用影刀实现批量保存今日头条文章中的图片链接 收藏
收藏
回答
收藏用影刀实现批量保存今日头条文章中的图片链接
千
2026-01-07 22:10·浏览量:128
千
千城墨白影
我已经使用f12找到了这篇文章中的所有图片,我可以手动复制下来,但是太累,怎么实现自动?
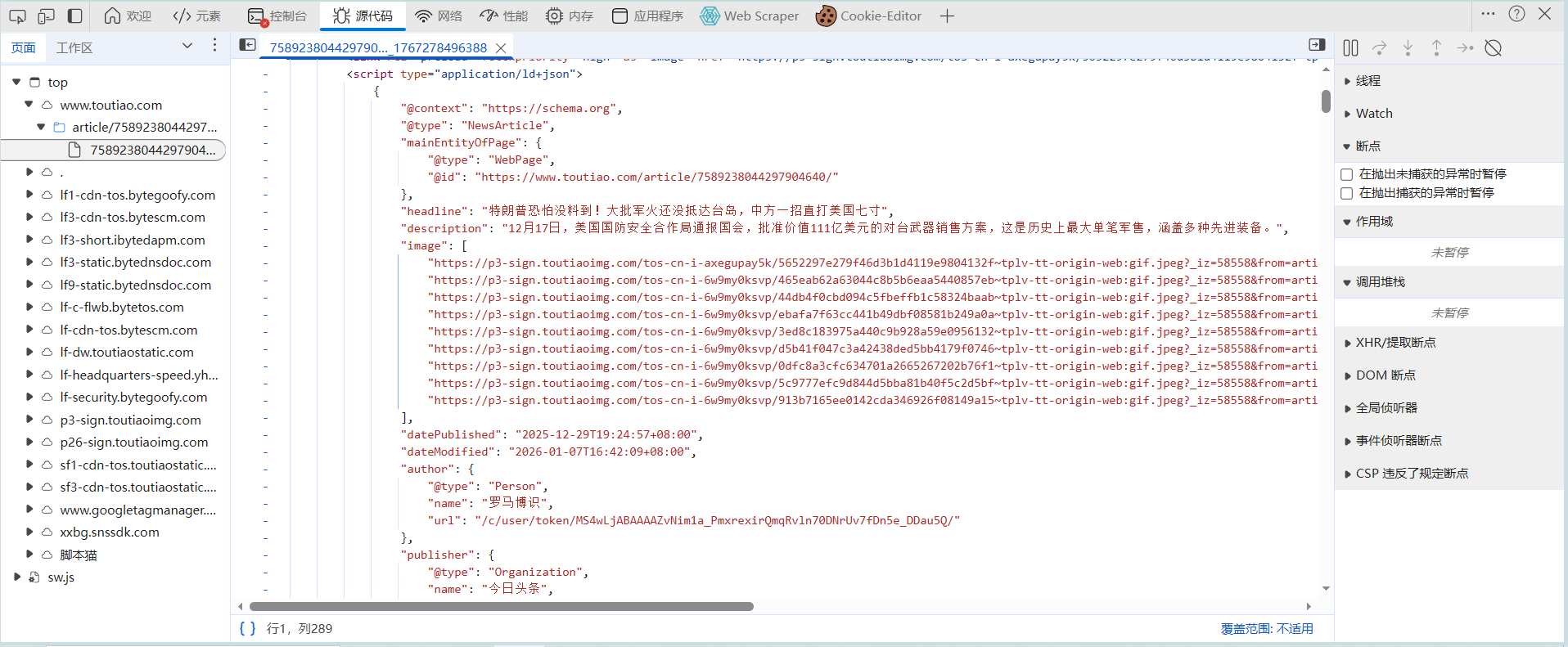 image后面那些红色的链接就是我要的
image后面那些红色的链接就是我要的
 后来看到课程教材,http下载,找到了也是图片的链接,包括xpath ,我是用获取相似元素中的xpath选择器,可以实现,但是换成别的别的文章就会卡住,我知道这应该是换了网页,他那个之前捕获的xpath在新网页没找到,就无法获取新网页相似的了
后来看到课程教材,http下载,找到了也是图片的链接,包括xpath ,我是用获取相似元素中的xpath选择器,可以实现,但是换成别的别的文章就会卡住,我知道这应该是换了网页,他那个之前捕获的xpath在新网页没找到,就无法获取新网页相似的了
最终目的就是实现能够自动保存这些链接,保存到文件中,就这样,各位老哥有好的注意吗?
收藏全部回答(1)
最新
发布回答
回答




