 收藏
收藏如何优化流程提高数英验证码的准确率

一、背景简介
1-1 业务背景
客户每天都需要进入到这个财资管理云系统进行相关的一些业务操作,整个流程客户已经开发好了,登录后在网页也能较为稳定运行。但在登录环节,偶尔会因为验证码识别不准确导致不断重试,从而使应用失败终止,未能运行后续的指令。
- 对应公网地址:https://cbscloud.cmbchina.com/
1-2 业务痛点
数英验证码的识别率不高,偶尔会出现识别不准确,需重试多次。
1-3 适用客户类型
登录过程中需使用数英验证码识别的客户。
二、需求详解
- 大致测出三个验证码识别的准确率(通用数英、通用数英plus、ddddocr)
- 比对验证码的识别率得出差异,通过流程设计来提高验证通过率
三、实现流程
3-1 业务细节说明
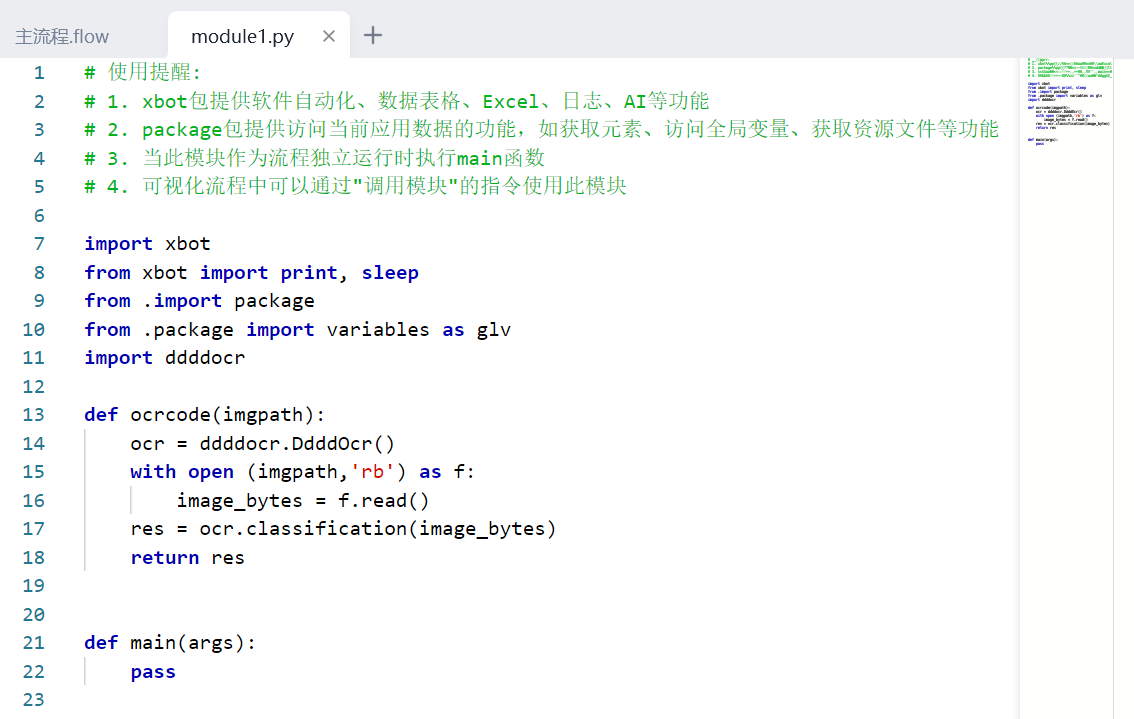
1)基于300个验证码,用通用数英、通用数英plus、ddddocr三种识别方法分别识别,得出结果写入excel。
代码截图:
- 主流程:

- ddddocr模块:
- 详细ddddocr使用方法参考 : 免费验证码识别(旧贴新开)-经验分享-影刀RPA开发者社区
PS:使用ddddocr除了能通过代码来实现,还可以直接用魔法指令生成!!!一条指令就能简化编写代码以及调用模块的步骤
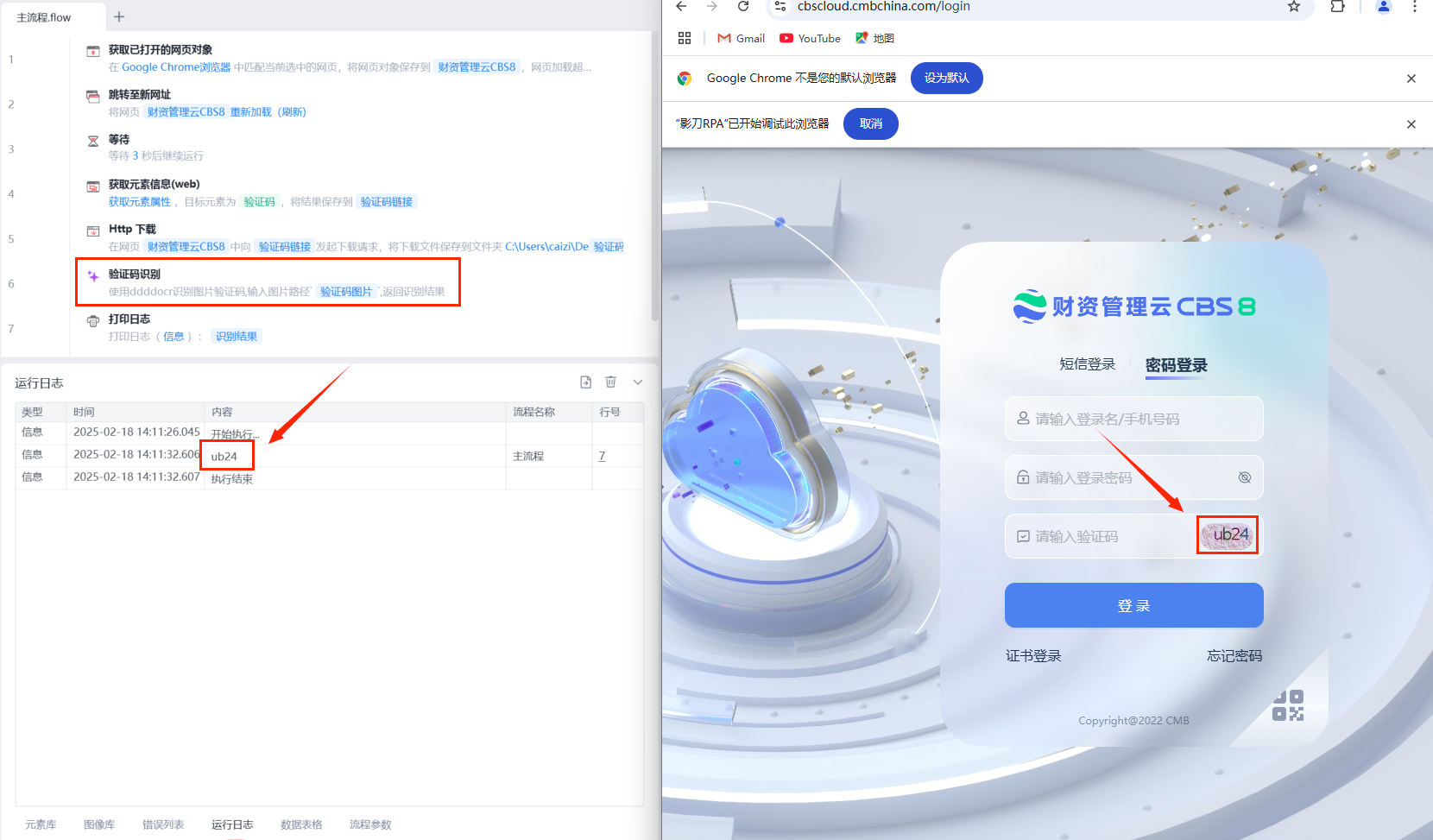
2)人工识别正确答案,再写指令对比识别结果与正确答案,统计识别率。
- excel表部分内容:
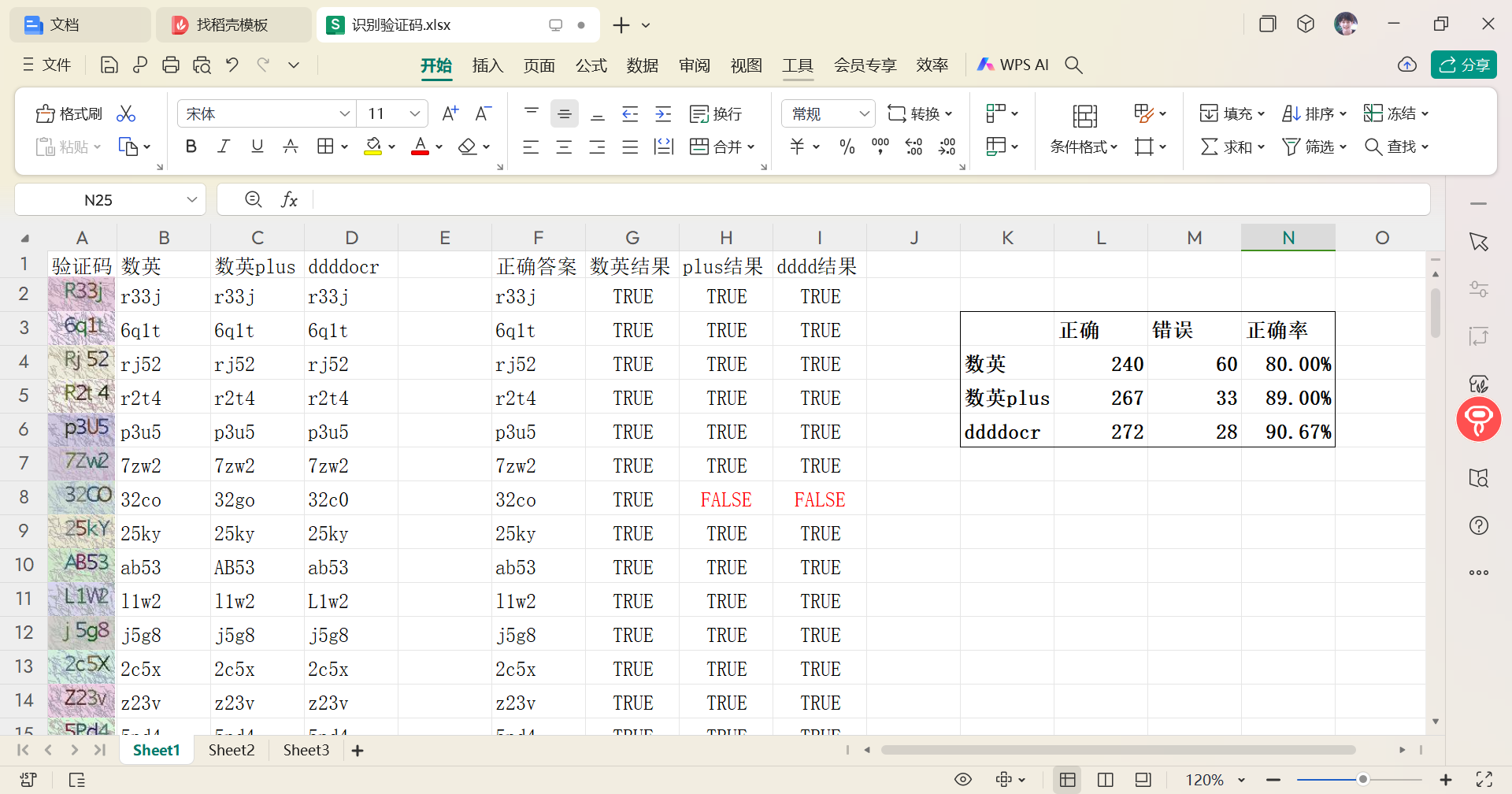
根据三种不同的验证识别的结果,统计出对应的正确率。其中ddddocr的识别正确率最高,为90.67%;其次是数英plus,为89.00%;数英的正确率最低,只有80.00%。对比识别结果发现,若验证码中包含O、0、l、G,就很容易识别错误,识别效果较低。
- excel链接:识别验证码.xlsx
3-2 具体实现方法
那么在无法提高验证码识别指令准确率的情况下,怎么才能使得识别结果更准确呢?
识别失败的情况,目前可以分为两种情况:
(1)一种是由于某些字符的相似性导致的识别错误。
(2)另一种则是直接识别不到导致的字符缺失,从而使识别结果长度不符。
基于这种情况,可以采取一些绕行方法、做一些策略回避:
(1)由于验证码带O、0、l、G特别容易被混淆,那么将带有这些字符的验证码排除在外,不识别这种验证码,直接从根源上解决问题。
(2)基于字符缺失的问题,就可以先判断获取到的验证码长度是否为4,再进行后续的操作。
综上所述,具体流程就是:先识别验证码的长度,判断长度是否等于4且识别结果是否包含O、0、l、G字符。是的话就刷新页面重新获取验证码,否则就直接识别。流程图如下图所示。
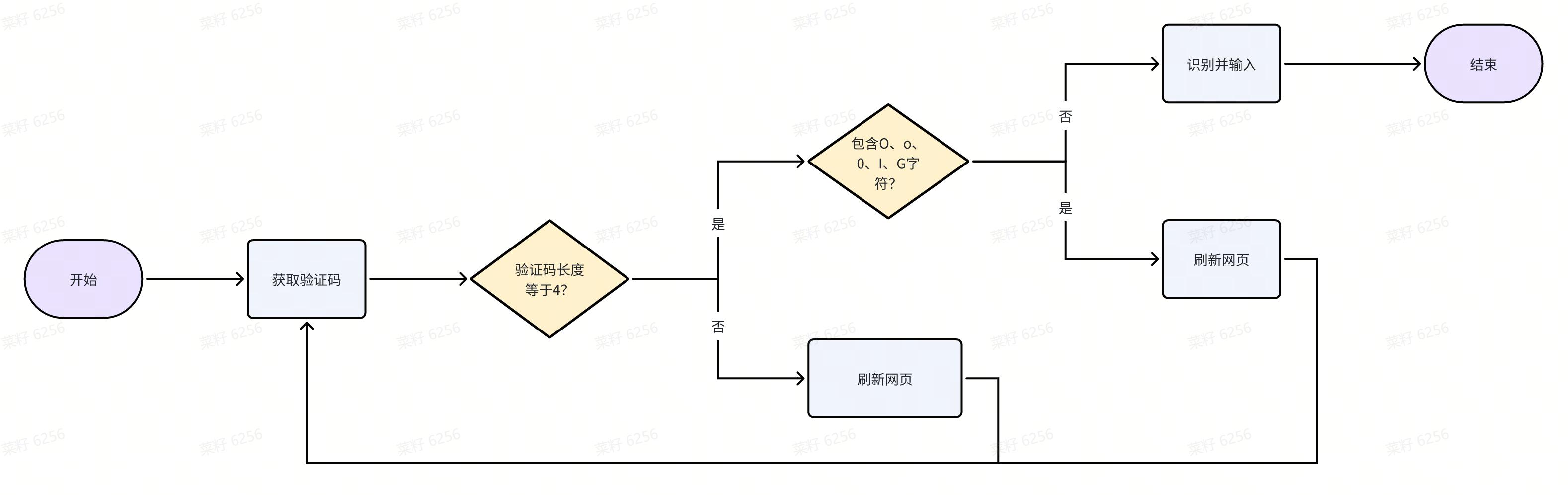
3-3 实现效果
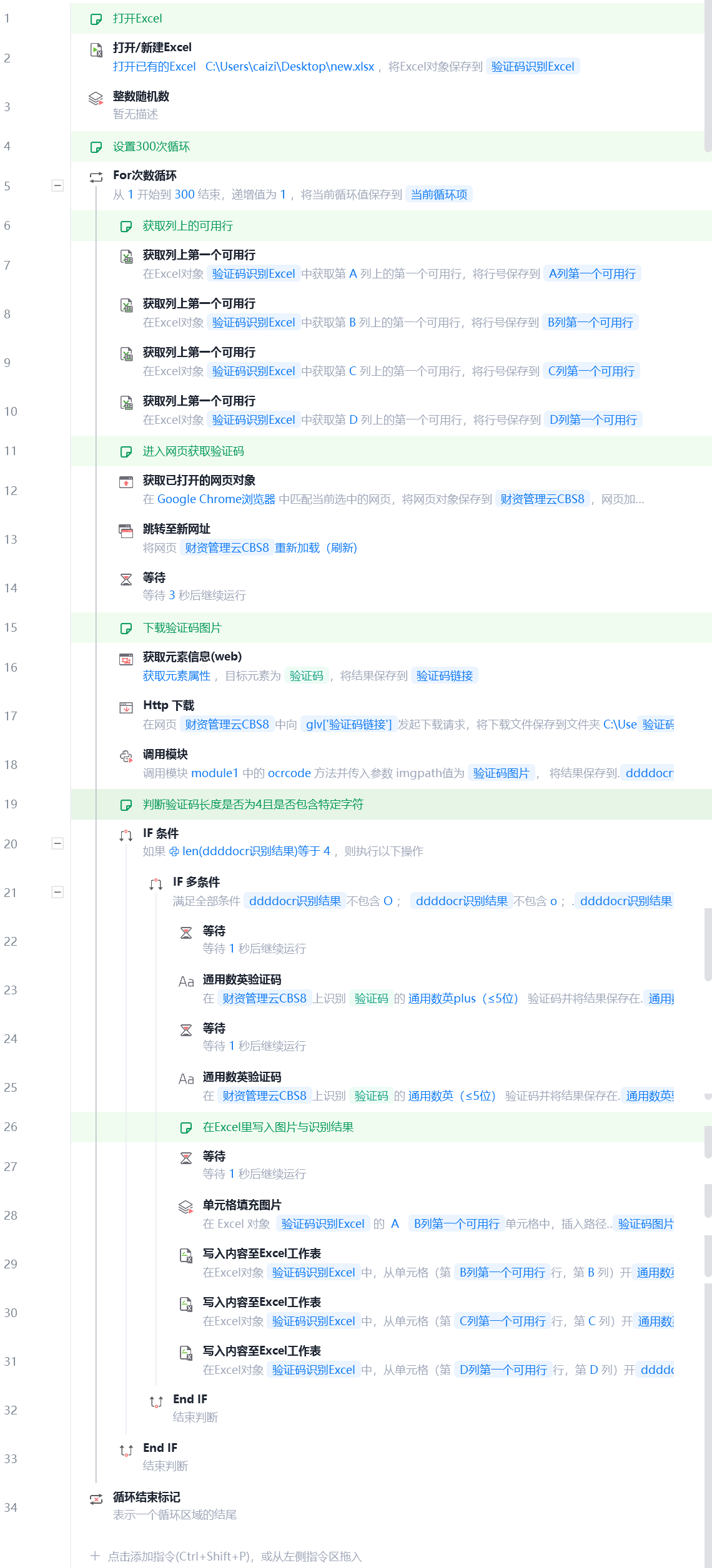
代码截图:
- 主流程:
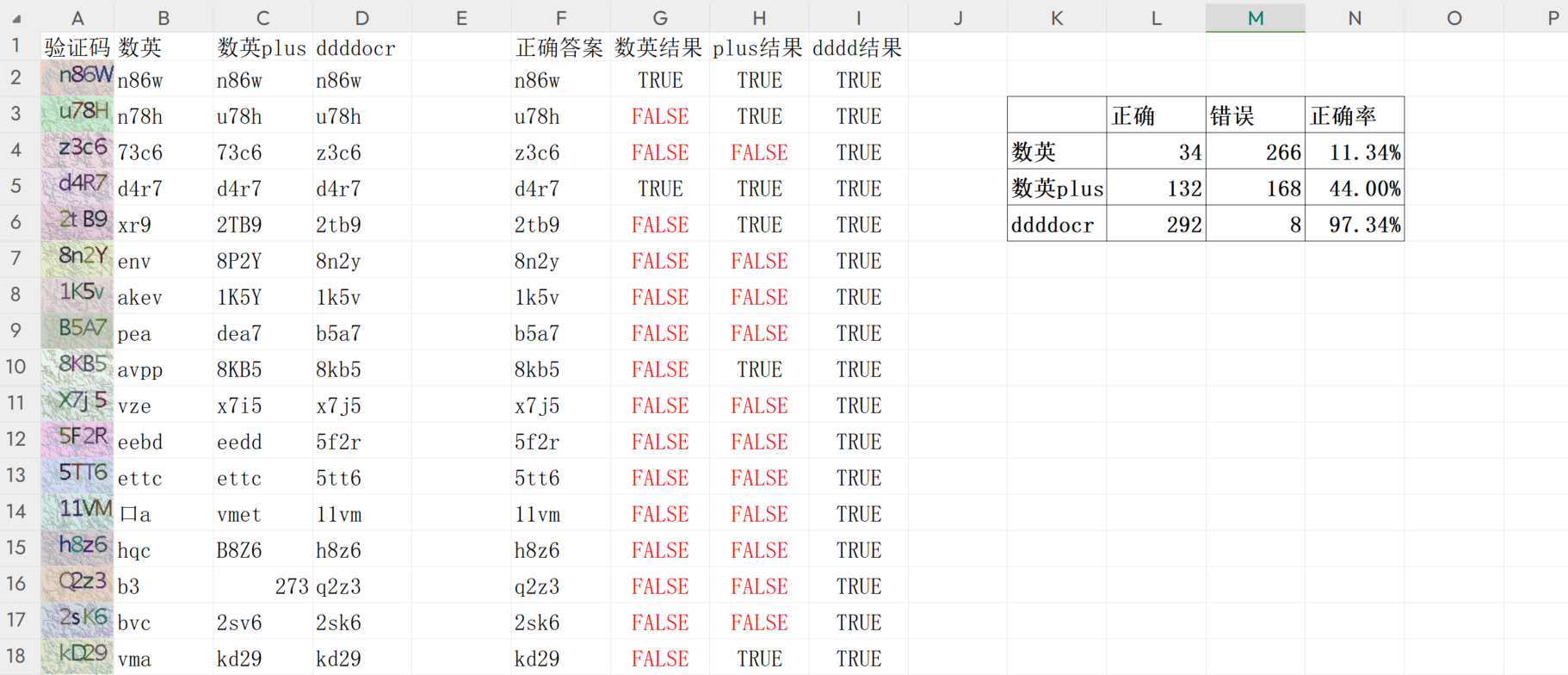
- excel表内容:
- excel链接:识别验证码(优化后).xlsx
第二次测试中,数英和数英plus的验证效果都大幅度下降。即使识别单独识别一个验证码,也大都识别错误,应该是数英验证码本身的问题,导致识别率突然下降。因此暂时忽略数英、数英plus这两个识别方法,仅用ddddocr作为参考。
由上图可见,流程优化后的ddddocr识别率为97.34%,与之前的90.67%相比,正确率提高了近7%。因此,在验证码本身识别率不高的情况下,可以通过优化流程的方式,排除一些易混淆字符,再对其识别,能有效提高验证通过率。
收藏6



