 收藏
收藏No.096-Pc端抖音视频下载的一些方法
作者:昼夜
关键词:Pc端、抖音、下载
一、问题背景
在传媒类型的公司,有大量自生产内容,这些内容从引流到带货转化都有很大作用,但各平台会存在一些模仿甚至直接搬运内容的账号,这些非合作侵权账号,需要及时找出侵权内容,并做出应对,减少后续的损失。所以在这个场景下,从抖音端将视频下载下来再进行对比巡检的步骤则显得非常重要了,并且Pc端抖音在经过几个版本的更新后,之前的下载方式已不太适用。那么在本文中将会介绍一些Pc端抖音视频下载的方法。
二、解决方案
例如我们要对这一用户发布的视频进行巡检,那么我们可以先进入到用户的主页中,这边集中了用户发布过的所有的视频,接着我们可以就这一页面上的视频对几种下载方式来进行介绍。
1.Http请求
通过逐个点击查看视频URL和在浏览器中对于记录视频数据相关包进行分析可以知道,一个视频的详细URL的结构就是由用户主页的URL+单个视频的modal_id(即在数据包中可以获取到的视频aweme_id)。通过GET请求这个视频详细URL,可以得到关于视频的一些详细信息(其中包括视频下载的链接),那么有了这些信息之后,就可以总结出操作步骤如下:
1.获取网页URL+根据监听得到的aweme_id拼接视频URL
2.去get请求【1】中得到的URL,得到下载的URL
3.请求【2】中得到的下载URL,完成视频的下载
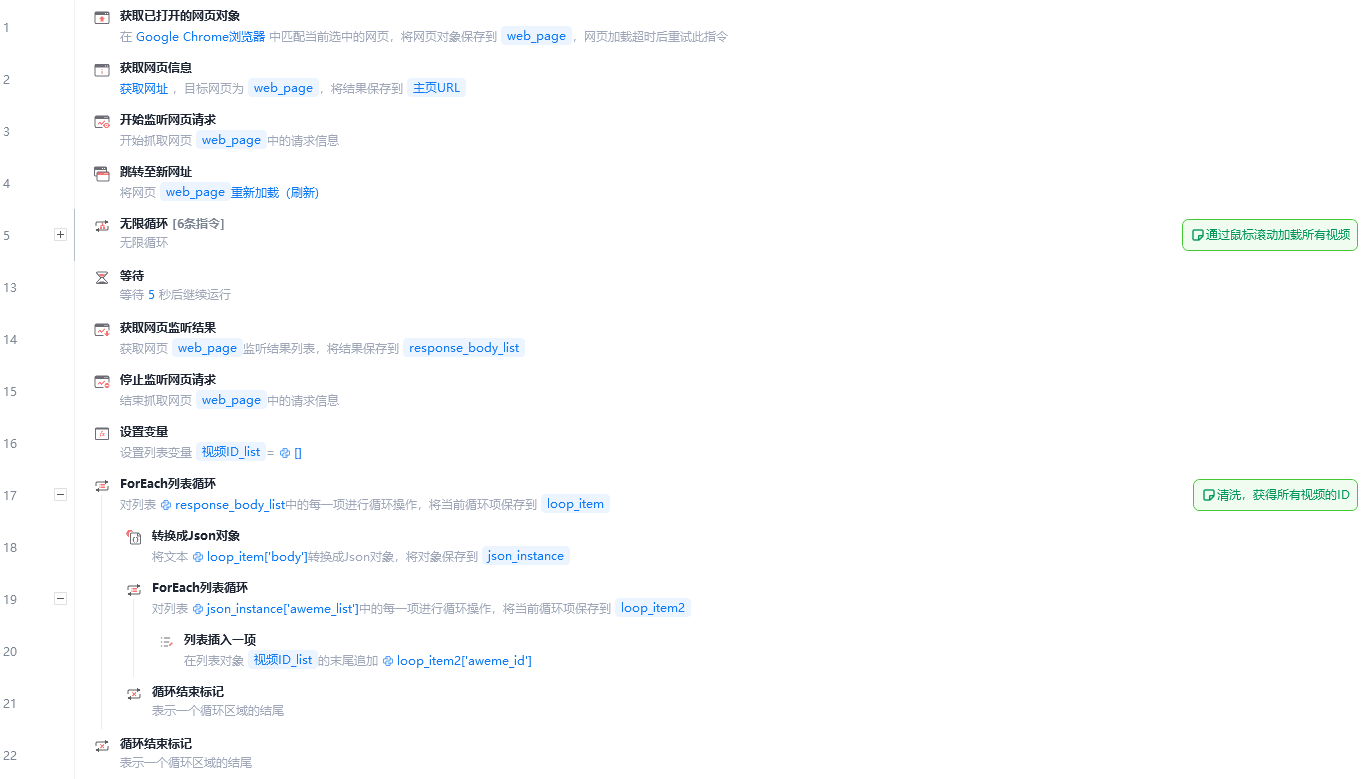
那么将这些关键步骤转换成影刀的操作逻辑,大致可以分成以下几步:
1.监听获取视频aweme_id,加上获取的网页URL拼接生成视频的链接URL
2.从网络包中拷贝/user/...包下的cURL路径,使用HTTP请求进行获取
3.对于请求返回的参数进行清洗获取下载的URL
4.使用代码进行下载
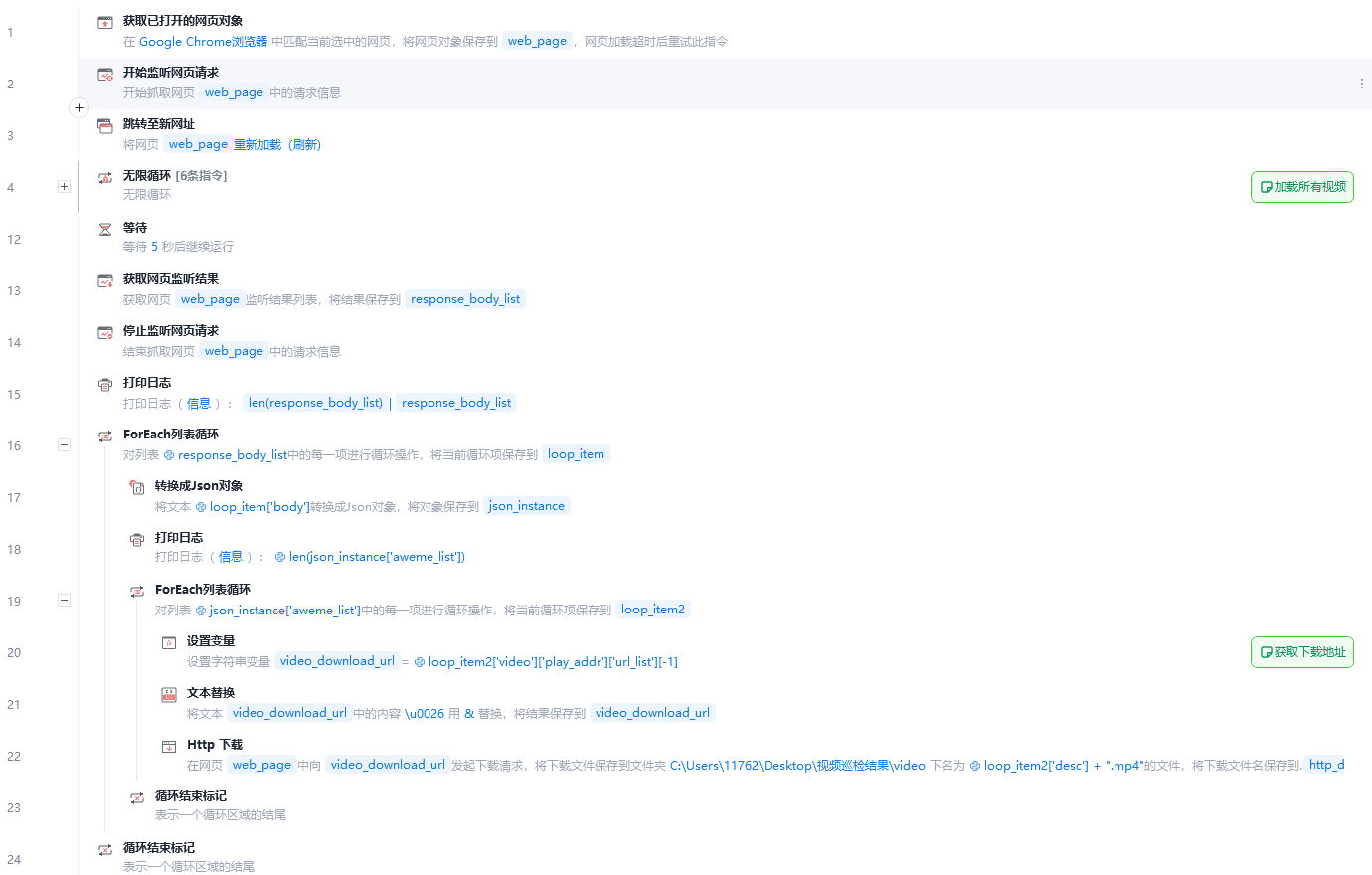
影刀中的流程如下:
 \
\
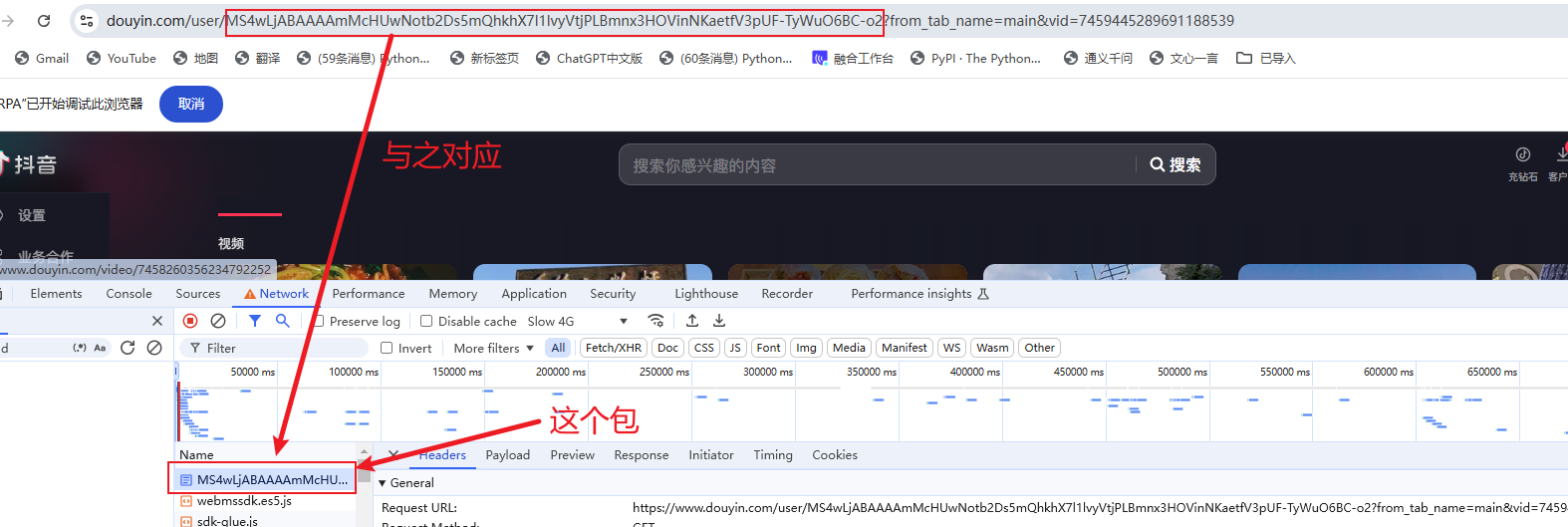
这边有一些要注意的点,首先是26行中的HTTP指令的设置,我们可以在进入用户主页之后,通过F12打开开发者工具,进入Network一栏之后刷新页面,找到第一个加载出来的包,这个包是以用户主页URL中的一段内容来命名的,直接点击这个包右键,拷贝cURL粘贴到指令中然后替换URL配置即可,协议头中自动填充的cookie具有较长时间的有效性,且不会因为下载其他用户主页的视频而失效。
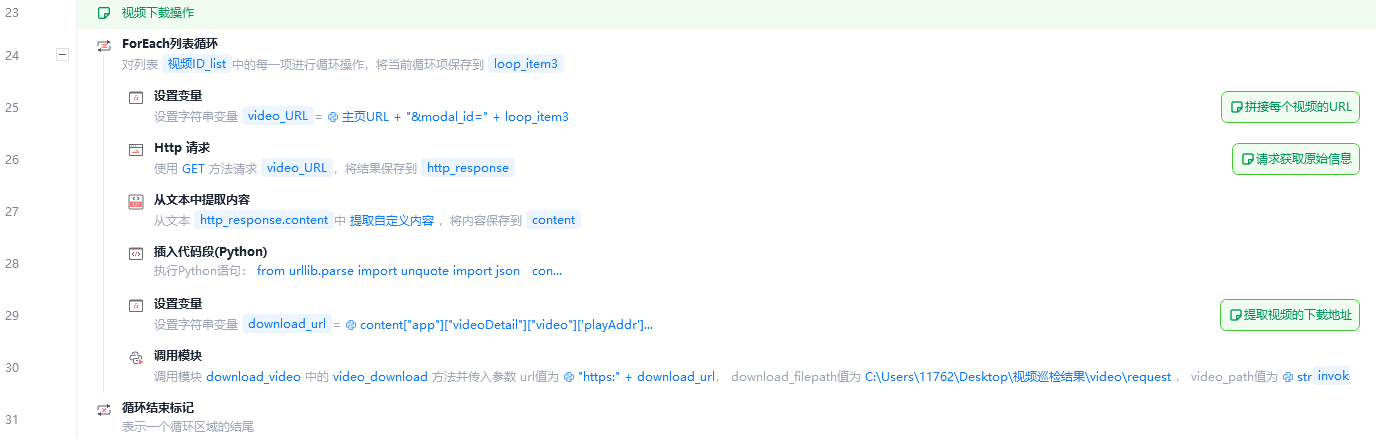
30行调用模块下载视频的代码如下:
def video_download(url, download_filepath, video_path):
headers = {
'Referer': 'https://www.douyin.com/',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
}
response = requests.get(url, headers=headers, stream=True)
if response.status_code == 200:
full_path = os.path.join(download_filepath,video_path)
with open(full_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print(f"视频{video_path}已下载完成")
else:
print(f"视频{video_path}下载失败!")2.监听获取(更简洁易上手)
通过对于网络请求数据包的分析,我们可以发现,在存放aweme_id的包中,还存着一些其他视频相关的信息,对于这个包进一步进行分析,就可以知道,一个视频所有现在基本上都是存放在这个包中的(现版本的逻辑是这样的),具体格式如下图。

而在这个数据包的“video”中,存放着视频播放的一系列数据,其中“video['play_addr']['url_list']”中存放的链接,则是视频的存放地址,同样也包含我们要找的视频下载链接,在下面这个list中,以“https://www.douyin.com”开头的就是视频的下载URL(一般都是在最后一项)
"url_list": [
"https://v3-web.douyinvod.com/64607b50b32ef5414359376a1944f72a/678e2aca/video/tos/cn/tos-cn-ve-15c000-ce/oEijnX3zwAiCEmUSi0xeierCe4HPEYAuAkCwIB/?a=6383\u0026ch=10010\u0026cr=3\u0026dr=0\u0026lr=all\u0026cd=0%7C0%7C0%7C3\u0026cv=1\u0026br=2667\u0026bt=2667\u0026cs=0\u0026ds=4\u0026ft=pEaFx4hZffPdqK~-I1jNvAq-antLjrKW2bcNRkaQKVERejVhWL6\u0026mime_type=video_mp4\u0026qs=0\u0026rc=Mzk5OTU1NzQ3ODo2aTxkM0BpMzkzZm45cm50eDMzbGkzNEBjNTBjM15gXjYxLS8wLV8vYSMuMjVmMmQ0MzBgLS1kLWJzcw%3D%3D\u0026btag=c0000e00030000\u0026cquery=101r_100B_100x_100z_100o\u0026dy_q=1737359049\u0026feature_id=46a7bb47b4fd1280f3d3825bf2b29388\u0026l=202501201544091A8FB150D827F6042F28",
"https://v26-web.douyinvod.com/7ca3f862e79698414d7e22f021c67d3c/678e2aca/video/tos/cn/tos-cn-ve-15c000-ce/oEijnX3zwAiCEmUSi0xeierCe4HPEYAuAkCwIB/?a=6383\u0026ch=10010\u0026cr=3\u0026dr=0\u0026lr=all\u0026cd=0%7C0%7C0%7C3\u0026cv=1\u0026br=2667\u0026bt=2667\u0026cs=0\u0026ds=4\u0026ft=pEaFx4hZffPdqK~-I1jNvAq-antLjrKW2bcNRkaQKVERejVhWL6\u0026mime_type=video_mp4\u0026qs=0\u0026rc=Mzk5OTU1NzQ3ODo2aTxkM0BpMzkzZm45cm50eDMzbGkzNEBjNTBjM15gXjYxLS8wLV8vYSMuMjVmMmQ0MzBgLS1kLWJzcw%3D%3D\u0026btag=c0000e00030000\u0026cquery=100B_100x_100z_100o_101r\u0026dy_q=1737359049\u0026feature_id=46a7bb47b4fd1280f3d3825bf2b29388\u0026l=202501201544091A8FB150D827F6042F28",
"https://www.douyin.com/aweme/v1/play/?video_id=v1e00fgi0000cu3q6k7og65kic805610\u0026line=0\u0026file_id=20ba093f23074594a1c4a262f63686f0\u0026sign=e399d11971fed55b80786887363d68b5\u0026is_play_url=1\u0026source=PackSourceEnum_PUBLISH"
]那么我们可以梳理影刀流程大致如下:
1.进入用户主页,监听获取数据包(监听url:https://www.douyin.com/aweme/v1/web/aweme/post/device_platform=webapp&aid=6383&channel=channel_pc_web&sec_user_id=*)
2.从数据包中取出“url_list”,并获取list中最后一项
3.将链接中的\u0026替换为&,得到下载链接
4.使用http下载指令进行下载
三、效果展示
这里以Http请求作为演示
四、其他事项
1.在Http请求下载方式中,当我们通过GET请求了视频URL之后,返回的是URL编码,不是能够直接进行下载的链接,所以需要进行转义,转义代码如下
from urllib.parse import unquote
import json
content = unquote(content)
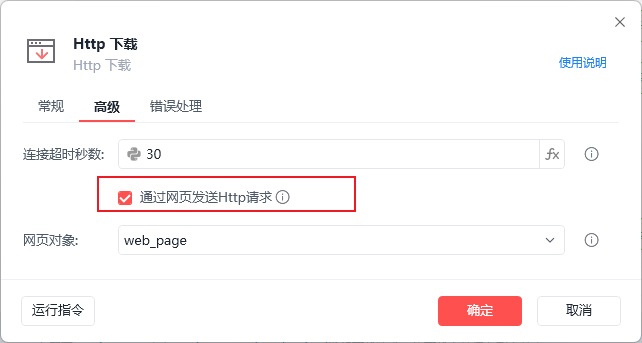
content = json.loads(content)2.在使用Http请求进行视频下载操作时也可以【Http下载】指令进行下载,但是需要注意要勾选“通过网页发送http请求选项”,否则会提示403错误。
3.*个人比较建议使用监听的方法,简单易上手*(写的不好,仅供参考~)
收藏14



