使用浏览器IP代理躲避反爬 收藏
收藏
评论
收藏使用浏览器IP代理躲避反爬
恒
2024-03-13 20:44·浏览量:6009
恒
恒星
背景:
当我们在某些网站做大量查询或请求的时候,经常会遇到类似这样的提示:“您的查询过于频繁,请稍后查询。”
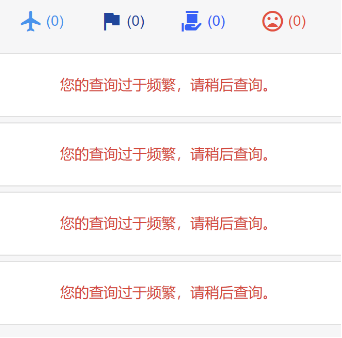
这时候证明已经触发了网站的反爬机制,服务器拒绝再向我们提供信息,我们再怎么刷新都查不到数据了。
解决思路:
当我们用同一个IP去高频查询的时候,对方服务器会怀疑我们这个IP是不是爬虫,把我们的IP临时限制访问,这里提供2种解决思路:
1、常规思路:让流程更加模拟人工,降低查询频率,在流程中设置随机等待时间。
2、使用浏览器IP代理,切换不同IP去查询。
第1种思路主要是避免被服务器当作爬虫触发反爬机制,通用性比较高,在多种场景下都可以用,但是严重影响效率。第2种思路主要针对仅监控IP的反爬机制,即使触发反爬也没关系,换个IP继续干,极大地提高了效率。
本文主要介绍思路2——使用浏览器IP代理躲避反爬
实现:
1、我们需要有很多IP,可以到网上搜一搜,有非常多的IP代理平台,价格也很便宜,一个IP几分钱。(一般都可以申请免费试用的哦,觉得好用再充值。)
2、设置好获取IP的方式,最好是用http请求的方式,IP代理平台直接返回IP,我们拿到IP之后就能做后续的步骤了
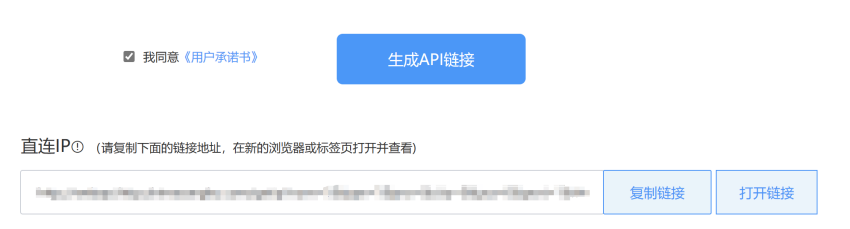
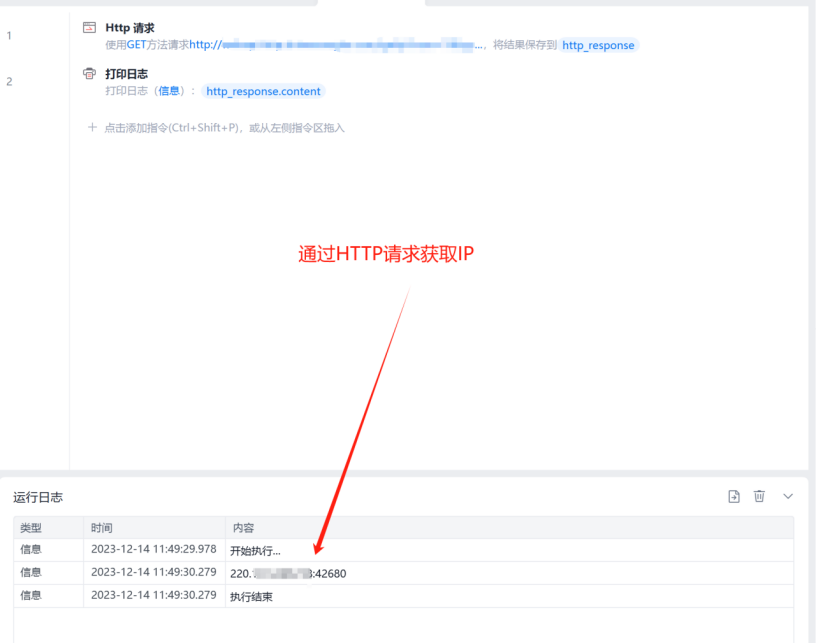

3、拿到IP后,怎么让浏览器使用这个IP呢?影刀的“打开网页”指令,高级设置填写命令行参数:--proxy-server="这里填写获取到的IP",这样在执行打开网页时,浏览器就会使用这个IP代理了(前提是浏览器必须先完全关闭)。
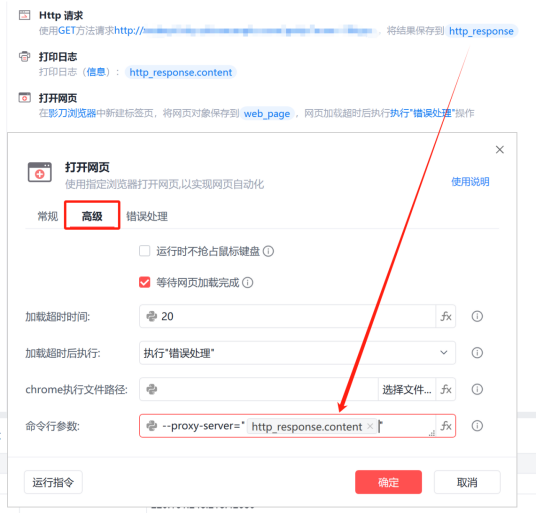
效果对比: 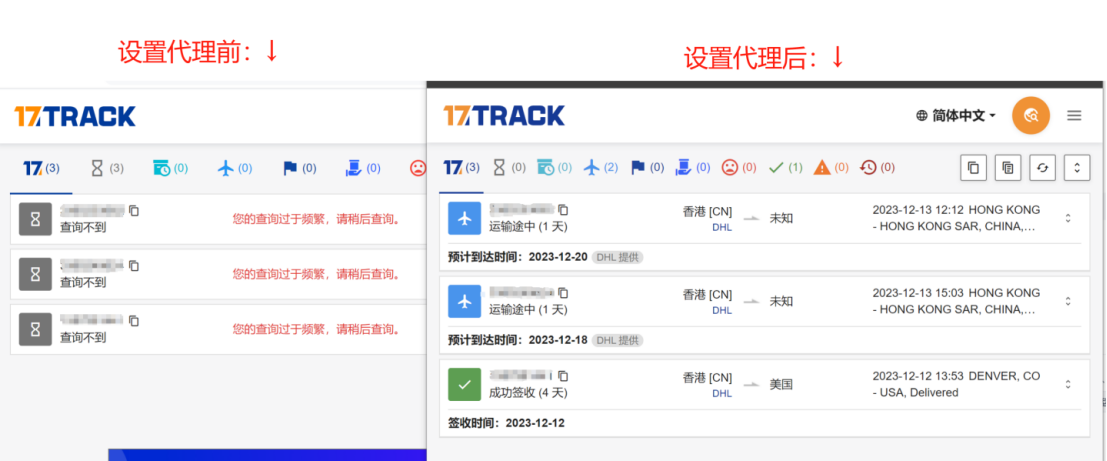

收藏35全部评论(1)
最新
发布评论
评论





