 收藏
收藏No.062-快速提取Excel嵌入图片
作者:昼夜
关键词:提取、Excel嵌入图片、解析
一、问题背景
在平常工作的过程中,大家肯定经常会遇到表格中带着图片的Excel文件,很多时候用户想要对于文件中大量的图片想要进行快速提取归档的话,会遇到我们的指令无法取到图片的情况。是因为很多时候遇到的图片都是嵌入形式的,从表格中直接提取的话只能获取到上传素材的ID,如果想要提取这些图片的话则需要更深层次的去拆解Excel文件,接下来就介绍一下如何可以快速的从Excel文件中提取到那些嵌入类型的图片。
二、解决方案
在Excel中,图片的类型大致分为两种:浮动型图片与嵌入型图片,对于浮动型图片我们可以直接使用到扩展指令中的【导出单元格图片】完成,但是嵌入型图片比较特殊,其并不是一个简单的内置操作。其实Excel文件是一个zip归档的集合,在文件的底层结构里面包含着多个XML文件,在这些文件里面定义了工作表的内容、格式、图片之间的关系,然后呈现出我们看到的Excel表格。
那既然底层结构里面带着图片以及工作表之间的关系,我们就可以直接通过解压到底层文件然后分析xml文件中给定的映射关系,得到对应单元格中图像ID与图像存储路径,再去进行提取。整体的操作逻辑如下:
1.解压Excel文件,得到底层文件
def get_files(file_path, extract_folder):
# 指定XLSX文件路径
xlsx_file = file_path
# 创建一个临时目录用于解压
os.makedirs(extract_folder, exist_ok=True)
# 解压XLSX文件
with zipfile.ZipFile(xlsx_file, 'r') as zip_ref:
zip_ref.extractall(extract_folder)
# 获取解压后的文件列表
extracted_files = os.listdir(extract_folder)
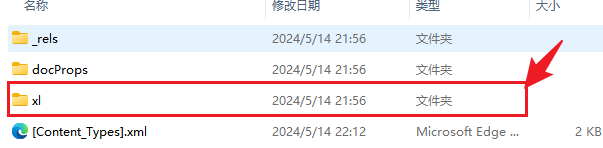
return extracted_files给定临时文件夹路径并解压文件,解压后会得到如下文件,其中xl文件夹里面的内容是我们需要分析的,内部的结构如下图所示。

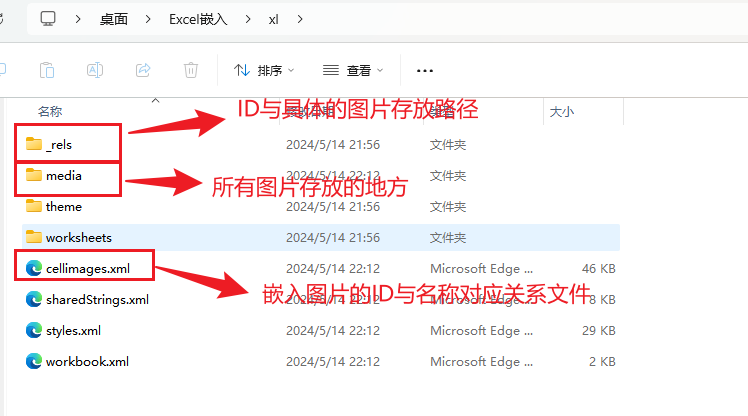
2.解析xml文档,从中获取图片的依赖关系并与sheet页中公式内容进行关联
cell images.xml

_rels中存放rid与图片路径的的cellimages.xml.rels文件
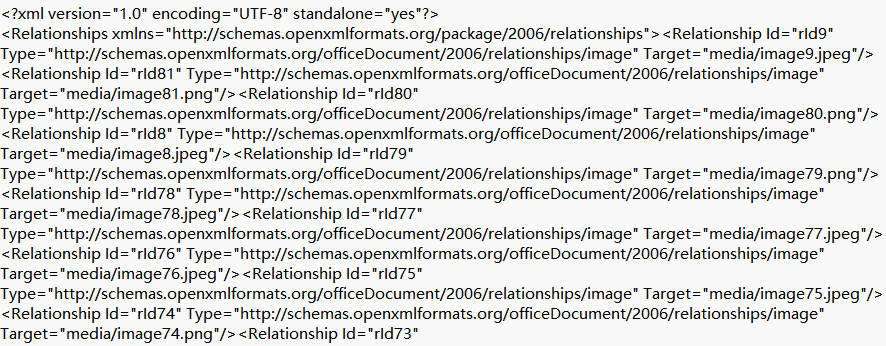
从这些关系中我们可以看到图片路径与rid之间的关系,可以使用到如下的代码来实现关系解析
# 提取Excel中嵌入的图片
def extract_excel_img(file_path):
res_dict = {}
CELLIMAGE_PATH = "xl/cellimages.xml"
archive = ZipFile(file_path, "r")
wb = load_workbook(file_path)
# 打开cellImage.xml文件,并进行解析_rel
src = archive.read(CELLIMAGE_PATH)
deps = get_dependents(archive, get_rels_path(CELLIMAGE_PATH))
image_rels = handle_images(deps=deps.Relationship, archive=archive)
node = fromstring(src)
cellimages_xml = parse_element(node)
for r_id, _obj in cellimages_xml.items():
res_dict[r_id] = image_rels[_obj]
archive.close() # 关闭压缩文件对象,防止内存泄漏
return res_dict当然在这里也创建了一些其他的函数来辅助解析,具体如下
# 解析XML,寻找并返回图片的相关信息
def parse_element(element):
data = {}
xdr_namespace = "{%s}" % SHEET_DRAWING_NS
targets = level_order_traversal(element, xdr_namespace + "nvPicPr")
for target in targets:
# 这里是cellimage
cNvPr = ""
embed = ""
for child in target:
if child.tag == xdr_namespace + "nvPicPr":
cNvPr = child[0].attrib["name"]
elif child.tag == xdr_namespace + "blipFill":
_rel_embed = "{%s}embed" % REL_NS
embed = child[0].attrib[_rel_embed]
if cNvPr:
data[cNvPr] = embed
return data
# 层次遍历,查找目标节点
def level_order_traversal(root, flag):
queue = [root]
targets = []
while queue:
node = queue.pop(0)
children = [child.tag for child in node]
if flag in children:
targets.append(node)
continue
for child in node:
queue.append(child)
return targets
# 将图片对应关系进行记录
def handle_images(deps, archive):
r_dict = {}
if not PILImage:
return r_dict
for dep in deps:
if dep.Type != IMAGE_NS:
msg = "【{0}】-图像格式不支持!".format(dep.Type)
print(msg)
continue
try:
image_io = archive.read(dep.target)
image = Image(BytesIO(image_io))
except OSError:
msg = "图像【{0}】无法读取!".format(dep.target)
print(msg)
continue
if image.format.upper() == "WMF":
msg = "【{0}】-图像格式不支持!".format(image.format)
print(msg)
continue
# 获取文件rId与文件地址
image.embed = dep.id
image.target = dep.target
r_dict[image.embed] = image.target
return r_dict
解析完成之后我们会得到一个json,其中键值是嵌入图片显示在页面上的ID信息,值是图片在解压出来底层文件中的存放路径,接下来循环这个json就可以提取到我们想要的图片。
{
'ID_638F22ADCB5A4CCF9872B797FDFCE575': 'xl/media/image1.jpg',
'ID_7DA1D7D02EAB4464912F1F1511CBA260': 'xl/media/image2.jpg',
'ID_B88CCECB4D9D4F24A050E6BF2EDD45EF': 'xl/media/image3.jpg',
'ID_CD1C0BFEBDFF47ECA6074064B8750649': 'xl/media/image4.jpg',
'ID_0AFC403CBA1644A6AC24B668AC314456': 'xl/media/image5.jpg',
'ID_E698EA1E38744C559A9FBC337A44FFEE': 'xl/media/image6.jpg',
'ID_E3735158E4CF4546AC79BCDC4F60825E': 'xl/media/image7.jpg',
'ID_36622723038A49FCB8F5EC1C9118ADCC': 'xl/media/image8.jpg',
'ID_4DBBA7F70FC74056B1DF151865F22757': 'xl/media/image9.jpg',
'ID_4A0244C4B5124184AF4576CBCBD327C0': 'xl/media/image10.jpg',
'ID_8A7FD43914984EC18A396659C83A420E': 'xl/media/image11.jpg',
...
}4.循环Excel,通过ID提取需要的图片进行存储
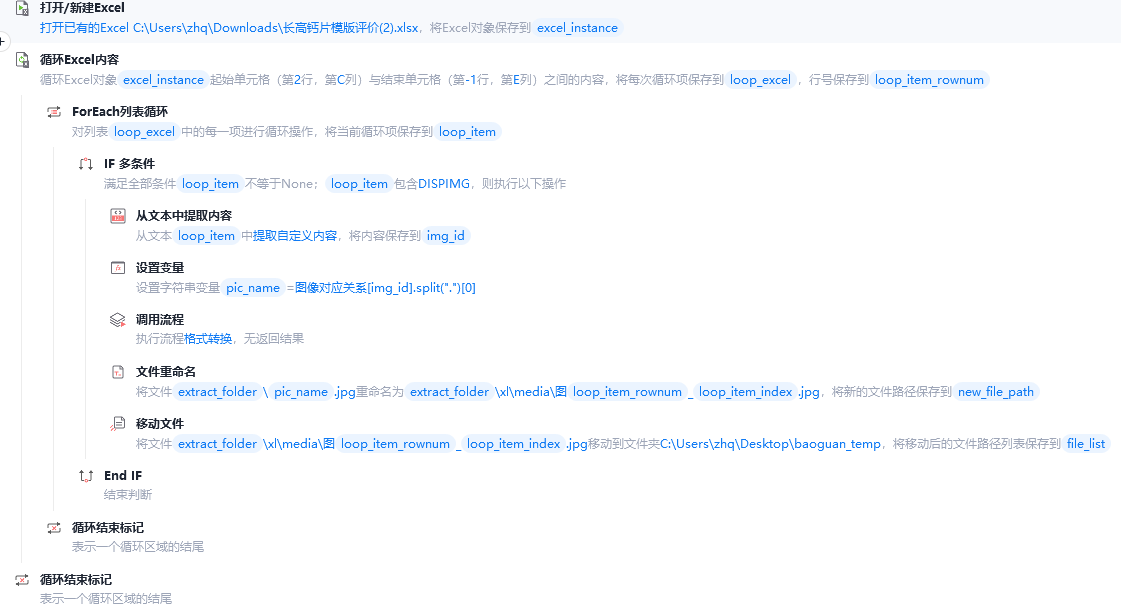
这样我们就可以将文件直接取出了,不再受嵌入类型的困扰~

三、效果展示
四、其他事项
有时候可能表格在制作的时候插入的图片类型会有多种多样的,在处理的时候最好将media文件夹中的图片格式转换成一样的再去执行,减少错误概率。
收藏8



