逆向案例 -- 淘宝关键词数据采集:sign解析与代码应用 收藏
收藏
评论
收藏逆向案例 -- 淘宝关键词数据采集:sign解析与代码应用

2025-02-18 17:58·浏览量:2685
RPA梦工厂
 影刀专家
影刀专家关于淘宝数据采集的说明
在使用关键词搜索采集淘宝数据时,很显然,数据是经过加密处理的。至于如何寻找接口并进行分析,网上有很详细的教程,感兴趣的可以点击** 这里 **查看。
虽然网上教程众多,但似乎很少有可以直接使用的代码。因此,这里直接提供自己编写的代码,方便大家直接复制粘贴使用。
关键参数说明
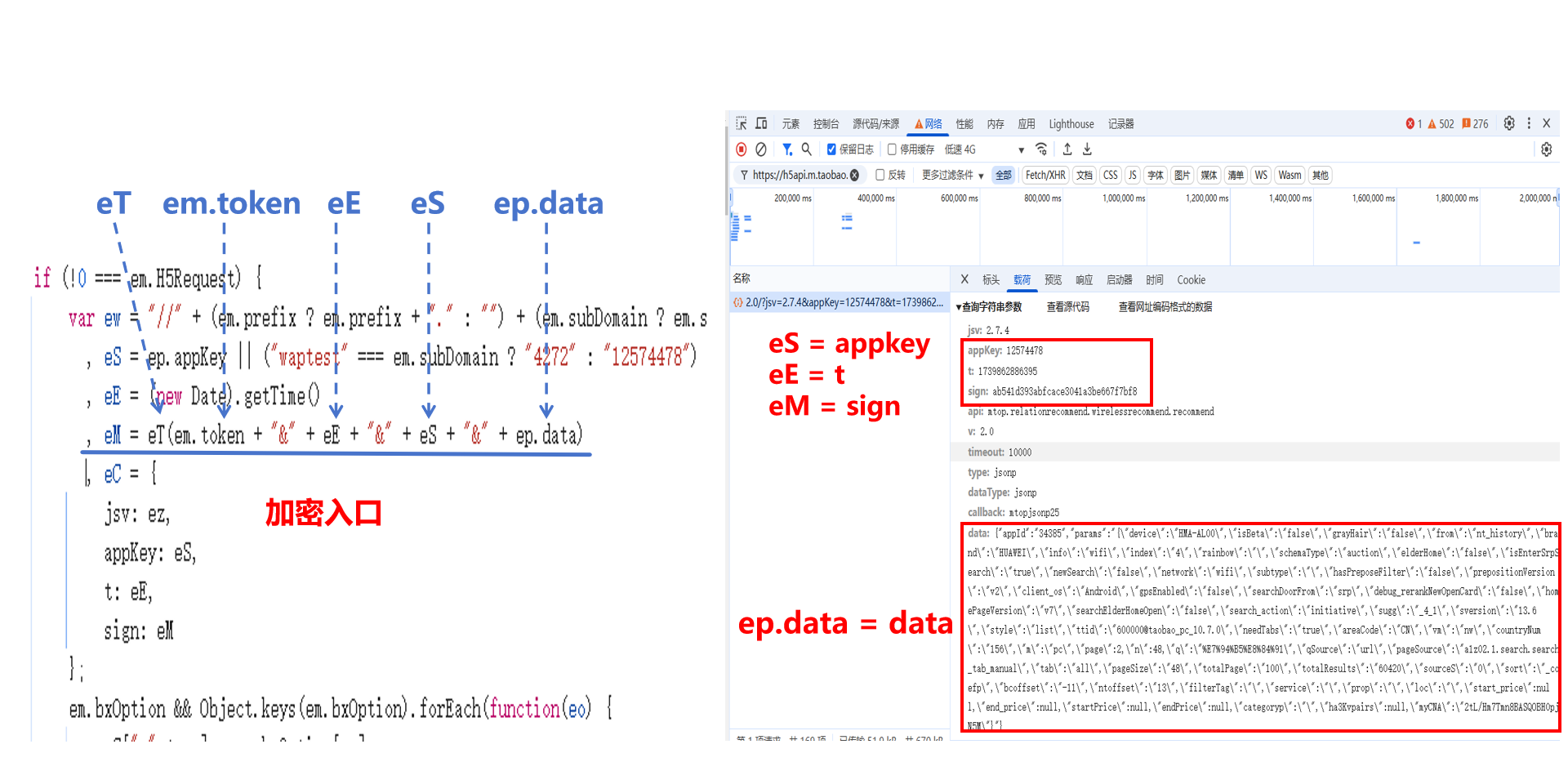
在进行加密接口的逆向分析时,需要以下参数:
- eT:加密方法,采用MD5加密方式。对于淘宝数据采集,无需补环境,直接使用相关库即可。
- em.token:这是一个固定值,来源于cookie中的一个参数。只要cookie保持不变,该值也不会改变。在编写代码时,一开始以为这个值是一直不变的,不管刷新还是怎么都没有改变。测试时,发现前一段时间程序可以使用,过一段时间就报错了。看了网上很多教程,以为是自己写错了,导致**sign参数加密一直错误**,后面发现这个值是根据cookie变化的。
- eE:毫秒时间戳。
- eS:固定值,对应F12开发者工具中的appkey。
- ep.data:请求所需的参数,包括搜索关键词、页码、排序方式、价格范围等。上传的参数需要自定义修改,想法是先变成json格式,方便修改。但是改了很多次,发现转成字符串的时候,多一个空格生成的sign就是错误的,导致非法请求。
- sign值的生成方式是:将上述参数(em.token、eE、eS 和 ep.data)通过&连接成一个字符串,然后对该字符串进行MD5加密(eT)。
代码使用说明
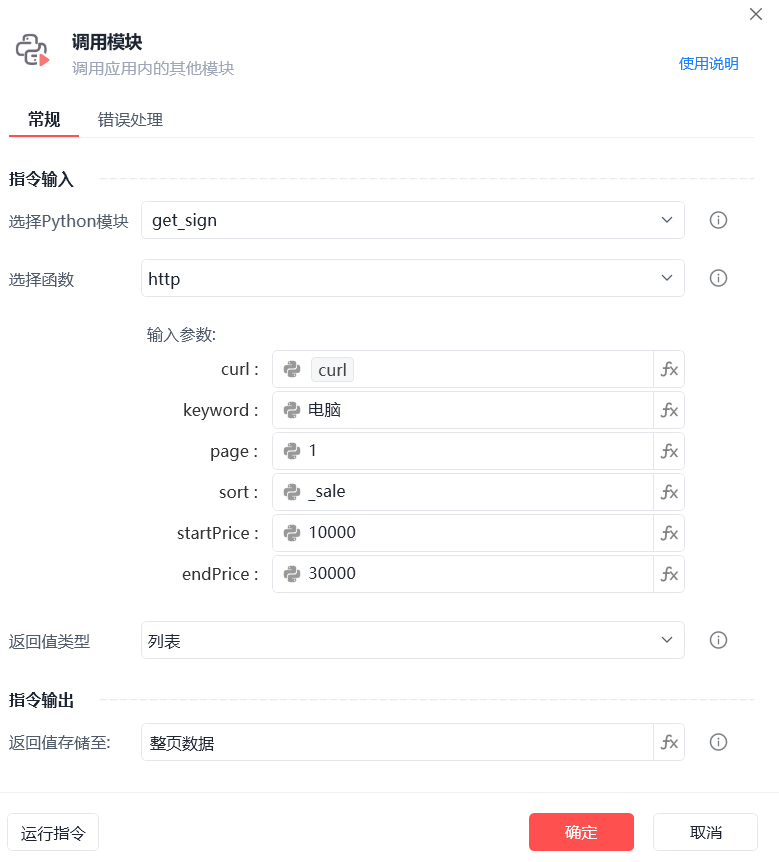
代码已经进行了简化处理,只需提供以下必要参数即可:
- cURL:通过浏览器的开发者工具(空白处右键点击“检查”)选择“网络”选项卡,搜索“mtop.relationrecommend.wirelessrecommend.recommend/2.0/”,在出现的请求中右键选择“复制”-“复制cURL(bash)”。获取requests请求需要的请求头和cookie,换成该方式直接可以复制粘贴。
- keyword:搜索关键词。
- page:页码,范围为1-100。
- sort:排序方式,可选值如下:
- 综合排序:_coefp
- 销量排序:_sale
- 价格高-低:_bid
- 价格低-高:bid
- startPrice:最低价格。
- endPrice:最高价格。
具体代码
只需要安装requests库,影刀调用模块运行就行。
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import hashlib
import json
import requests
import re
import time
#curl转请求头
def curl_headers(curl_str):
# 初始化headers字典
headers = {}
# 分割curl字符串为行
lines = curl_str.strip().split('\n')
# 解析headers
for line in lines[1:]:
line = line.strip()
if line.startswith('-H'):
# 提取header键值对
header = line[4:-1] # 去掉 -H ' 和最后的 '
if ':' in header:
key, value = header.split(':', 1)
headers[key.strip()] = value.strip()
elif line.startswith('-b'):
# 提取cookie
cookie = line[4:-1] # 去掉 -b ' 和最后的 '
headers['cookie'] = cookie.strip()
# 转换为json字符串,去掉多余的引号
return json.dumps(headers, indent=4, ensure_ascii=False).replace("'", "")
def http(curl,keyword,page,sort,startPrice,endPrice):
#获取请求头
headers = curl_headers(curl)
pattern = r'_m_h5_tk=([a-f0-9]{32})'
match = re.search(pattern, headers)
em_token = match.group(1)
eS = '12574478' #固定值
eE = int(time.time()*1000) #毫秒时间戳
data = {
"appId": "34385",
"params": {
"page": page, # 页码
"q": keyword, # 关键词
"sort": sort, # 综合排序:_coefp 销量:_sale 价格高-低:_bid 价格低-高:bid
"start_price": startPrice, # 最低价格
"end_price": endPrice, # 最高价格
"startPrice": startPrice,
"endPrice": endPrice,
"n": 48,
"device": "HMA-AL00",
"isBeta": "false",
"grayHair": "false",
"from": "nt_history",
"brand": "HUAWEI",
"info": "wifi",
"index": "4",
"rainbow": "",
"schemaType": "auction",
"elderHome": "false",
"isEnterSrpSearch": "true",
"newSearch": "false",
"network": "wifi",
"subtype": "",
"hasPreposeFilter": "false",
"prepositionVersion": "v2",
"client_os": "Android",
"gpsEnabled": "false",
"searchDoorFrom": "srp",
"debug_rerankNewOpenCard": "false",
"homePageVersion": "v7",
"searchElderHomeOpen": "false",
"search_action": "initiative",
"sugg": "_4_1",
"sversion": "13.6",
"style": "list",
"ttid": "600000@taobao_pc_10.7.0",
"needTabs": "true",
"areaCode": "CN",
"vm": "nw",
"countryNum": "156",
"m": "pc",
"qSource": "url",
"pageSource": "a21bo.jianhua/a.201856.d13", # 页面来源路径
"tab": "all",
"pageSize": 48,
"totalPage": 100, # 总页数
"totalResults": 4800,
"sourceS": "0",
"bcoffset": "",
"ntoffset": "",
"filterTag": "",
"service": "",
"prop": "",
"loc": "",
"itemIds": None,
"p4pIds": None,
"p4pS": None,
"categoryp": "",
"ha3Kvpairs": None,
"myCNA": "2tL/Hm7Tmn8BASQOBH0pjN5M"
}
}
#计算sign
params_str = json.dumps(data['params']).replace('"', '\\"') #转义
ep_data_str = f'{{"appId":"{data["appId"]}","params":"{params_str}"}}' #构造参与sign计算的json字符串
string = em_token + "&" + str(eE) + "&" + eS + "&" + ep_data_str #加密
MD5 = hashlib.md5()
MD5.update(string.encode('utf-8'))
sign = MD5.hexdigest()
params = {
'jsv': '2.7.4',
'appKey': str(eS),
't': str(eE),
'sign': sign,
'api': 'mtop.relationrecommend.wirelessrecommend.recommend',
'v': '2.0',
'timeout': '10000',
'type': 'jsonp',
'dataType': 'jsonp',
'callback': 'mtopjsonp5',
'data': ep_data_str
}
url = 'https://h5api.m.taobao.com/h5/mtop.relationrecommend.wirelessrecommend.recommend/2.0/'
response = requests.get(url= url, params=params,headers=json.loads(headers)).text
# 将请求数据转成json格式
match = re.search(r'mtopjsonp\d+\((.*)\)', response)
json_data = json.loads(match.group(1))
status = json_data['ret']
print("关键词:",keyword," ","页数:",page," ","状态:",status," ","签名结果:", sign)
if "调用成功" in ', '.join(status):
# 提取数据
all_data = []
json_lists = json_data['data']['itemsArray']
for s in json_lists:
try:
sku = s['umpPriceLog']['s_id']
except Exception as e:
sku = ""
标题 = re.sub(r'<span[^>]*>.*?</span>', '', s['title'])
价格 = s['price']
销量 = s['realSales']
地点 = s['procity']
链接 = "https:" + s['auctionURL']
商品详情 = [sku,标题,价格,销量,地点,链接]
all_data.append(商品详情)
return all_data
else:
""代码运行
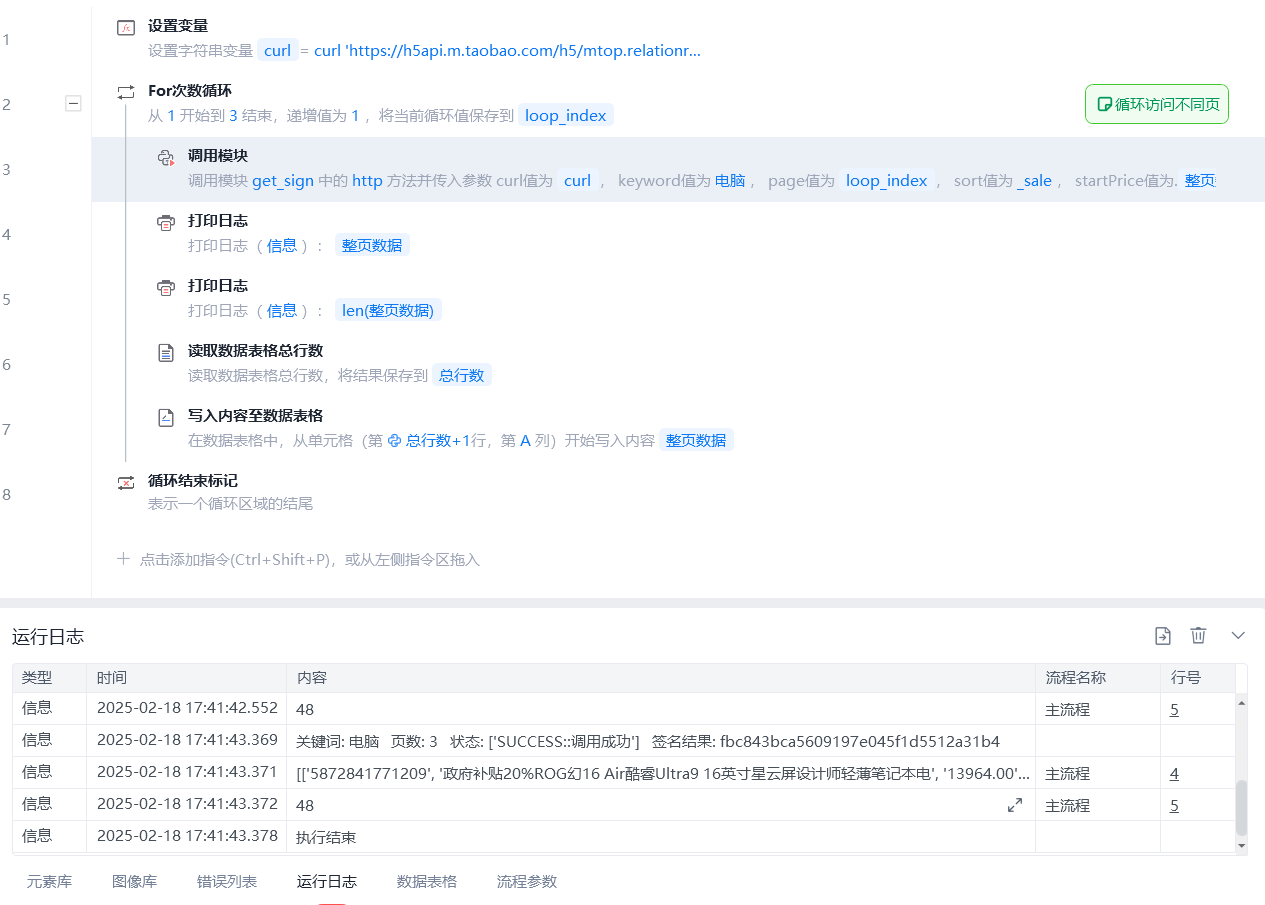
代码运行会有三种结果:
- 正常导出数据
- 令牌过期:需要更改curl
- 被挤爆啦:访问频繁,需要打开淘宝,过一下验证码。
收藏31全部评论(1)
最新
发布评论
评论




