使用ddddocr库进行免费的验证码识别(常规数英、个位数计算) 收藏
收藏
评论
收藏使用ddddocr库进行免费的验证码识别(常规数英、个位数计算)
z
2025-12-18 14:23·浏览量:944
z
zhanc
 影刀中级开发者
影刀中级开发者就目前开发遇到的登录流程验证码识别问题,分享一下解决方案
一、常规简易识别码(社区内已经有相关内容了,水一段~)
适用类型:简易的数英识别码(通途ERP)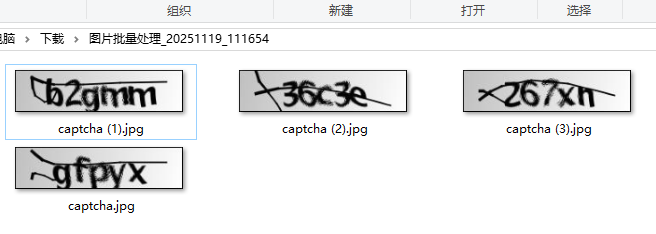 示例代码:
示例代码:
import ddddocr
import os
def recognize_captcha(image_path):
"""
识别验证码图片中的文字
参数:
image_path (str): 验证码图片的路径
返回:
str: 识别出的验证码文字,如果识别失败则返回空字符串
"""
# 检查图片文件是否存在
if not os.path.exists(image_path):
print(f"错误: 图片文件 '{image_path}' 不存在")
return ""
try:
# 创建OCR识别器实例
ocr = ddddocr.DdddOcr()
# 读取图片文件
with open(image_path, 'rb') as f:
image_bytes = f.read()
# 识别验证码
result = ocr.classification(image_bytes)
return result
except Exception as e:
print(f"识别过程出错: {str(e)}")
return ""使用示例:
可以作为指令,传入网页对象和验证码图片元素,输出识别结果。然后设置循环进行碰运气式登录~也可以通过对验证码图片进行特定处理提高识别成功率,这里能力有限就不拓展了~
注:使用前记得导入ddddocr,如果导入后报错,参考升级python版本3.10,还有异常参考社区内链接 https://www.yingdao.com/community/detaildiscuss?id=816487237932032000&tag=&from=userCenter&sort=createTime&page=1
二、计算型验证码
适用类型:个位数的计算型验证码(易达云OMS)
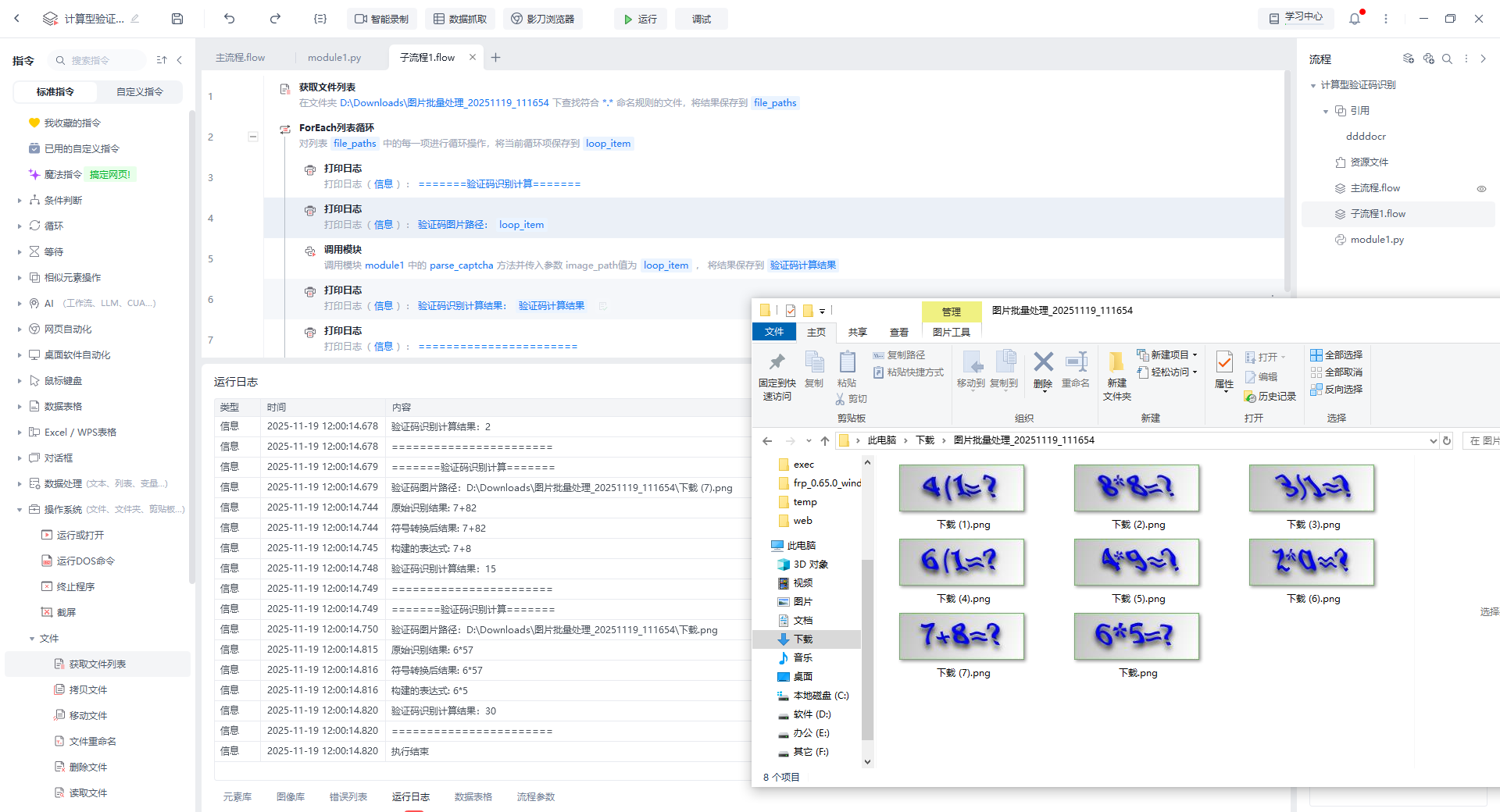
如果直接用上方简易识别的话成功率可能不到10%,所以需要对计算型的验证码针对性的优化,个位数计算较简单,例如第一、三位一定是数字,第二位一定是运算符,对易出现识别错误的字符(如"/"容易识别成"|"或"l")进行指定转换,总结出这些特性后交给AI生成对应的转换规则即可得出下方代码。多位数暂时还没遇到,同理进行针对优化即可。
示例代码:
import ddddocr
import os
import glob
import re
def parse_captcha(image_path):
"""
从图片路径识别验证码并返回计算结果
参数:
image_path: 验证码图片的路径
返回:
如果能解析出有效表达式则返回计算结果,否则返回None
"""
# 初始化OCR
ocr = ddddocr.DdddOcr()
# 读取验证码图片
with open(image_path, "rb") as f:
img_bytes = f.read()
# 识别文本
result = ocr.classification(img_bytes)
print(f"原始识别结果: {result}")
# 符号转换:处理常见的识别错误
# 加号(+)容易识别成t,除号(/)容易识别成|或l,乘号(*)容易识别成x或4(只在第二位)
symbol_corrections = {
't': '+', # t -> +
'T': '+', # T -> +
'|': '/', # | -> /
'l': '/', # l -> /
'L': '/', # L -> /
'i': '/', # i -> /
'I': '/', # I -> /
'x': '*', # x -> *
'X': '*', # X -> *
'×': '*', # × -> *
'÷': '/', # ÷ -> /
'-': '-', # - -> - (保持不变)
'_': '-', # _ -> -
}
# 数字转换:处理常见的识别错误
# 2容易识别成z,0容易识别成O和q,1容易识别成l或I,5容易识别成S
digit_corrections = {
'z': '2', # z -> 2
'Z': '2', # Z -> 2
'O': '0', # O -> 0
'o': '0', # o -> 0
'q': '0', # q -> 0
'Q': '0', # Q -> 0
'S': '5', # S -> 5
's': '5', # s -> 5
'G': '6', # G -> 6
'g': '9', # g -> 9
}
# 应用符号转换
corrected_result = result
for wrong_symbol, correct_symbol in symbol_corrections.items():
corrected_result = corrected_result.replace(wrong_symbol, correct_symbol)
# 应用数字转换
for wrong_digit, correct_digit in digit_corrections.items():
corrected_result = corrected_result.replace(wrong_digit, correct_digit)
# 特殊处理:第二位的4可能是乘号(*)
if len(corrected_result) >= 3:
corrected_list = list(corrected_result)
if corrected_list[1] == '4': # 第二位是4,可能是乘号
corrected_list[1] = '*'
corrected_result = ''.join(corrected_list)
print(f"符号转换后结果: {corrected_result}")
# 如果识别结果长度小于3,直接返回None
if len(corrected_result) < 3:
return None
# 尝试多种模式匹配
patterns = [
# 模式1: 数字+运算符+数字
r'(\d)([+\-*/])(\d)',
# 模式2: 跳过可能的问号或等号,查找数字+运算符+数字
r'[^\d]*(\d)([+\-*/])(\d)[^\d]*',
# 模式3: 查找任意位置的有效表达式
r'(\d)[^\d]*([+\-*/])[^\d]*(\d)'
]
for pattern in patterns:
match = re.search(pattern, corrected_result)
if match:
num1, operator, num2 = match.groups()
# 处理除法,避免除零错误
if operator == '/' and num2 == '0':
continue
try:
expr = f"{num1}{operator}{num2}"
print(f"构建的表达式: {expr}")
# 计算结果
if operator == '/':
# 除法运算,只返回整数部分
num1_int = int(num1)
num2_int = int(num2)
if num2_int == 0: # 避免除零错误
continue
answer = num1_int // num2_int # 整数除法
else:
# 其他运算
answer = eval(expr)
return answer
except:
continue
# 如果正则匹配失败,尝试简单的前三个字符方法
first_three = corrected_result[:3]
# 检查第1、3位是否为数字,第2位是否为运算符
if (first_three[0].isdigit() and
first_three[2].isdigit() and
first_three[1] in ['+', '-', '*', '/']):
# 构建表达式
expr = f"{first_three[0]}{first_three[1]}{first_three[2]}"
print(f"使用前三个字符构建的表达式: {expr}")
# 计算结果
try:
# 处理除法,避免除零错误
if first_three[1] == '/' and first_three[2] == '0':
return None
# 计算表达式
if first_three[1] == '/':
# 除法运算,只返回整数部分
num1_int = int(first_three[0])
num2_int = int(first_three[2])
answer = num1_int // num2_int # 整数除法
else:
# 其他运算
answer = eval(expr)
return answer
except:
return None
return None使用示例(同简易型):
希望能帮上你~Enjoy!

收藏12全部评论(1)
最新
发布评论
评论




