逆向案例 -- 淘宝评论:接上一篇商品数据采集 收藏
收藏
评论
收藏逆向案例 -- 淘宝评论:接上一篇商品数据采集

2025-02-19 22:13·浏览量:1617
RPA梦工厂
 影刀专家
影刀专家前言
和上一篇一样,sign逆向逻辑是一样的,唯一不同的是请求参数和请求头。请求头直接F12里面复制就行。参数变化是把关键词换成商品链接,其他基本不变。详情看** 上篇 **
代码使用说明
代码进行了简化处理,只需提供以下必要参数即可:
•cURL:通过浏览器的开发者工具(空白处右键点击“检查”)选择“网络”选项卡,搜索“mtop.taobao.rate.detaillist.get/6.0/”,在出现的请求中右键选择“复制”-“复制cURL(bash)”。获取requests请求需要的请求头和cookie,换成该方式直接可以复制粘贴。
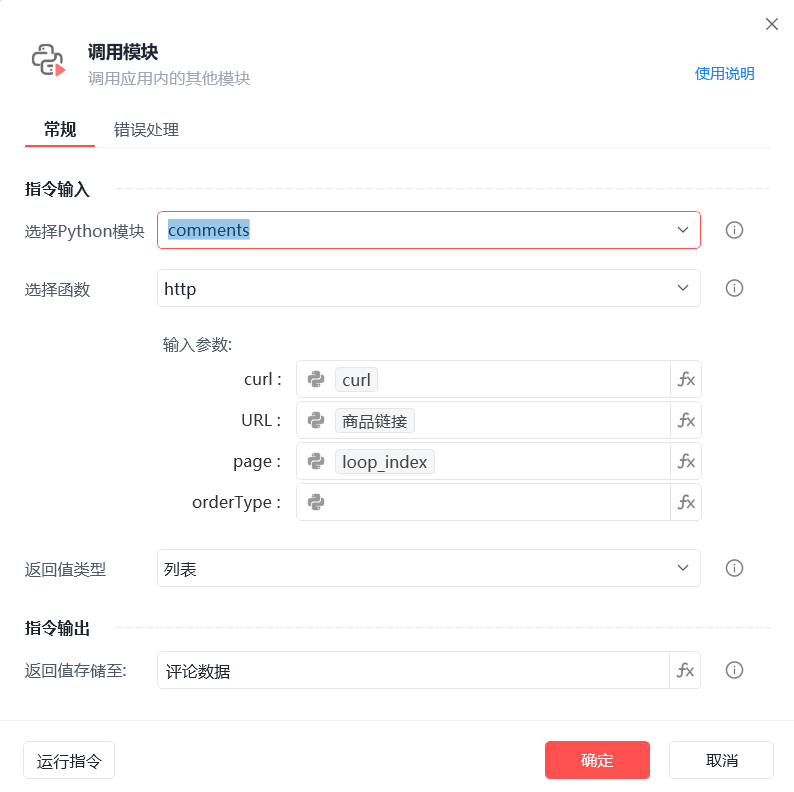
•URL:商品链接。
•page:页码
•sort:排序方式,可选值如下:
◦综合排序:留空
◦时间排序:feedbackdate
具体代码
只需要安装requests库,影刀调用模块运行就行。
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import hashlib
import json
import requests
import re
import time
#curl转请求头
def curl_headers(curl_str):
# 初始化headers字典
headers = {}
# 分割curl字符串为行
lines = curl_str.strip().split('\n')
# 解析headers
for line in lines[1:]:
line = line.strip()
if line.startswith('-H'):
# 提取header键值对
header = line[4:-1] # 去掉 -H ' 和最后的 '
if ':' in header:
key, value = header.split(':', 1)
headers[key.strip()] = value.strip()
elif line.startswith('-b'):
# 提取cookie
cookie = line[4:-1] # 去掉 -b ' 和最后的 '
headers['cookie'] = cookie.strip()
# 转换为json字符串,去掉多余的引号
return json.dumps(headers, indent=4, ensure_ascii=False).replace("'", "")
def http(curl,URL,page,orderType):
#获取请求头
headers = curl_headers(curl)
#商品id
auctionNumId = re.search(r'id=(\d+)', URL).group(1)
em_token = re.search(r'_m_h5_tk=([a-f0-9]{32})', headers).group(1)
eS = '12574478' #固定值
eE = int(time.time()*1000) #毫秒时间戳
data = {
"showTrueCount": False,
"auctionNumId": str(auctionNumId), #商品id
"orderType": orderType, #排序,默认排序为空 时间排序:feedbackdate
"pageNo": page,
"pageSize": 20,
"rateType": "",
"searchImpr": "-8",
"expression": "",
"rateSrc": "pc_rate_list"
}
ep_data_str = json.dumps(data).replace(" ", "")
# string = em_token + "&" + str(eE) + "&" + eS + "&" + ep_data_str #加密
string = em_token + "&" + str(eE) + "&" + eS + "&" + ep_data_str
sign = hashlib.md5(string.encode('utf-8')).hexdigest()
params = {
'jsv': '2.7.4',
'appKey': str(eS),
't': str(eE),
'sign': sign,
"api": "mtop.taobao.rate.detaillist.get",
"v": "6.0",
"isSec": 0,
"ecode": 1,
"timeout": 20000,
"type": "jsonp",
"dataType": "jsonp",
"jsonpIncPrefix": "pcdetail",
"callback": "mtopjsonppcdetail23",
"data":ep_data_str
}
url = 'https://h5api.m.taobao.com/h5/mtop.taobao.rate.detaillist.get/6.0/'
response = requests.get(url= url, params=params,headers=json.loads(headers)).text
match = re.search(r'mtopjsonppcdetail23\((.*?)\)', response)
json_data = json.loads(match.group(1))
status = json_data['ret']
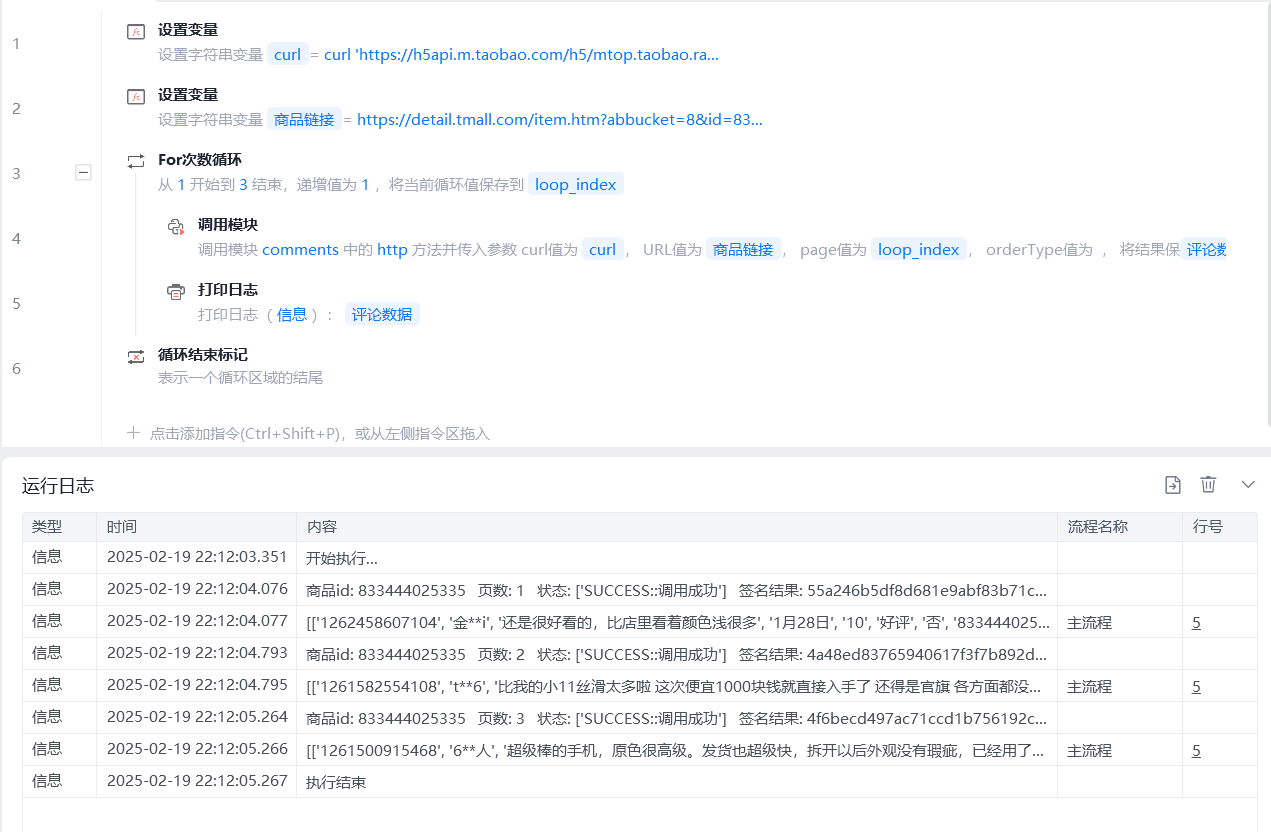
print("商品id:",auctionNumId," ","页数:",page," ","状态:",status," ","签名结果:", sign)
if "调用成功" in ', '.join(status):
# 提取数据
all_data = []
json_lists = json_data['data']['rateList']
for s in json_lists:
评论id = s['id']
商品编号 = s['auctionNumId']
型号 = s['auctionTitle']
用户昵称 = s['reduceUserNick']
评论 = s['feedback']
时间 = s['createTime']
信用等级 = s['creditLevel']
是否好评 = "好评" if s['rateType'] == "1" else "非好评"
是否重复购买 = "是" if s['repeatBusiness'] == "true" else "否"
try:
图片 = "\n".join([f"https:{item}" for item in s['feedPicPathList']])
except Exception as e:
图片 = ""
评论详情 = [评论id,用户昵称,评论,时间,信用等级,是否好评,是否重复购买,商品编号,型号,图片]
all_data.append(评论详情)
return all_data
else:
""代码运行
收藏6全部评论(1)
最新
发布评论
评论




