利用阿里语音转文字模型funasr,实时监控直播间,触发影刀回复弹幕 收藏
收藏
评论
收藏利用阿里语音转文字模型funasr,实时监控直播间,触发影刀回复弹幕
邹
2025-02-23 17:41·浏览量:1501
邹
邹涛涛
 影刀高级开发者
影刀高级开发者使用了B站UP主零炻集合的funasr包,感谢我的技术土豆提供了整体的思路,感谢小可耐并发手机发送教程,感谢驿站提供技术支持
1、回归正题,funasr我部署在一台较好的电脑上作为服务器,另外一台长期跑影刀的电脑作为客户端进行访问,这里我遇到的问题是如何监听自己的电脑声音,并作为麦克风输入,找了无数方案,最快的方案是使用声音里面的 启用立体声混音,并侦听播放设备,此时会遇到开始侦听后,没有声音输入的问题(部署的时候遇到的),只需更新声卡驱动即可。
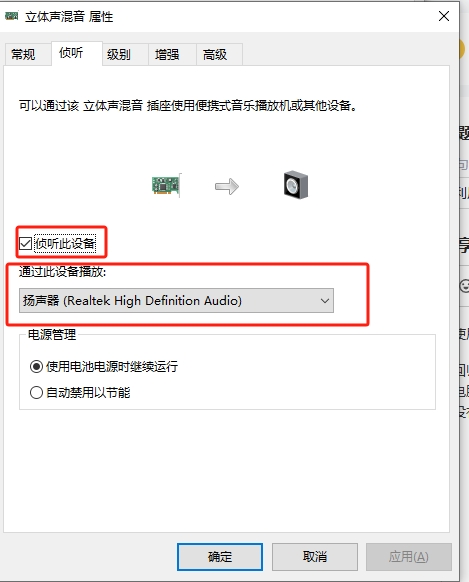
当播放是,立体声右侧几条杠有上下浮动就表示侦听成功了

2、部署funasr
因为是整合包,按照教程运行就可以了,我是使用 01 启动C++服务端(2pass带验证),作为服务器的电脑ip最好是固定的,客户端需要输入ip链接

选择麦克风模式,asr类型选2pass ,别的都是默认模式,热词根据自己需求设置,因为每个主播口音不同,可能会导致识别错误,热词可以避免这个情况发生
此处有个小技巧,抖音网页版不动容易暂停,这里我使用了桌面app,可以规避超长时间播放导致的系统暂停
都部署好后,可以点击链接测试是否能正常监听,产出文字,如果能输出文字可以继续进行操作
3、需要修改网页端代码,此处是驿站大佬帮忙修改的,此处贴上代码,自行取用,使用执行js脚本返回文本做判定即可,后续影刀如何触发并执行,相信大家能自己解决
() => {
return window.queue && window.queue.shift()
}<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>语音识别</title>
</head>
<body style="margin-left: 3%">
<script src="recorder-core.js" charset="UTF-8"></script>
<script src="wav.js" charset="UTF-8"></script>
<script src="pcm.js" charset="UTF-8"></script>
<h1>FunASR Demo</h1>
<h3>这里是FunASR开源项目体验demo,集成了VAD、ASR与标点等工业级别的模型,支持长音频离线文件转写,实时语音识别等,开源项目地址:https://github.com/alibaba-damo-academy/FunASR</h3>
<div class="div_class_topArea">
<div class="div_class_recordControl">
asr服务器地址(必填):
<br>
<input id="wssip" type="text" onchange="addresschange()" style=" width: 100%;height:100%" value="wss://127.0.0.1:10095/"/>
<br>
<a id="wsslink" href="#" onclick="window.open('https://127.0.0.1:10095/', '_blank')"><div id="info_wslink">点此处手工授权wss://127.0.0.1:10095/</div></a>
<br>
<br>
<div style="border:2px solid #ccc;">
选择录音模式:<br/>
<label><input name="recoder_mode" onclick="on_recoder_mode_change()" type="radio" value="mic" checked="true"/>麦克风 </label>
<label><input name="recoder_mode" onclick="on_recoder_mode_change()" type="radio" value="file" />文件 </label>
</div>
<br>
<div id="mic_mode_div" style="border:2px solid #ccc;display:block;">
选择asr模型模式:<br/>
<label><input name="asr_mode" type="radio" value="2pass" checked="true"/>2pass </label>
<label><input name="asr_mode" type="radio" value="online" />online </label>
<label><input name="asr_mode" type="radio" value="offline" />offline </label>
</div>
<div id="rec_mode_div" style="border:2px solid #ccc;display:none;">
<input type="file" id="upfile">
</div>
<br>
<div id="use_itn_div" style="border:2px solid #ccc;display:block;">
逆文本标准化(ITN):<br/>
<label><input name="use_itn" type="radio" value="false" checked="true"/>否 </label>
<label><input name="use_itn" type="radio" value="true" />是 </label>
</div>
<br>
<div style="border:2px solid #ccc;">
热词设置(一行一个关键字,空格隔开权重,如"阿里巴巴 20"):
<br>
<textarea rows="3" id="varHot" style=" width: 100%;height:100%" >阿里巴巴 20
hello world 40</textarea>
<br>
</div>
语音识别结果显示:
<br>
<textarea rows="10" id="varArea" readonly="true" style=" width: 100%;height:100%" ></textarea>
<br>
<div id="info_div">请点击开始</div>
<div class="div_class_buttons">
<button id="btnConnect">连接</button>
<button id="btnStart">开始</button>
<button id="btnStop">停止</button>
</div>
<audio id="audio_record" type="audio/wav" controls style="margin-top: 12px; width: 100%;"></audio>
</div>
</div>
<script src="wsconnecter.js" charset="utf-8"></script>
<script src="main.js" charset="utf-8"></script>
</body>
</html>
全部评论(1)
最新
发布评论
评论




