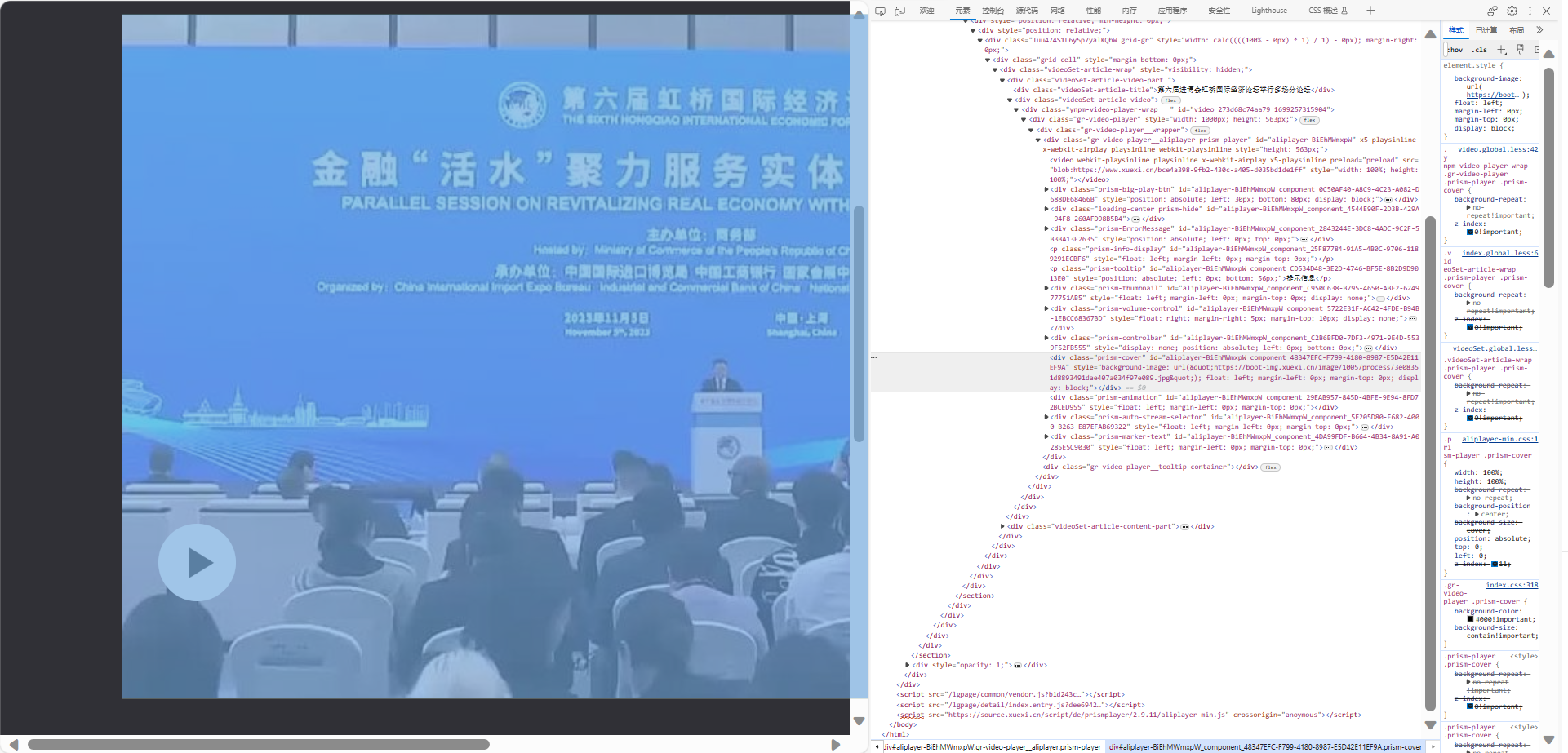
不要急!!!是时候让影刀出手了
以 测试连接 为案例
这个时候我们就要观察下这个视频的格式了,在网络中可以看到,这样的视频是由多个‘.ts’格式视频合成的‘.m3u8’格式视频
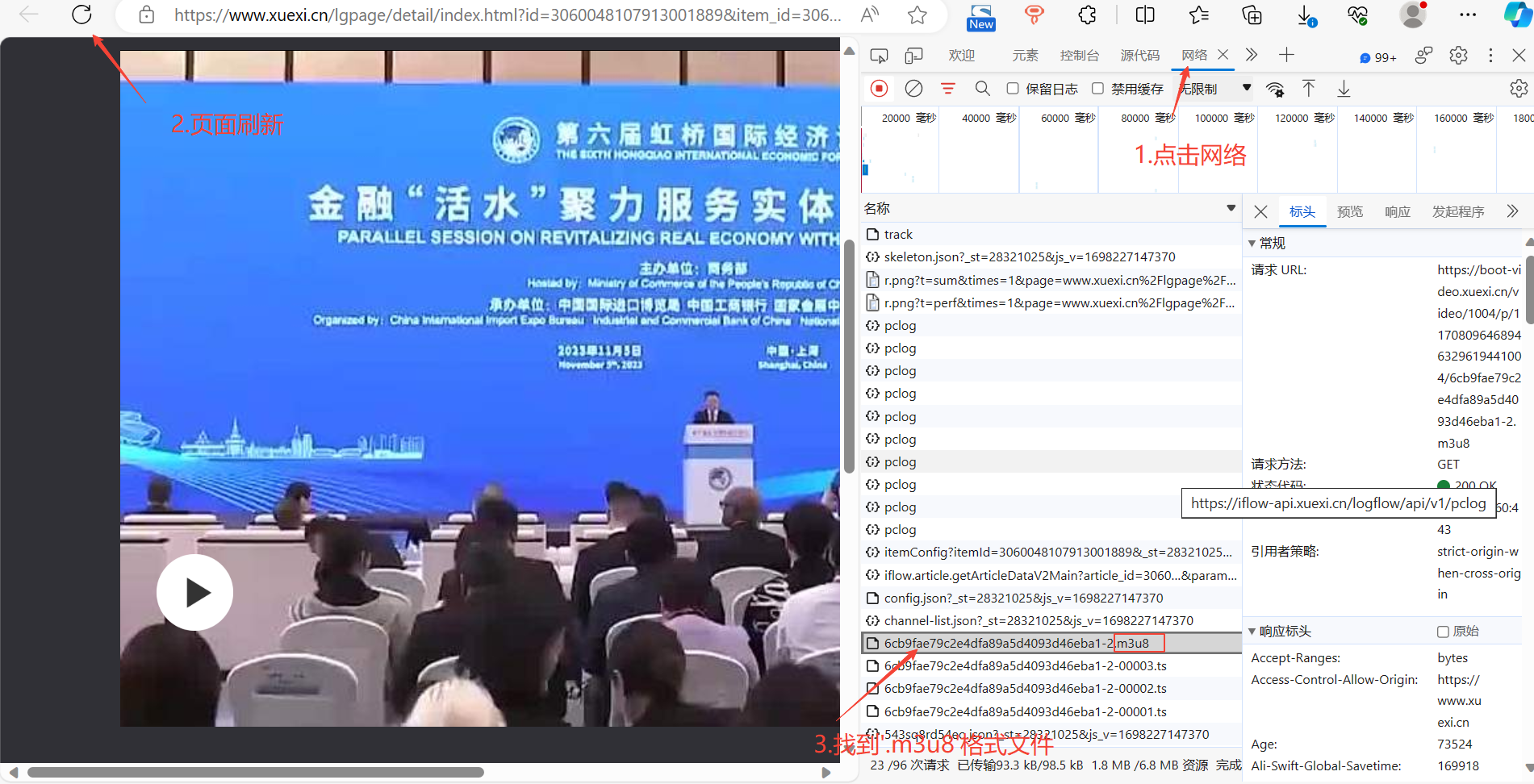
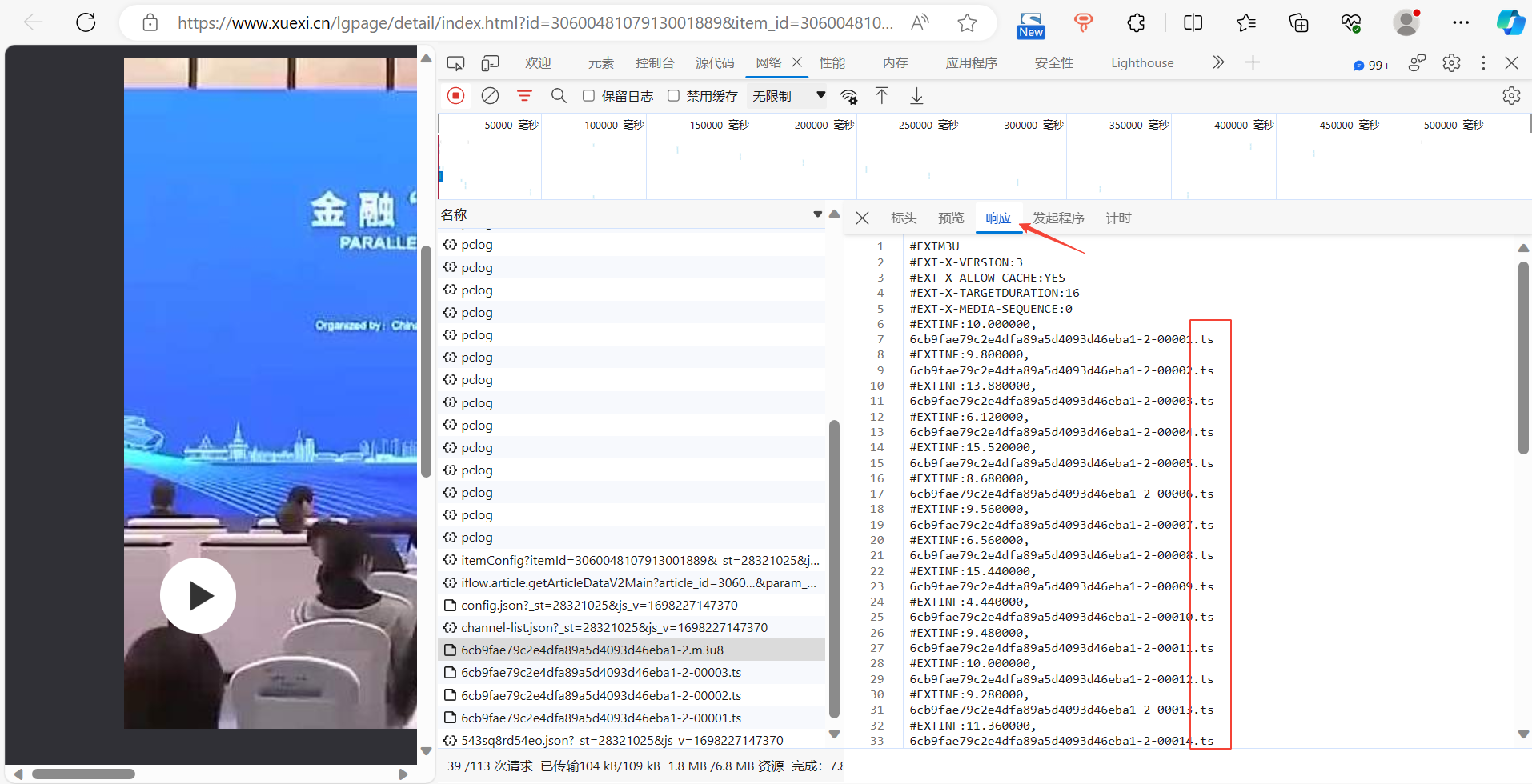
影刀下载‘.m3u8’视频?选择将‘.m3u8’文件在新标签页中打开,即可下载视频至本地
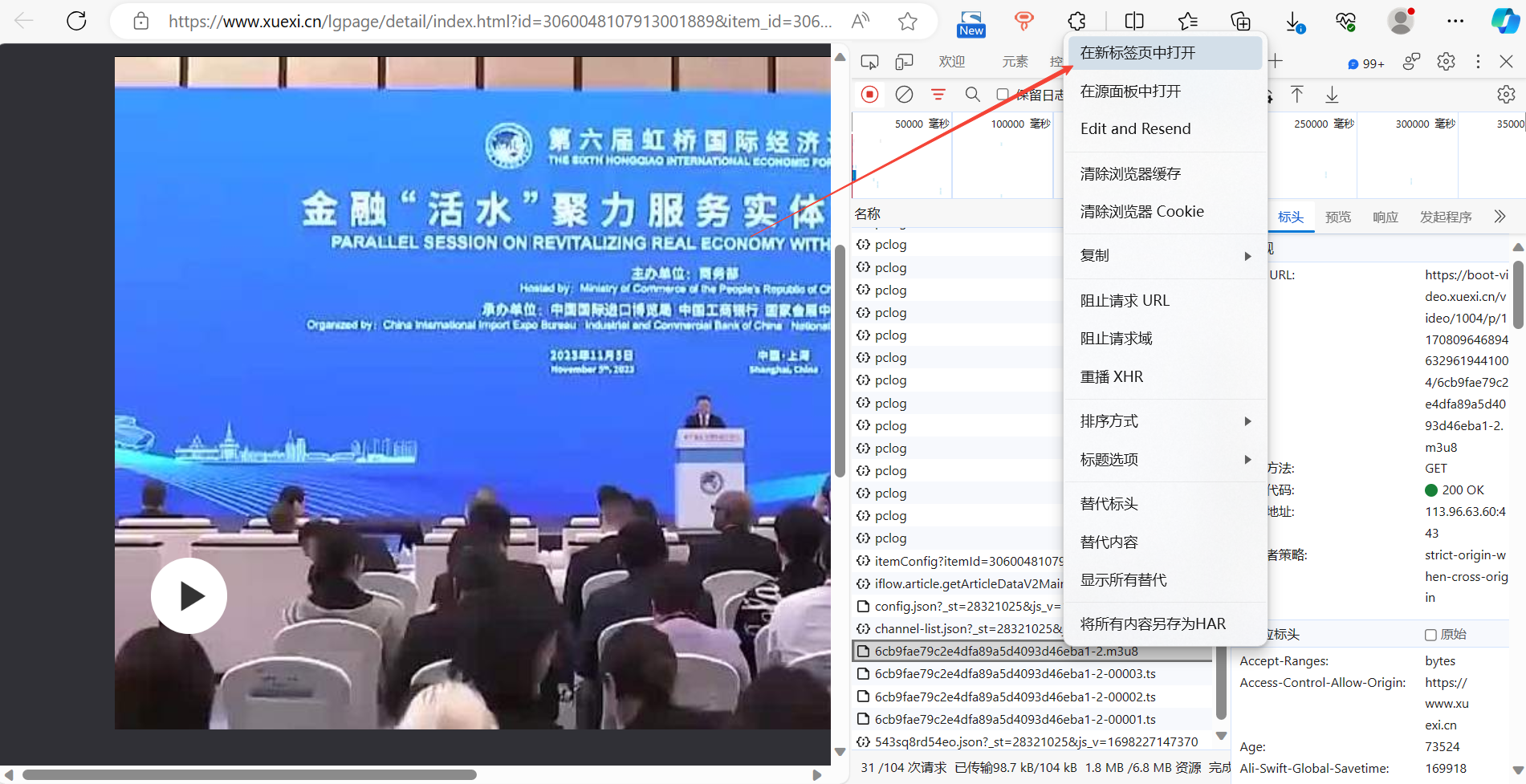
获取下载的文件路径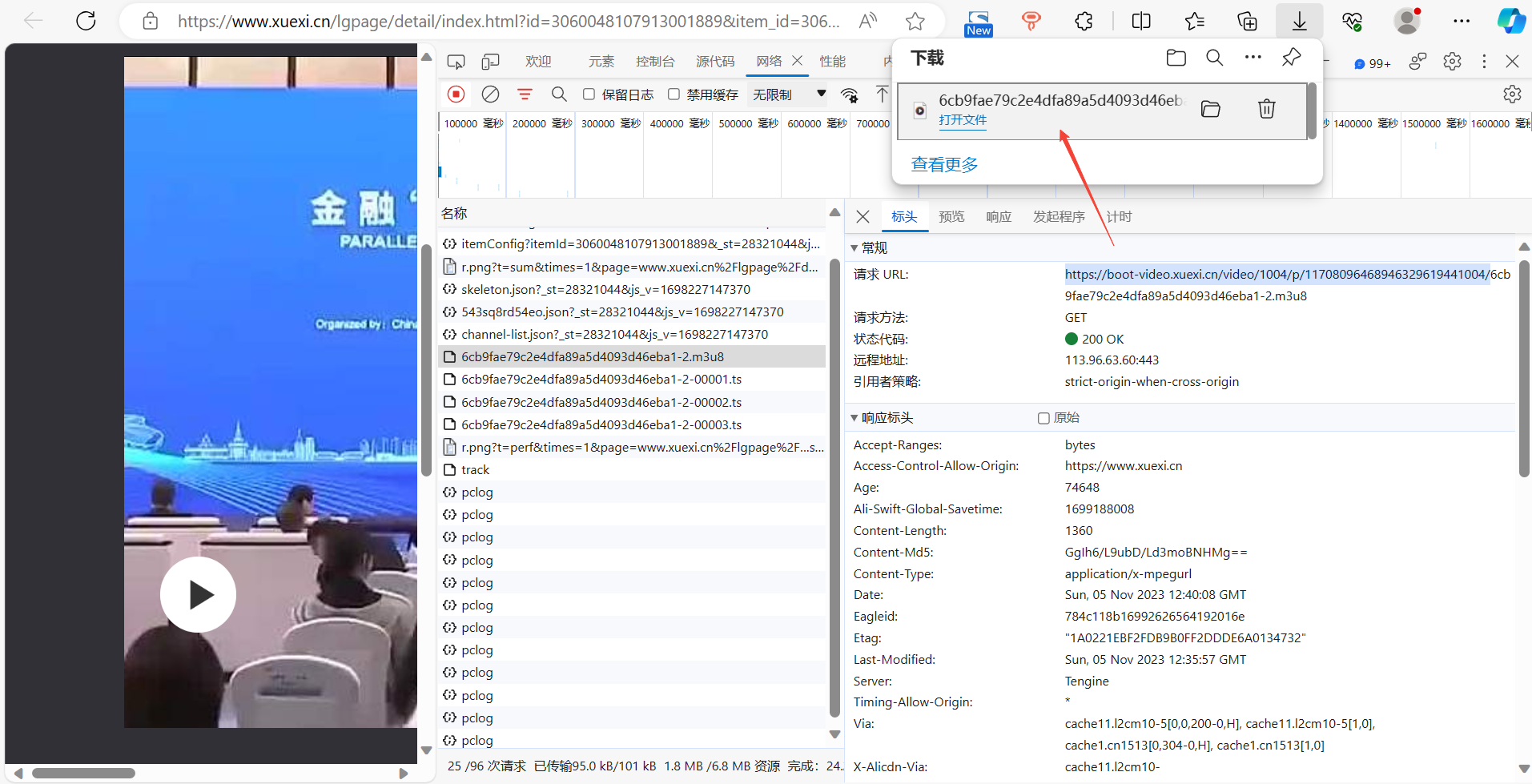
获取‘.m3u8’标头请求URL中的上一级链接
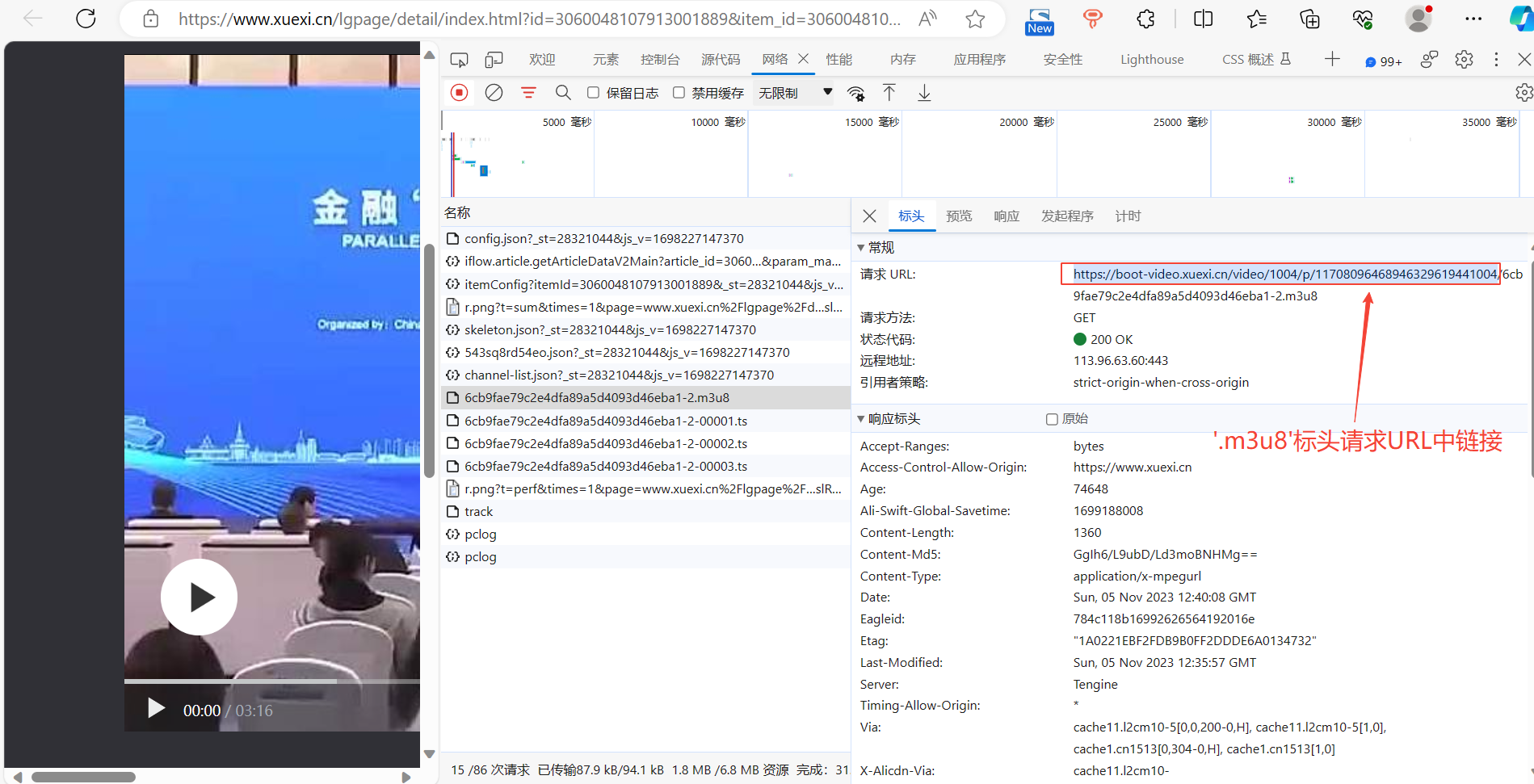
在影刀中执行
# cmd command
# copy /b *.ts demo.mp4
# del *.ts
import re
from datetime import datetime
from pathlib import Path
import requests
import xbot
import xbot_visual
from xbot import print, sleep
from .import package
from .package import variables as glv
def main(args):
down_m3u8(
prefix_url='https://boot-video.xuexi.cn/video/1004/p/11708096468946329619441004/',
m3u8_path=get_m3u8_path()
)
def get_m3u8_path():
special_dir = xbot_visual.dir.get_special_dir(
special_dir_name='DesktopDirectory'
# special_dir_name='Downloads'
)
m3u8_path = xbot_visual.dialog.show_select_file_dialog(
title='请选择待处理的m3u8文件',
folder=special_dir,
filter='m3u8文件|*.m3u8',
is_multi=False,
is_checked_exists=False
).file
return m3u8_path
def down_m3u8(prefix_url, m3u8_path):
now_str = datetime.now().strftime('-%Y%m%d-%H%M%S')
ts_dir = Path(m3u8_path).parent / (Path(m3u8_path).stem + now_str)
if not ts_dir.exists():
ts_dir.mkdir()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'Cookie': 'PHPSESSID=9vkq2mn81m6b6i77mdq844c7e6; Hm_lvt_9e040bc17cc3f73515e65e5786a1d1ad=1690472880,1690521146,1690617905,1690641703; Hm_lpvt_9e040bc17cc3f73515e65e5786a1d1ad=1690641747'
}
with open(m3u8_path, 'r') as f:
m3u8_data = f.read()
ts_info_lst = re.sub('#E.*', '', m3u8_data).split()
for index, ts in enumerate(ts_info_lst):
if index < 0:
continue
ts_url = prefix_url + ts
index_str = f'00000000000{index}'[-5:]
print(index_str, ts_url)
content = requests.get(url=ts_url, headers=headers).content
with open(ts_dir / f'{index_str}.ts', mode='wb') as f:
f.write(content)运行日志如下:
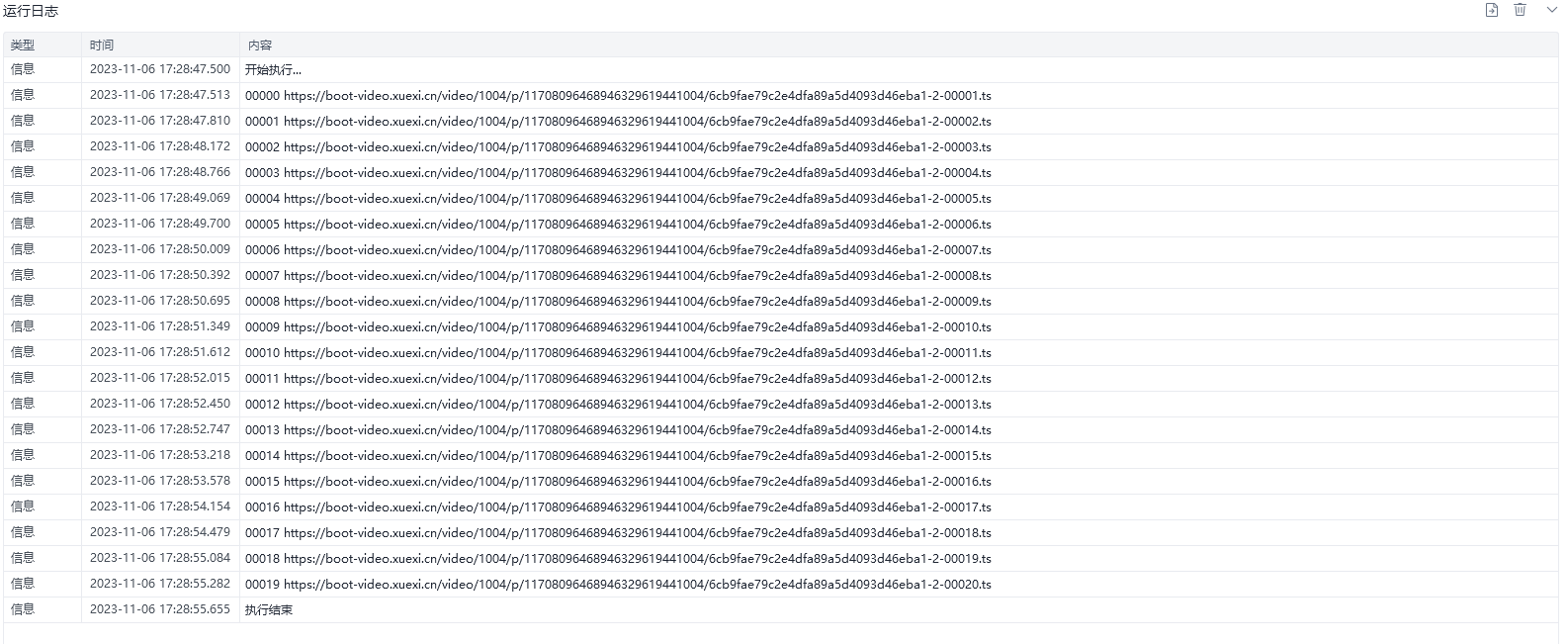
运行结果如下:
在下载路径中,多了一个同文件前缀的文件夹,文件夹中包含多个‘.ts’格式视频
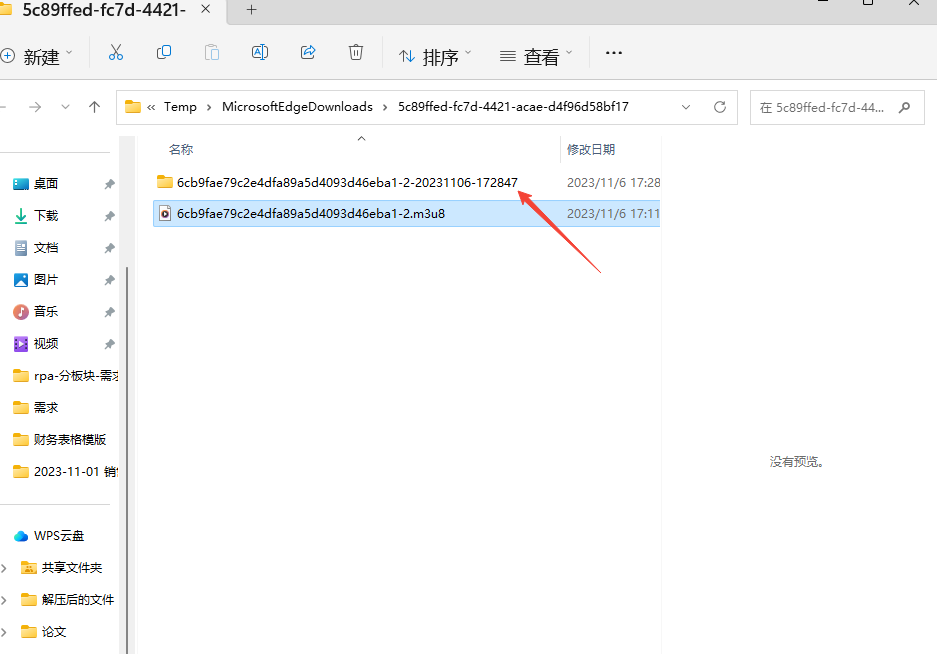
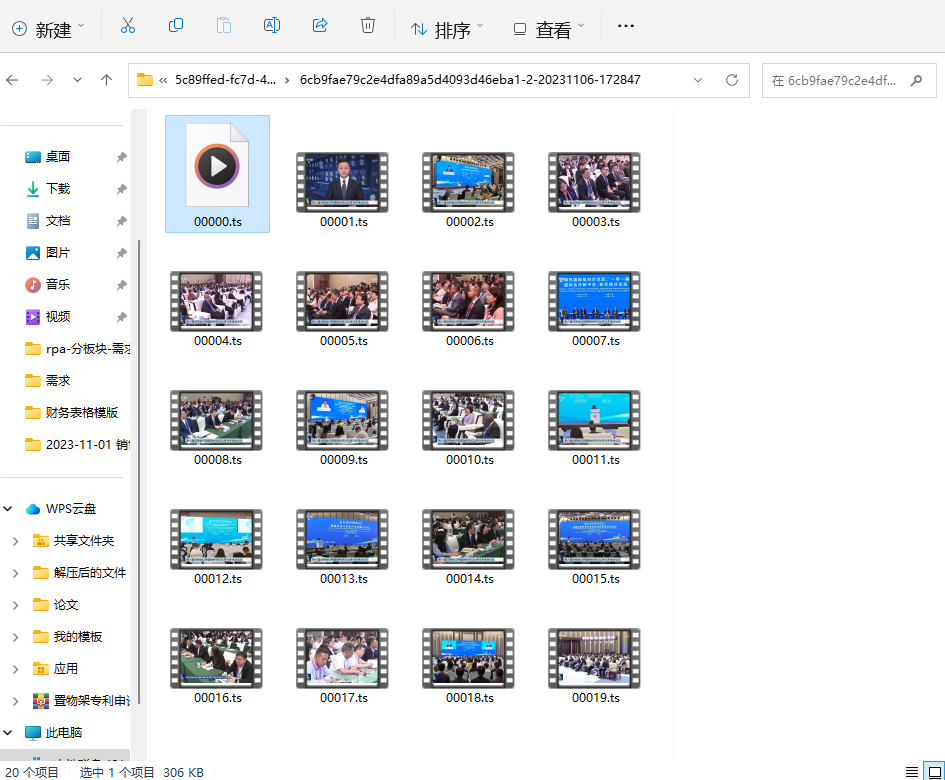
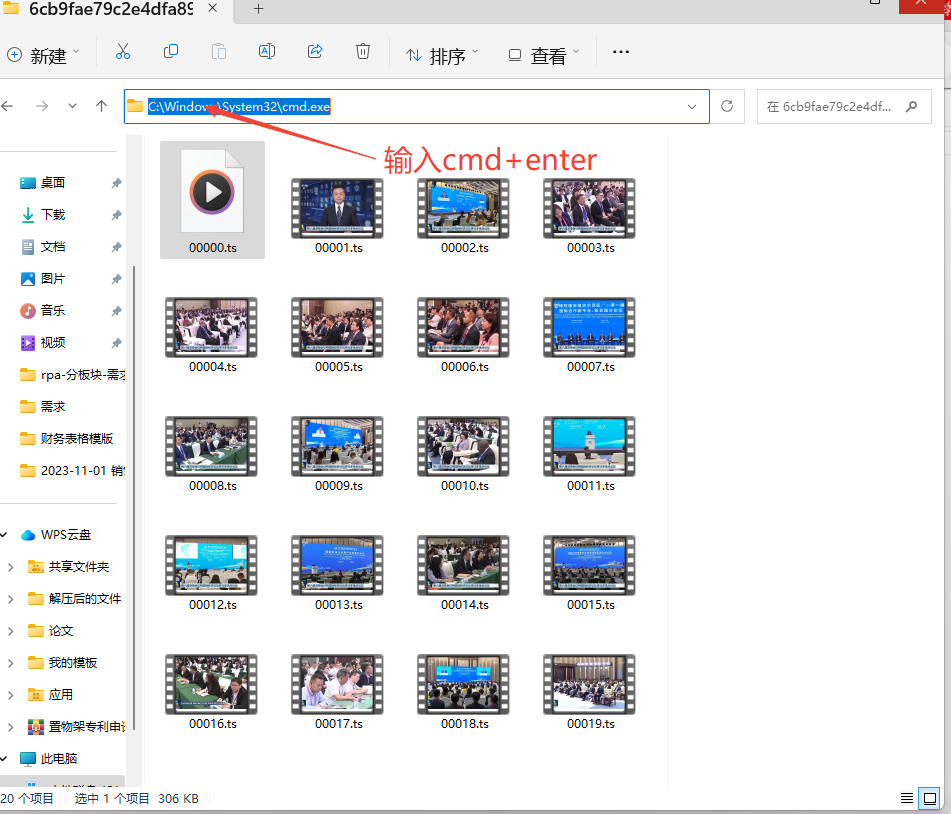
在弹窗中输入copy /b *.ts demo.mp4+enter
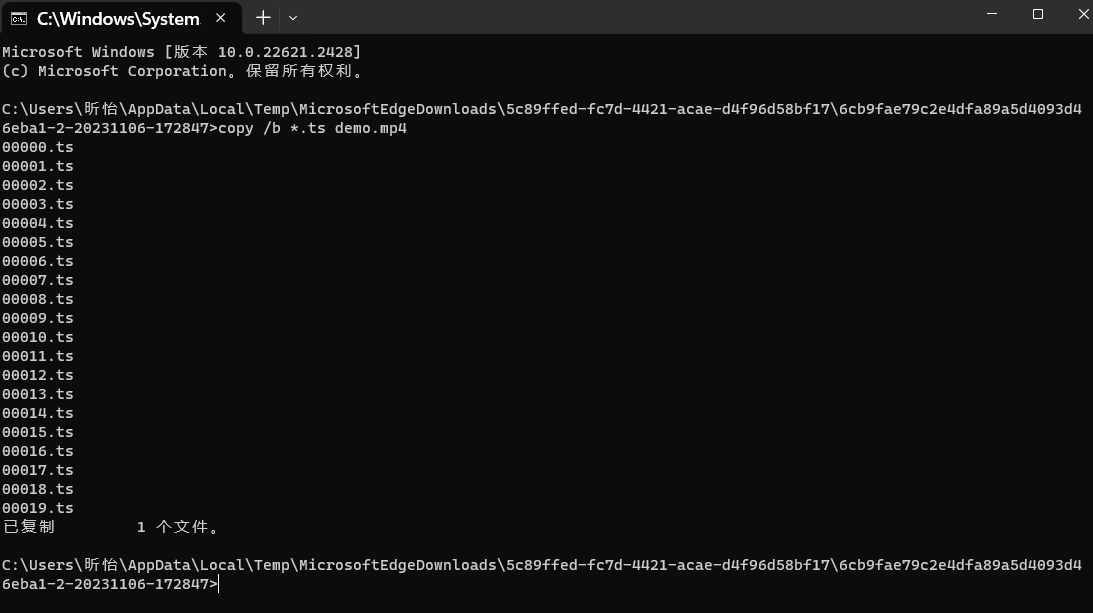
继续输入del *.ts+enter
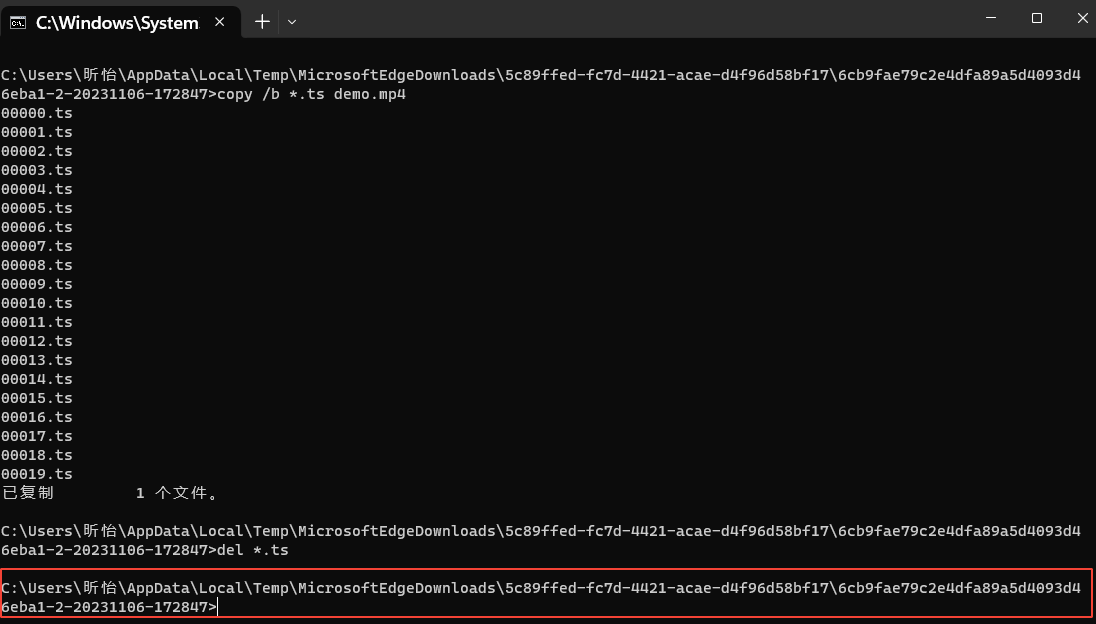
即可完成‘.m3u8’视频下载转换‘.mp4’,并生成视频所在本地文件夹路径
收藏7全部评论(1)
最新
发布评论
评论




