 收藏
收藏关于用影刀跑BOSS的经验
我本来是写代码的后端工程师,奈何HR不知道从哪看到一份影刀离职员工的简历,眼都发光了,说要整一个招人的RPA自动化流程,没办法只能开始研究了。艰难从零开发了两周多,用零零散散的时间做了两个功能,一个是自动打招呼,一个是自动回复未读消息要简历,也算是堪堪能用吧,说起来这个低代码平台是用起来是真难受,主要是受下面几点限制:
一个是没有流程图可以看,我编排了一百多行的程序,每次出问题了都要一行一行的看,影刀却没有那种一键查看流程图的工具可用,效率极低
二是代码共享,可能这就是影刀的护城河了,代码是决定不能被别人看到的,这就有个问题了,我电脑上能跑的,到了别人电脑上不能跑,出了问题了还是得在自己电脑上排查,但是自己电脑上又没问题,真是难搞。
功能实现上:
- 自动沟通是怎么实现的呢?
首先,一般沟通都是查看未读消息里的应聘者信息,然后做一些条件判断,最后发一条消息,点一下要简历,就是这个流程了,而且这个流程是要一直处理着,因为会一直有人给我们打招呼,所以显然起手就是无限循环了。
但是怎么在处理一批之后,刷新这个未读消息呢,这里有两种方式,一种是刷新网页,一种是点击未读按钮,我选择的是点击未读按钮,那现在的流程就是:

无限循环 ->点击未读按钮 -> 获取相似元素(一般是13个)-> 循环相似元素 -> 各种数据处理或者要简历 -> 相似元素循环结束 -> 点击未读按钮刷新
如此循环往复,即可实现自动回复未读消息的过程,注意按钮点击和未点击时的底色变化,最好是都捕获一下,然后放在Try里面做重试,都点一下,这里有一个重点就是重复性处理,例如一个用户之前已经和我们打过招呼,我们也向他要过简历了,后面他再发消息的时候,就要过滤他了,这里我是用excel表格来做的,每处理一个用户都保存一条数据,在获取用户姓名数据之后,先用名字+年龄+学校做一个判断,已存在就不用处理了。
- 打招呼是怎么做的?
打招呼这里因为每个账号能主动打招呼的次数有限,所以这里我们可以不做无限循环了,做一个有限次数循环,循环过程中获取相似元素,然后调用智能体传输用户数据用来判断是否需要点击打招呼按钮,如果需要沟通则点击打招呼按钮。重点来了影刀对网页滑动的支持做的并不是很好,至少你在这个推荐牛人页面是不好去做向下滑动的操作的,不然还要判断滑动多少距离啥的,太 麻烦了。所以这里有个取巧的办法,那就是点击推荐按钮来刷新数据,这样的话每个页面我们刷新一次就能获取到11条相似元素,处理完之后再点击刷新按钮继续处理下一批数据。
简略流程如下:
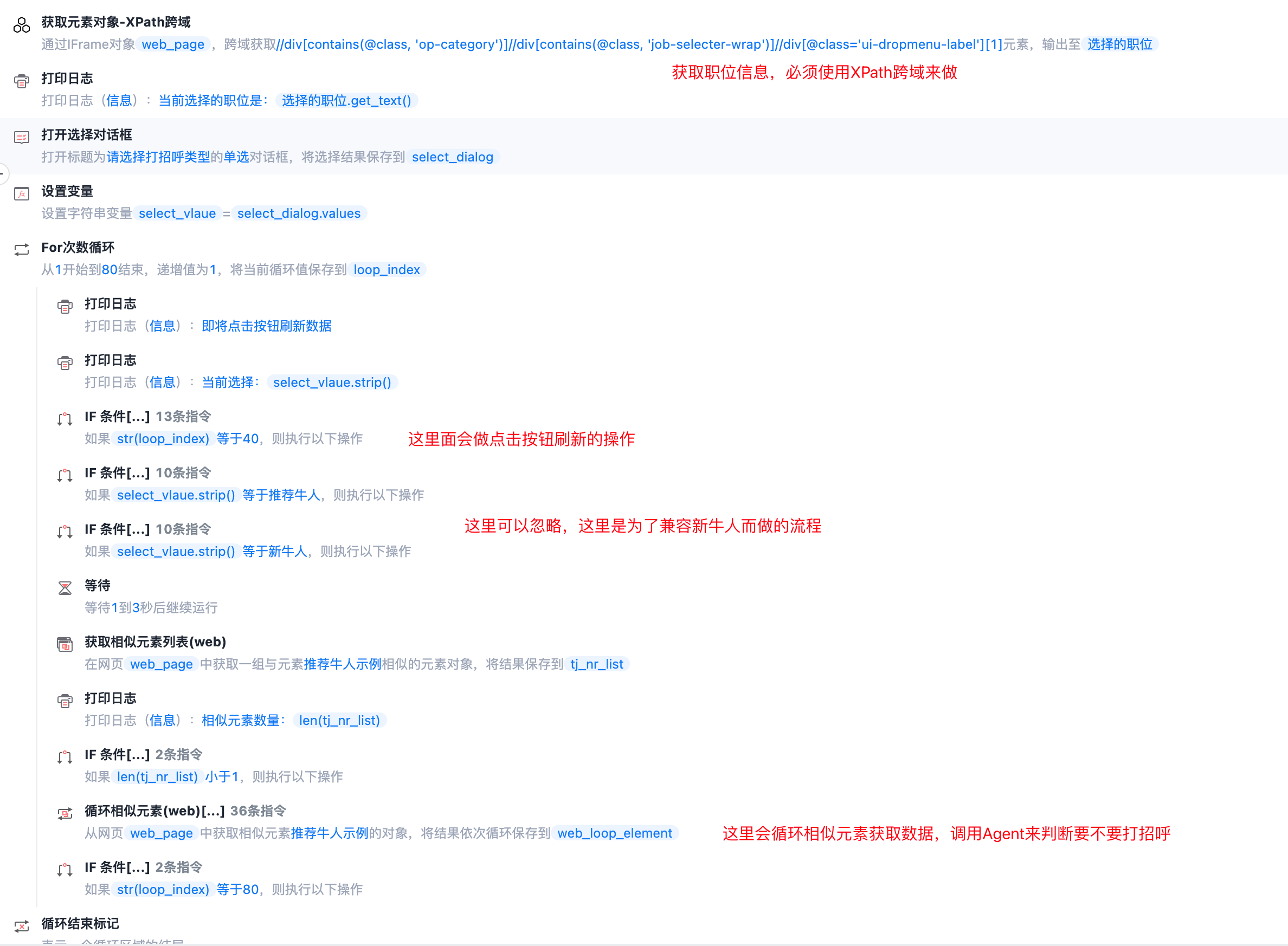
这里提供一个处理应聘者数据的代码参考,可以讲相似元素中获取的元素文本内容传进来,会返回一个JSON格式的数据:
import json
import re
def extract_candidate_info_optimized(text: str) -> str:
"""
从非结构化的应聘者信息文本中提取关键信息,并返回一个转义后的JSON字符串。
该函数经过优化,不依赖于信息的固定行号,能更灵活地处理各种格式的简历文本。
参数:
text (str): 包含应聘者信息的原始文本。
返回:
str: 包含提取信息的、转义后的JSON字符串,可直接嵌入其他JSON字段。
"""
# 初始化结果字典
candidate = {
'姓名': '',
'年龄': '',
'工作经验': '',
'学历': '',
'状态': '',
'薪资要求': '',
'期望岗位': '',
'优势': [],
'工作经历': [],
'教育经历': [],
'标签': []
}
# 预处理:检查输入有效性,并按行分割
if not isinstance(text, str) or not text.strip():
# 直接返回转义后的空 JSON 字符串
return json.dumps(json.dumps(candidate, ensure_ascii=False, indent=2), ensure_ascii=False)
lines = [line.strip() for line in text.strip().split('\n') if line.strip()]
consumed_indices = set() # 用于记录已处理行的索引,避免重复处理
# --- 步骤1: 提取格式明确的多行信息块(工作与教育经历)---
for i in range(len(lines) - 1):
line = lines[i]
next_line = lines[i + 1]
# 匹配工作经历日期 (格式如: YYYY.MM-YYYY.MM, YYYY.MM至今, YYYY.MMYYYY.MM)
work_date_match = re.match(r'^(\d{4}\.\d{2})[- ]?(\d{4}\.\d{2}|至今)$', line)
if not work_date_match:
work_date_match = re.match(r'^(\d{4}\.\d{2})(\d{4}\.\d{2})$', line)
if work_date_match:
start_date = work_date_match.group(1)
end_date = work_date_match.group(2)
time_str = f"{start_date}-{end_date}"
candidate['工作经历'].append(f"{time_str} {next_line}")
consumed_indices.add(i)
consumed_indices.add(i + 1)
# 匹配教育经历日期 (格式如: YYYY-YYYY, YYYY YYYY, YYYYMMDD)
edu_date_match = re.match(r'^(\d{4})[- ]?(\d{4})$', line)
if not edu_date_match:
edu_date_match = re.match(r'^(\d{4})(\d{4})$', line)
if edu_date_match:
start_year = edu_date_match.group(1)
end_year = edu_date_match.group(2)
time_str = f"{start_year}-{end_year}"
candidate['教育经历'].append(f"{time_str} {next_line}")
consumed_indices.add(i)
consumed_indices.add(i + 1)
# --- 步骤2: 提取特征明确的单行信息 ---
for i, line in enumerate(lines):
if i in consumed_indices:
continue
# 薪资要求 (格式如: 8-10K, 面议)
if re.fullmatch(r'\d+-\d+K|面议', line) and not candidate['薪资要求']:
candidate['薪资要求'] = line
consumed_indices.add(i)
continue
# 姓名 (通常是2-4个汉字)
if re.fullmatch(r'[\u4e00-\u9fa5]{2,4}(?!:)', line) and not candidate['姓名']:
candidate['姓名'] = line
consumed_indices.add(i)
continue
# 状态整合行 (包含年龄、经验、学历、求职状态中的多个信息)
status_keywords = ['岁', '年经验', '届应届生', '应届生', '经验', '本科', '大专', '硕士', '博士', '离职', '在职']
if sum(keyword in line for keyword in status_keywords) >= 2:
age_match = re.search(r'(\d+岁)', line)
if age_match: candidate['年龄'] = age_match.group(1)
if '应届生' in line:
candidate['工作经验'] = '应届生'
else:
exp_match = re.search(r'(\d+年(?:工作)?经验)', line) or re.search(r'(\d+年)', line)
if exp_match: candidate['工作经验'] = exp_match.group(1).replace('工作经验', '年')
edu_match = re.search(r'(本科|大专|硕士|博士)', line)
if edu_match: candidate['学历'] = edu_match.group(1)
status_match = re.search(r'(离职(?:-[\u4e00-\u9fa5]+)?|在职(?:-[\u4e00-\u9fa5]+)?|应届生)', line)
if status_match: candidate['状态'] = status_match.group(1)
consumed_indices.add(i)
continue
# 期望岗位 (通常跟在“期望:”之后)
if (line == '期望:' or line == '期望') and i + 1 < len(lines):
candidate['期望岗位'] = lines[i + 1]
consumed_indices.add(i)
consumed_indices.add(i + 1)
continue
# --- 步骤3: 处理剩余行,区分为“优势”和“标签” ---
remaining_lines = []
for i, line in enumerate(lines):
if i not in consumed_indices and line not in ['优势:', '优势', '打招呼']:
remaining_lines.append(line)
# 使用启发式规则区分:长文本为优势,短关键词为标签
tag_start_index = -1
for i, line in enumerate(remaining_lines):
if 2 <= len(line) <= 6 and re.fullmatch(r'[\u4e00-\u9fa5a-zA-Z]+', line):
tag_start_index = i
break
if tag_start_index != -1:
candidate['优势'] = remaining_lines[:tag_start_index]
candidate['标签'] = remaining_lines[tag_start_index:]
else:
candidate['优势'] = remaining_lines
# --- 步骤4: 清理和格式化输出 ---
candidate['工作经历'].reverse()
candidate['教育经历'].reverse()
# 将 JSON 对象序列化为字符串,并进行转义
json_str = json.dumps(candidate, ensure_ascii=False, indent=2)
escaped_json_str = json.dumps(json_str, ensure_ascii=False)
return escaped_json_str[1:-1]
result_info = extract_candidate_info_optimized(web_loop_element.get_text())总结就是:
- 能点击按钮刷新的,绝不滑动刷新
- 给应聘者发送消息时,要用回车发送,不能点击按钮发送,那个按钮做了很多检测,一点击就会被检测
- 每一个按钮在选中和未选中时有不同的背景状态,都要捕获一下,在点击的时候用Try把两个都处理一下,一个点击失败就去点击另一个
- 不同的电脑对于元素的匹配不一样,我的电脑只能匹配到一个,同事的电脑就会匹配到多个,最好编辑一下元素精确确定某一个元素
- BOSS的检测其实还好,一般最开始会触发一次,手动点一下之后,后面就不会再触发了,注意做好延迟就行
收藏15



