 收藏
收藏掌心向暖RPA | 飞书文档附件文件下载RPA方案,支持PDF,Word、PPT、Excel、视频源文件下载

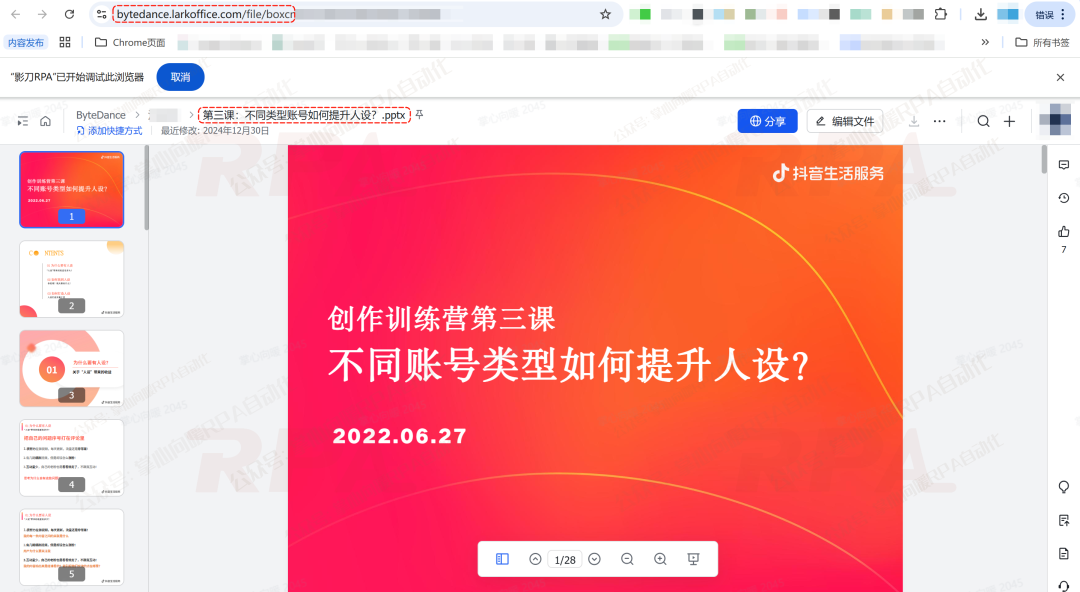
 影刀中级开发者
影刀中级开发者通过"监听+请求"进行源文件的下载,支持PDF、PPT、视频、普通电子表格、Word文档五大常规文件类型快速下载。

#关于"飞书文档类型"的信息补充:
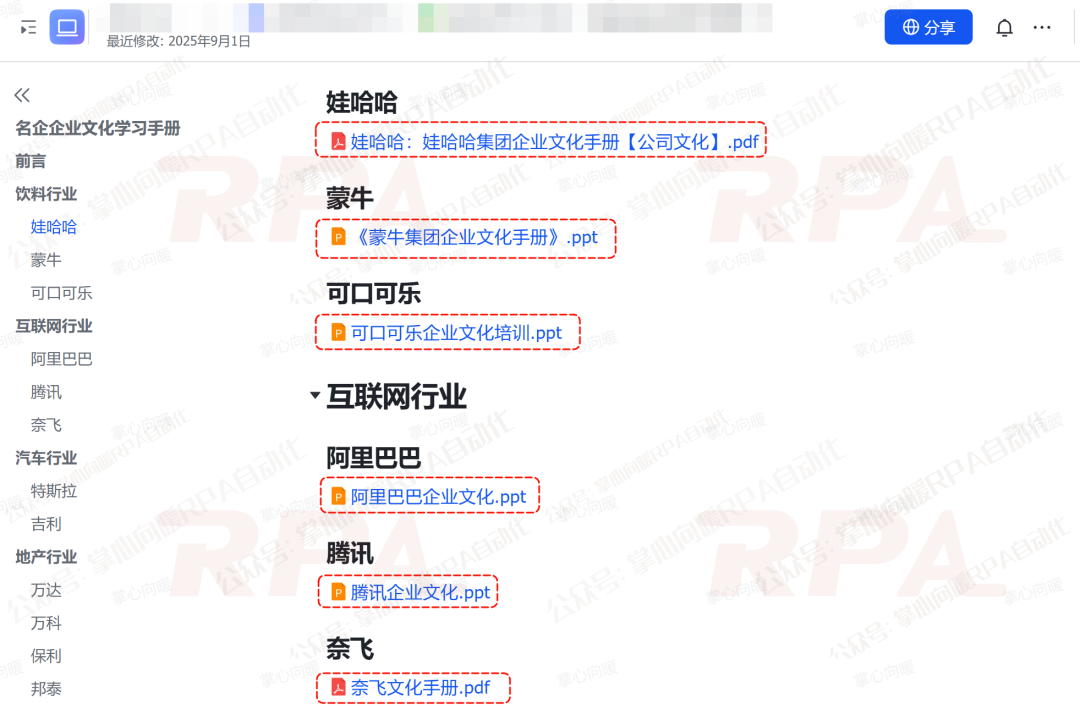
内嵌文档(嵌入主文档)- 将外部文件(Word、PDF、Excel、PPT等)上传后嵌入到飞书文档中
独立文档(独立视图)- 上传的文件独立存在,有单独的访问链接
目前支持的具体功能点:
支持两类常见飞书附件/嵌入文件结构。「内嵌文档(嵌入主文档)」:外部文件上传后嵌入飞书文档中;「独立文档(独立视图)」:文件独立存在,有单独访问链接
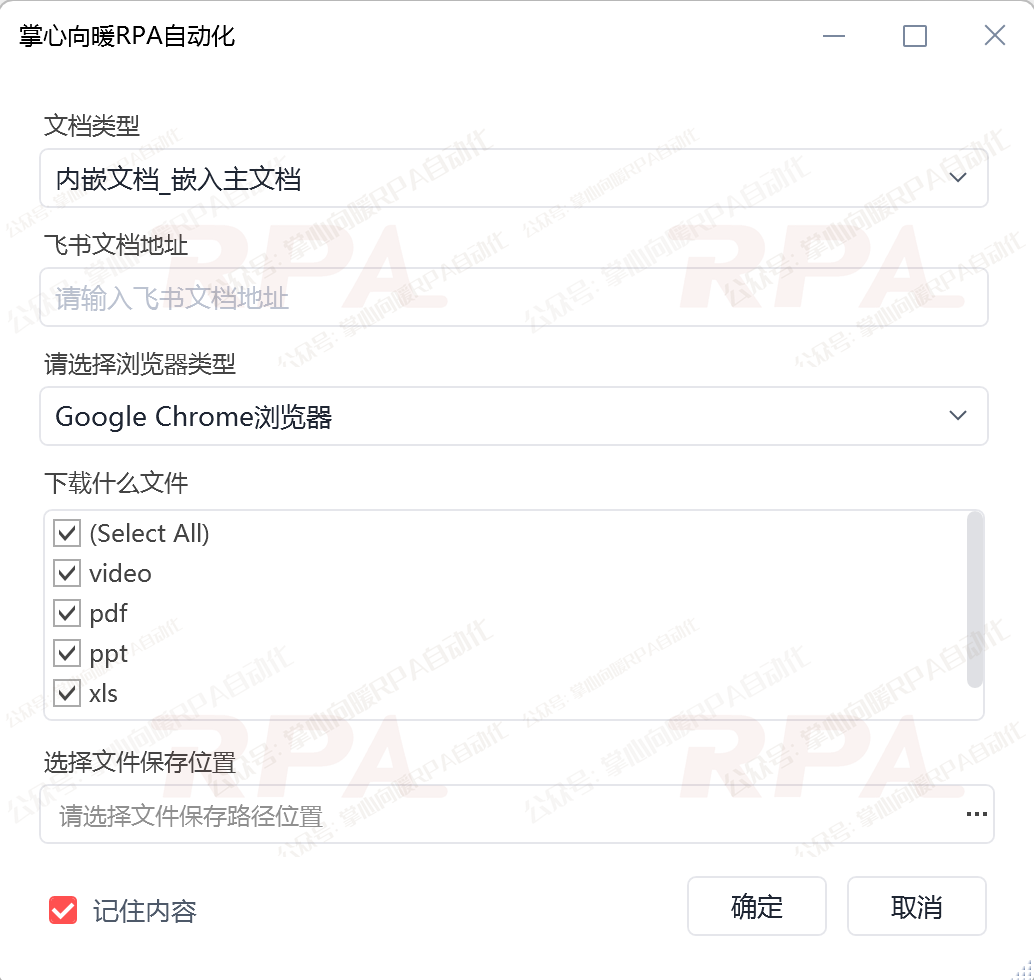
支持源格式文件下载:原文件是什么格式,下载下来就是什么格式
支持自定义保存路径:可自定义下载保存位置,方便分类管理
支持自定义浏览器运行:可选择谷歌、360、Edge等主流浏览器运行
内嵌文档支持"选择下载类型":可选择只下载:视频/PDF/PPT/表格/Word,默认全部下载
核心实现思路
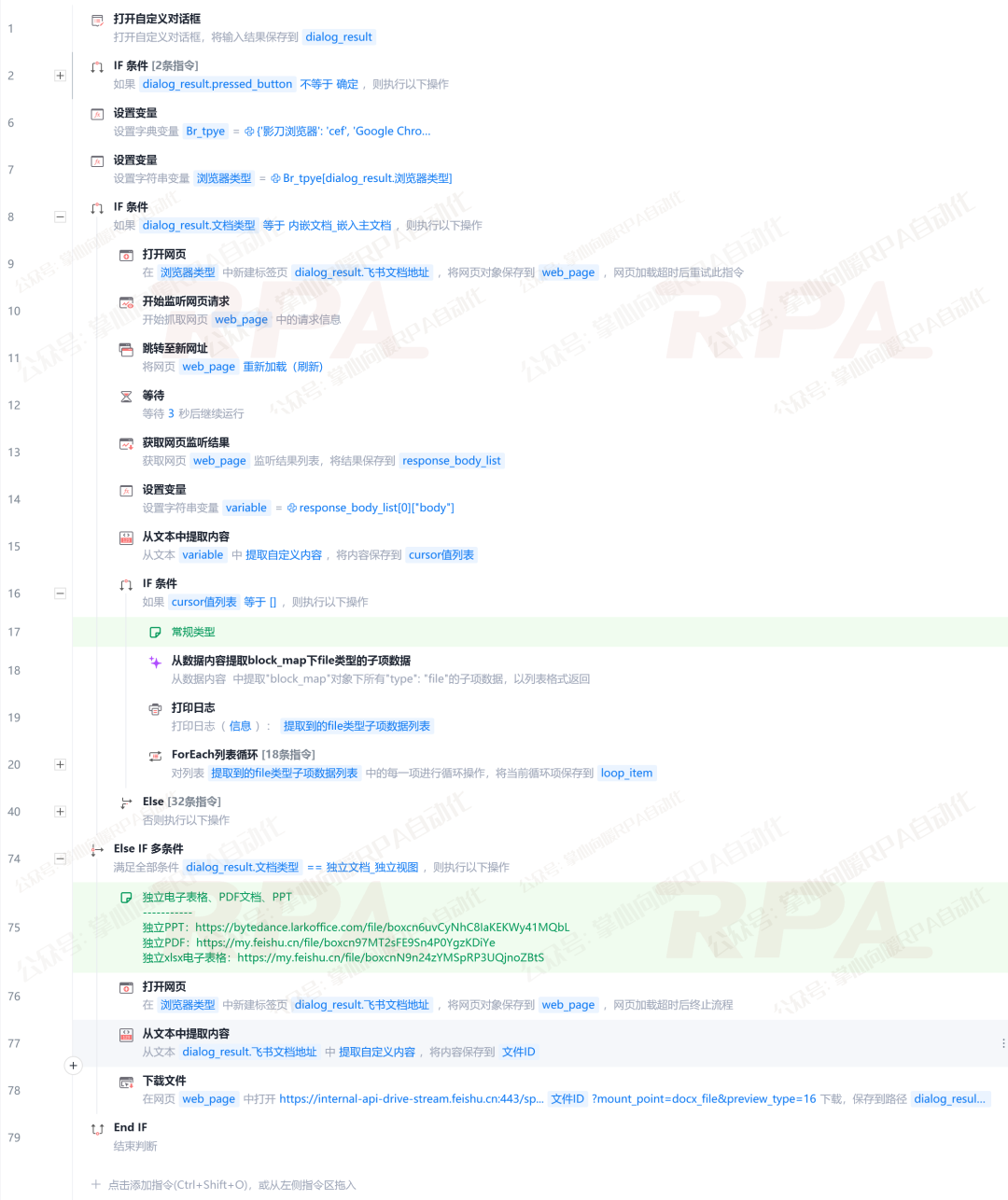
该应用采用了"网页监听 + HTTPS请求"的策略,核心逻辑在于监听飞书文档加载时的接口响应。
这里有一个难点,我们实际要监听的资源路径(Request URL)有以下两种类型,需要分别处理。
第1种:传入的飞书文档地址
也就是在应用启动参数里输入的飞书链接。RPA机器人先打开它,并从页面加载过程里拿到关键接口的返回值。
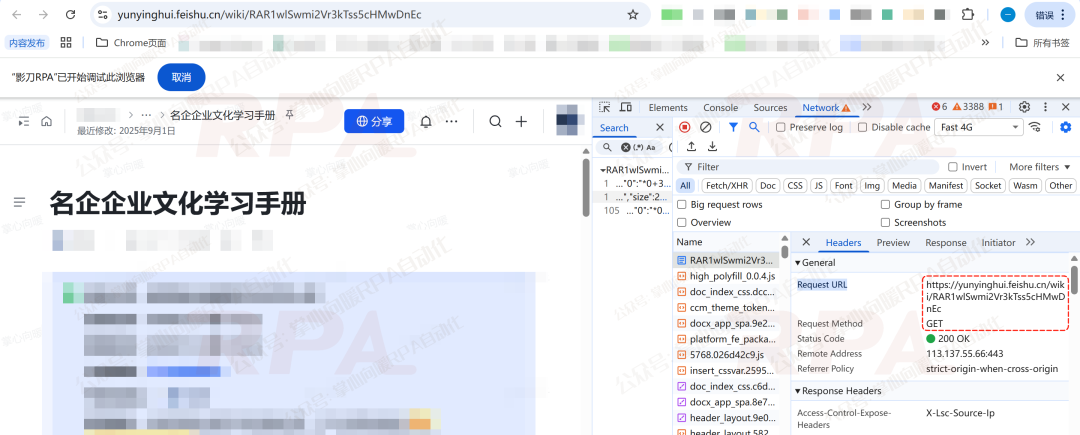
第2种:另一类特殊 Request URL
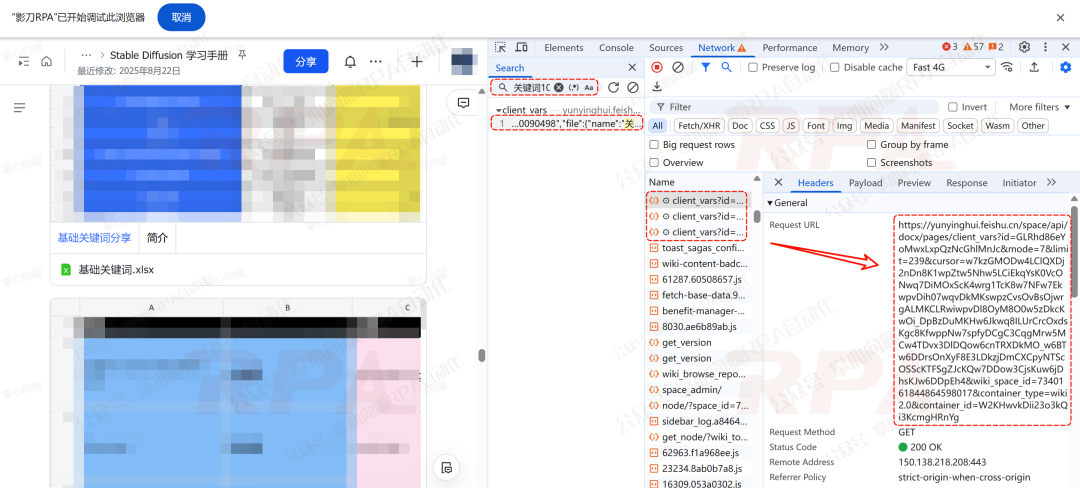
这类URL格式为:https://...feishu.cn/space/api/docx/pages/client_vars?id=...&mode=7&limit=239&cursor=...&wiki_space_id=...
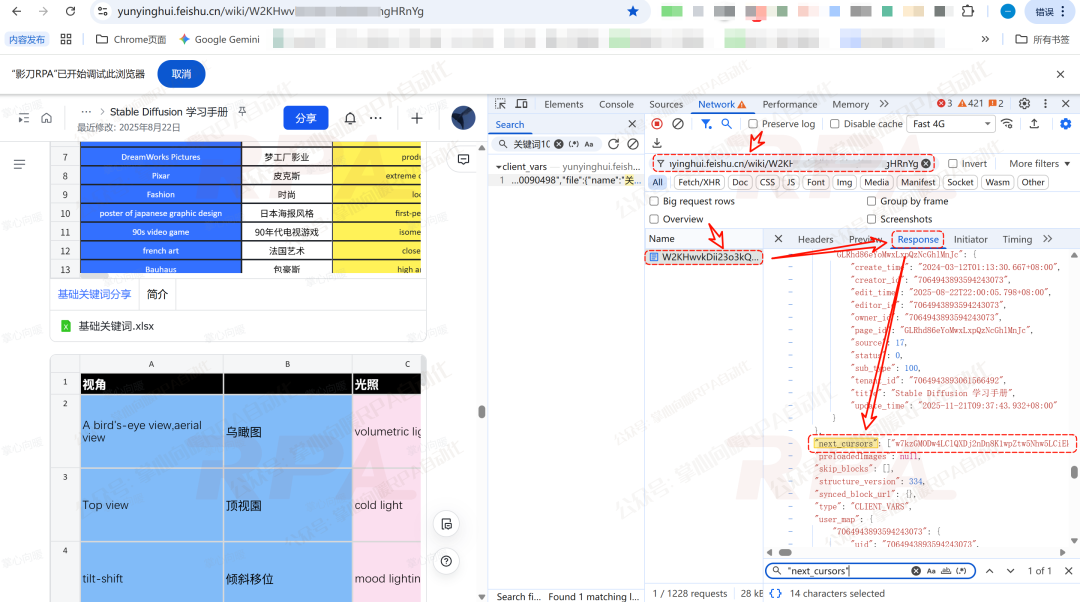
找到它后,直接发起请求,从响应数据中解析出附件/嵌入文件的下载信息。
为了让你实现无感下载,我从“传入的飞书文档地址”返回的响应中获取了这个Request URL中的变量值,从而还原出这个资源路径:
【文档域名】/space/api/docx/pages
/client_vars?id=【obj_token】&mode=7&
limit=239&cursor=cursor
值&wiki_space_id=【space_id】&container_type=wiki2.0&container_id=【wiki后面的ID】,这样就能做到:用户只需要复制飞书链接 → 机器人自动推导接口 → 自动解析 → 自动下载源文件。
收藏4



