 收藏
收藏使用POP3读取邮件 --- by.深圳小分队
1. 读取发送邮件指令执行失败
1.1 场景介绍
客户的服务器ip归属地在美国,163邮箱服务器会限制部分美国ip,导致使用 imap协议获取邮件 和 smtp协议发送邮件 都报下方错误:
由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝武失败。
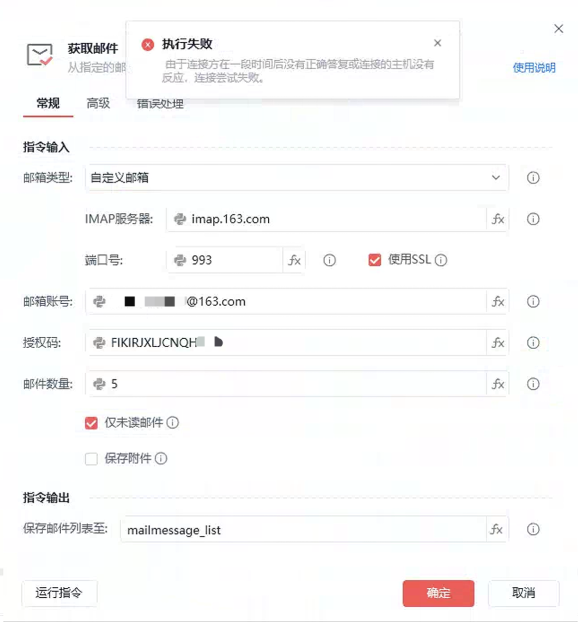
后面和该公司的IT沟通,更换连接策略,将163的相关协议走国内网络。
更换国内网络后,可以通过 smtp协议 正常发送邮件,但是imap协议的 993/143 端口都不通,pop3协议的995可以使用,所以后面使用pop3协议来获取邮件内容。
1.2 使用 telnet 测试网络端口
常用的方法: telnet IP port
telnet smtp.163.com 993 端口,如果端口没有开启监听则会显示连接失败,如下图:

telnet smtp.163.com 994 若端口有开启监听,telnet端口是通的会显示一个白色的光标并闪烁,如下图:

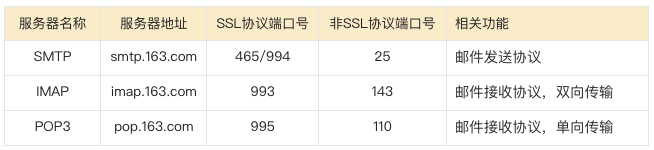
1.3 SMTP、IMAP和POP3服务器是什么意思?
SMTP、IMAP、POP3 都是邮件传输协议
1.3.1 SMTP协议
SMTP,英文全称“Simple Mail Transfer Protocol”,意思是“简单邮件传输协议”,这是一个相对简单的传输协议。
SMTP协议只支持发送邮件,不允许从服务器接收邮件。也就是说,这是一个“推送”的协议,不支持从远程邮件服务器“拉取”信息。
1.3.2 IMAP协议
IMAP,英文全称“Internet Message Access Protocol”,意思是“互联网信息存取通讯协议”、“交互式电子邮件存取协议”。和POP3一样,也是邮件访问标准协议之一。
与POP3协议不同的是,IMAP不仅可以接收邮件,同时在客户端上的所有操作,都会反馈到服务器端。比如,在Foxmail等客户端内对邮件进行移动整理、标记已读、彻底删除等,服务器中的邮件也同时产生相同的动作。也就是说,从邮件客户端、网页端登录看到的邮件及其状态,是完全相同的。
1.3.3 POP3协议
POP3,英文全称“Post Office Protocol – Version 3”,意思是“邮局协议第三版”,是规定个人电脑连接到Internet邮箱服务器和下载邮件的电子协议,用于将电子邮件从POP服务器端发送到客户端。
POP3只支持在Foxmail、Outlook等邮件客户端接收邮件,并存储到本地电脑中,同时将邮件从服务器删除(改进的POP3协议并不会删除服务器邮件)。该协议不支持对服务器进行操作,比如,在客户端内对邮件进行整理、移动、标记、删除等操作,不会反馈到服务器端。
1.3.4 操作图谱
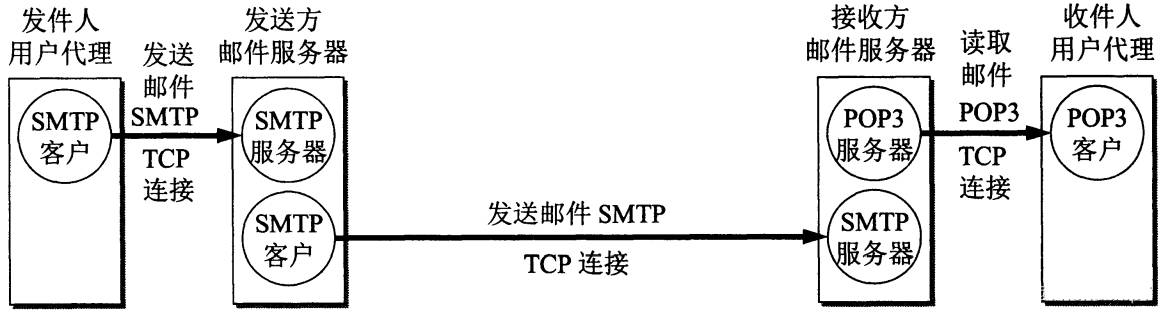
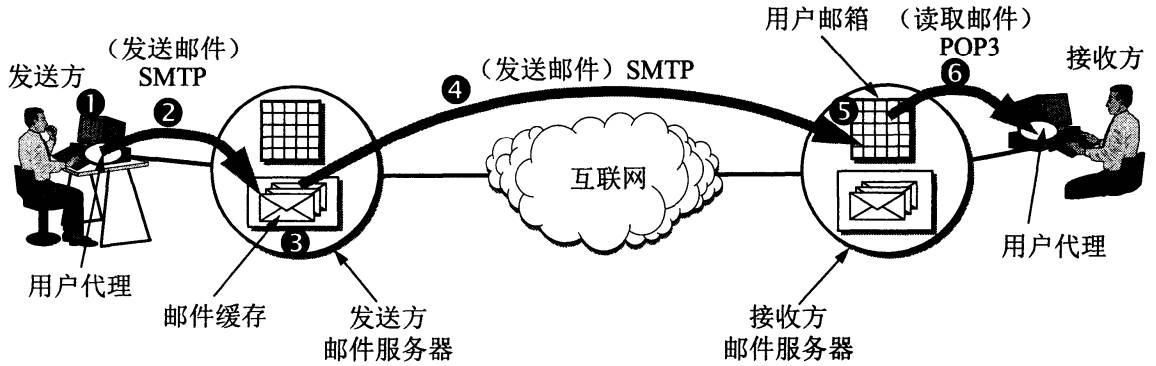
2. POP3读取邮件
目前影刀官方指令自定义邮箱只支持 imap 协议读取邮件,所以该功能需要自己编写python代码
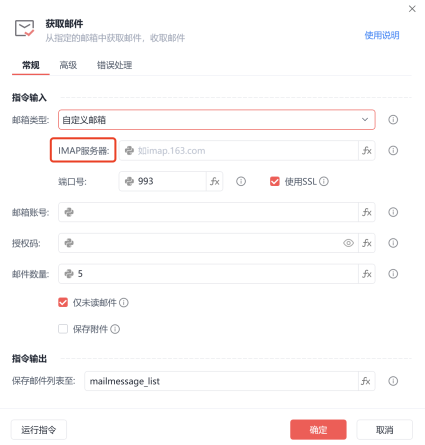
2.1 相关自定义指令
2.1.1 指令名称

2.1.2 指令模块ui界面
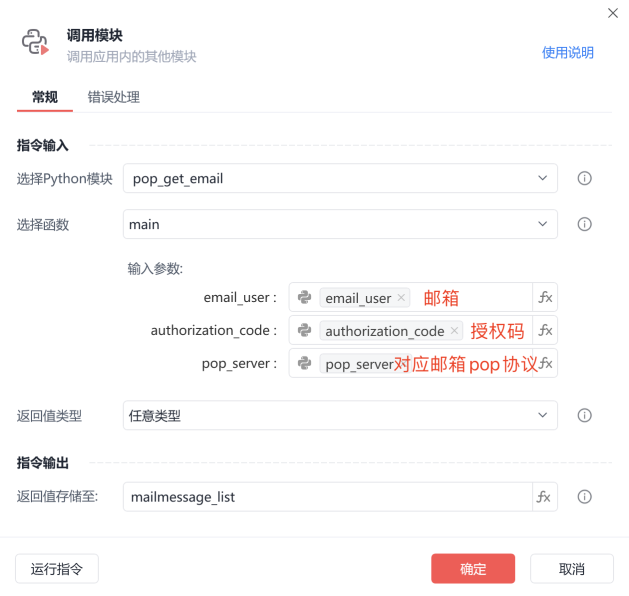
2.1.3 python代码
```
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import poplib
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
# 获取邮件原始文本
def get_origin_text(pop_server, email_user, authorization_code):
# 改成自己邮箱的pop服务器;qq邮箱不需要修改此值
pop_server_host = pop_server
# 邮箱对应的pop服务器的监听端口。改成自己邮箱的pop服务器的端口;qq邮箱不需要修改此值
pop_server_port = 995
# 连接到POP3服务器
pop_server = poplib.POP3_SSL(host=pop_server_host, port=pop_server_port, timeout=10)
# 邮箱号
pop_server.user(email_user)
# 授权码
pop_server.pass_(authorization_code)
# stat()返回(邮件数,邮件尺寸)
# print('邮件数: %s. 邮件尺寸: %s' % pop_server.stat())
# list()返回所有邮件的编号列表,默认返回20个元素
resp, mails, octets = pop_server.list() # 编号最大的为最新的一封
# 获取最新的一封邮件(索引号从1开始)
index = len(mails)
# print(index)
resp, lines, octets = pop_server.retr(index) # 返回(状态信息,邮件,邮件尺寸)
# lines存储了邮件的原始文本的每一行,可以获得整个邮件的原始文本
msg_content = b'\r\n'.join(lines).decode('utf-8') # b表示:后面字符串是bytes类型。
msg = Parser().parsestr(msg_content)
# 退出连接
pop_server.quit()
return msg
def decode_str(s): # 解码字符串
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
def set_charset(msg): # 设置字符集
charset = msg.get_charset() # 获取字符集
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
def parse_msg(msg):
# 解析邮件头
for header in ['From', 'To', 'Subject']: # 遍历获取发件人,收件人,主题的相关信息
value = msg.get(header, '') # 获取邮件头的内容
if value:
if header=='Subject': # 获取主题的信息,并解码
value = decode_str(value) # 解码字符串
else:
hdr, addr = parseaddr(value) # 解析字符串中的邮件地址
name = decode_str(hdr) # 解码字符串
value = '%s <%s>' % (name, addr)
# 解析邮件正文
if (msg.is_multipart()):# 如果消息由多个部分组成,则返回True
parts = msg.get_payload() # 返回一个包含邮件所有的子对象的列表
for n, part in enumerate(parts): # 枚举,遍历各个对象
# print('part %s' % (n))
parse_msg(part)
else:
content_type = msg.get_content_type() # 获取邮件信息的内容类型
if content_type=='text/plain' or content_type=='text/html': # 如果是纯文本或者html类型
global content # 声明全局变量
content = msg.get_payload(decode=True)# 返回一个包含邮件所有的子对象(已解码)的列表
charset = set_charset(msg) # 设置字符集
if charset: # 字符集不为空
content = content.decode(charset) # 解码
def main(email_user, authorization_code, pop_server):
msg = get_origin_text(pop_server, email_user, authorization_code) # 第一步:用 poplib 获取邮件的原始文本。
parse_msg(msg) # 第二步:用 email 解析原始文本,还原为邮件对象。
return content```
收藏2



