 收藏
收藏MOOC慕课 | 数据获取经验分享
 影刀中级开发者
影刀中级开发者引言:
中国大学 MOOC 作为国内优质在线教育核心平台,目前已上线超 6 万门课程、覆盖 13 个学科门类、服务上亿学习者,其数据具备显著分析意义,可聚焦四大方向展开:
- 课程质量与用户偏好分析:通过平均评分、五星占比、评论关键词(如 “老师讲的特别清晰”),对比不同学科(艺术学、理学)、高校课程的受欢迎度与质量差异;
- 课程运营规律分析:结合开课时间、学时、频次,梳理高校在线课程的更新节奏、教学周期及学科开设密度;
- 教育资源与讲师配置分析:依托高校 ID、讲师职称、课程分类,观察优质资源在高校与学科间的分布,以及讲师结构与授课类型的匹配度;
- 用户反馈与课程改进分析:从评论内容、点赞数提取评价(如 “期待下一期”),定位课程优势与优化点,为课程迭代提供参考。
数据示例:
课程基本信息 [ 1w+ ]
| 课程URL | 课程名称 | 课程ID | 分类ID | 分类名称 |
| https://www.icourse163.org/course/PKU-1472012161 | 中国戏曲史 | 1472012161 | 1001043036 | 艺术学 |
| https://www.icourse163.org/course/PKU-1470430188 | 博弈论 | 1470430188 | 1001043056 | 理学 |
课程详细 [ 1w+ ]
| 课程URL | 课程简介(spContent) | 课程概述(详情) |
| https://www.icourse163.org/course/PKU-1472012161 | 文本太长,就不展示了 | 文本太长,就不展示了 |
| https://www.icourse163.org/course/PKU-1470430188 | 文本太长,就不展示了 | 文本太长,就不展示了 |
课程评论信息 [ 300w+ ]
| 点赞数 | 评论 | 时间戳 | 开课ID | 昵称 | 评分 |
| 2 | 老师讲的特别清晰 | 1706960615290 | 1471065538 | mooc8369380195822416 | 5 |
| 0 | 期待下一期 | 1745459593400 | 1471848467 | 李海燕mooc1 | 5 |
课程评分统计数据 [ 1w+ ]
| 课程ID | 目标类型 | 评论总数 | 平均评分 | 五星评论数 |
| 1472012161 | 1 | 11 | 4.27 | 8 |
| 1470411176 | 1 | 6 | 5 | 6 |
大学信息 [ 461 ]
| 课程URL | 大学缩写 | 大学全称 | 大学ID |
| https://www.icourse163.org/course/PKU-1472012161 | PKU | 北京大学 | 13001 |
讲师信息 [ 4w+ ]
(课程的讲师配置:1个首席讲师+n个普通讲师, n>=0)
| 课程URL | 讲师类型 | 讲师姓名 | 讲师职称 |
| https://www.icourse163.org/course/PKU-1472012161 | 首席讲师 | 陈均 | 教授 |
| https://www.icourse163.org/course/PKU-1470430188 | 首席讲师 | 刘霖 | 副教授 |
开课信息 [ 10w+ ]
| 课程URL | 开课ID | 课程ID | 开始时间戳 | 结束时间戳 | 学时 | 开课文本 |
| https://www.icourse163.org/course/PKU-1472012161 | 1473570441 | 1472012161 | 1731427200000 | 1735660800000 | 待定 | 2024年11月13日-2025年01月01日 |
| https://www.icourse163.org/course/PKU-1472012161 | 1474285506 | 1472012161 | 1741104000000 | 1746374400000 | 2025年03月05日-2025年05月05日 |
关键步骤:
步骤1:预先准备所有课程URL
(1)获取所有大学英文简写:GET请求 MOOC大学橱窗页面HTML链接 ==> 使用正则(其他方法也可)从响应的html提取所有大学英文缩写
(2)获取所有大学的所有课程ID:POST请求 含课程ID数据API ,需配参数 csrfKey、schoolId、p、psize、type、courseStatus
==> 解析JSON这个就不讲了,方法挺多的,不会的话,你复制JSON数据丢给AI教你就行,包会的
(3)形成所有课程的URL:格式化示例,f"https://www.icourse163.org/course/{大学英文简写}-{大学课程ID} "
ps:加粗的参数是动态参数,即你要去循环的参数,其他不变即可,以下同理;不会找 api 可以看这个 前端项目没数据?教你抓取各大网站api ,随便找的教学,也可以自己找
步骤2:获取所有课程的评论信息
(1)获取评论JSON数据:POST请求 课程评论数据 API ,需配参数 csrfKey、courseId、pageIndex、pageSize、orderBy
(2)解析JSON数据也不讲了,不会丢给AI,让它教就行
(3)获取的字段示例:
| agreeCount 点赞数 | content 评论内容 | gmtModified 评论时间戳 | mark 评论评分 | termID 评论的开课课次ID | userNickName 评论的用户昵称 |
步骤3:获取所有课程的评分统计数据(这个页可以根据获取的评论数据自行统计)
(1)获取评分统计JSON数据:POST请求 评分统计数据 API ,需配参数 csrfKey、courseId
(2)解析JSON,同上
(3)获取字段示例:
| targetId 课程ID | targetType 目标类型 | evaluateCount 评论总数 | evaluateCount 平均评分 | fiveStarCount 五星评论数 |
步骤4:获取课程其他信息
(1)找到存放课程其他信息的地方:网页数据的获取方法一般可以是xpath、正则等等,如果xpath不行,那就考虑是不是在的js代码里,这时候可以正则等等文本提取的方法,如果还没有,那就考虑接口。这里就是因为xpath提取不到,从而转看js代码,然后一搜,找到了,而且是趴窝的。




(2)提取方法:我用的是正则。先提取对象,再在对象里提取对应的数据,这样匹配误差降到最低,还清晰。下面是其中一个对象的提取函数,基本逻辑大差不差。
def parse_chiefLector(page_html: str) -> Tuple[str, str]:
"""解析首席讲师(姓名、职称)"""
try:
chief_str = safe_re_search(r'window\.chiefLector\s*=\s*(\{.*?\});', page_html, re.DOTALL)
if not chief_str:
return "", ""
name = safe_re_search(r'lectorName\s*:\s*"(.*?)"', chief_str)
title = safe_re_search(r'lectorTitle\s*:\s*"(.*?)"', chief_str)
return name, title
except Exception as e:
print(f"解析首席讲师出错: {e}")
return "", ""
(3)除了以上数据,还需要获取课程简介和课程概述,好在他们用xpath可以定位到,那就xpath获取文本即可。注意一下课程概述是多个p标签的文本组合的

其他说明
我采用的是 threading 线程并发,三个模块(预先获取所有课程URL不算)都是20个并发数,模块之间是串行,总耗时1 小时 14 分钟 4.873 秒,另外,我也搭了纯影刀指令流程,思路一样,就是没怎么玩明白并发指令。
存储文件的位置是桌面
反爬机制的话,还是对新手很友好的
应用说明
应用分享链接: https://api.winrobot360.com/redirect/robot/share?inviteKey=4ebe649dd15a6001
配置文件 课程URL.xlsx链接: https://alidocs.dingtalk.com/i/nodes/PwkYGxZV3pmqrLeQClYMQKX2JAgozOKL?utm_scene=person_space
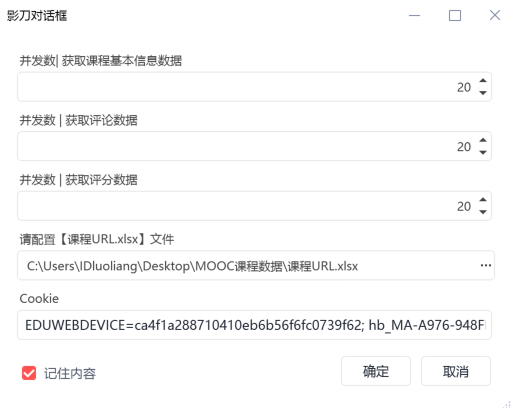
影刀机器人配置界面如下:
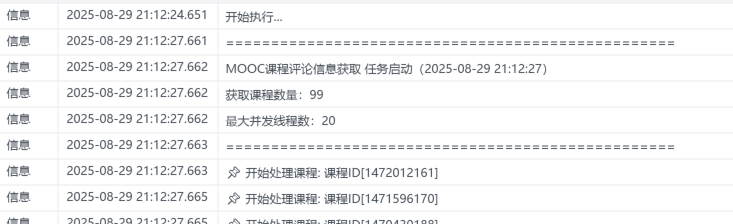
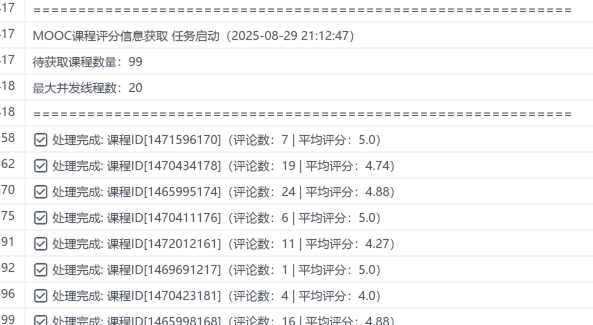
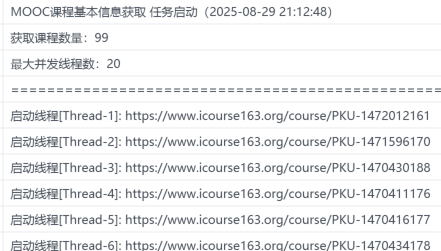
启动日志如下,课程设置为99个方便展示:
!!!注意事项:
合规优先:严格遵守 MOOC 网站协议及相关法律法规,严禁违规抓取数据。
适度操作:控制数据获取频率与规模,避免占用过多服务器资源,影响平台正常运行。
用途规范:所获数据仅限学术分析。
收藏4



