钉钉在线表格如何下载?我是这样做的 收藏
收藏
评论
收藏钉钉在线表格如何下载?我是这样做的

2024-07-23 15:15·浏览量:1131
曾诚
钉钉表格在使用api操作起来终究是不那么好用,所以下载下来是处理表格的最好方式,所以我把钉钉表格的下载链接给抓了下来,供大家参考,具体代码如下:
import time
import requests
import json
class DingXlsxDownloads:
def __init__(self, download, token, key, timeout=10):
self.TOKEN = token
self.KEY = key
self.DOWNLOADURL = download
self.TIMEOUT = timeout
def get_content(self) -> dict:
headers = {
"a-doc-key": self.KEY,
"content-type": "application/json",
}
cookies = {
"doc_atoken": self.TOKEN,
}
url = "https://alidocs.dingtalk.com/api/document/data"
response = requests.post(url, headers=headers, cookies=cookies,
data=json.dumps({}, separators=(',', ':'))).json()
try:
return {"name": response["data"]["fileMetaInfo"]["name"], "size":
response["data"]["documentContent"]["checkpoint"]["cpOssSize"], "content": json.loads(
response["data"]["documentContent"]["checkpoint"]["content"])}
except Exception as e:
print(response)
content = requests.get(response["data"]["documentContent"]["checkpoint"]["extraParts"]["s1"]["ecpOssUrl"], headers={"Accept-Charset": "utf-8"})
print(content.text)
return {"name": response["data"]["fileMetaInfo"]["name"], "size":
response["data"]["documentContent"]["checkpoint"]["cpOssSize"], "content": json.loads(content.text)}
def get_urls(self, name, size) -> dict:
headers = {
"a-doc-key": self.KEY,
"content-type": "application/json",
}
cookies = {
"doc_atoken": self.TOKEN,
}
url = "https://alidocs.dingtalk.com/core/api/resources/9/upload_info"
data = {
"size": size,
"resourceName": name,
"contentType": ""
}
data = json.dumps(data, separators=(',', ':'))
urls = requests.post(url, headers=headers, cookies=cookies, data=data).json()
return urls
def put_data(self, url, content) -> bool:
data = json.dumps(content, separators=(',', ':'))
response = requests.put(url, data=data)
if response.status_code == 200:
return True
else:
return False
def get_jobid(self, url) -> str:
headers = {
"a-doc-key": self.KEY,
"content-type": "application/json",
}
cookies = {
"doc_atoken": self.TOKEN
}
data = {
"exportType": "dingTalksheetToxlsx",
"storagePath": url
}
data = json.dumps(data, separators=(',', ':'))
response = requests.post("https://alidocs.dingtalk.com/core/api/document/submitExportJob", headers=headers,
cookies=cookies, data=data).json()
return response["data"]["jobId"]
def get_download_url(self, job_id) -> str:
headers = {
"a-doc-key": self.KEY,
}
cookies = {
"doc_atoken": self.TOKEN,
}
url = "https://alidocs.dingtalk.com/core/api/document/queryExportJobInfo"
params = {
"jobId": job_id
}
response = requests.get(url, headers=headers, cookies=cookies, params=params).json()
return response["data"]["ossUrl"]
def run(self):
dic = self.get_content()
print(dic)
url_dic = self.get_urls(dic["name"], dic["size"])
result = self.put_data(url_dic["data"]["uploadUrl"], dic["content"])
if result:
job_id = self.get_jobid(url_dic['data']["storagePath"])
for i in range(self.TIMEOUT):
try:
download_url = self.get_download_url(job_id)
print("请求成功")
data = requests.get(download_url)
if data.status_code == 200:
with open(self.DOWNLOADURL, 'wb') as file:
file.write(data.content)
return self.DOWNLOADURL
else:
return f'请求失败,状态码:{data.status_code}'
except Exception as e:
print(f"下载请求失败{i + 1}次")
time.sleep(1)
continue
else:
return "下载失败"
这个类一共有4个参数:
- download:下载路径,如 C:\Users\Admin\Desktop\a.xlsx
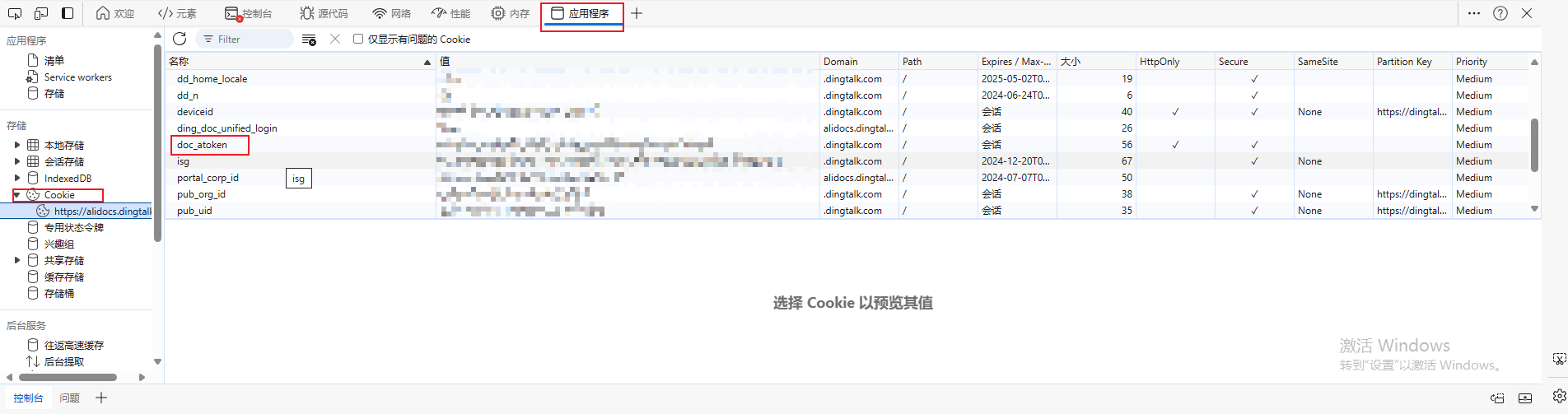
- token:用户的token,如下图所示获取,在浏览器打开对应表格,在开发者控制台获取,需登录钉钉,一般不会变
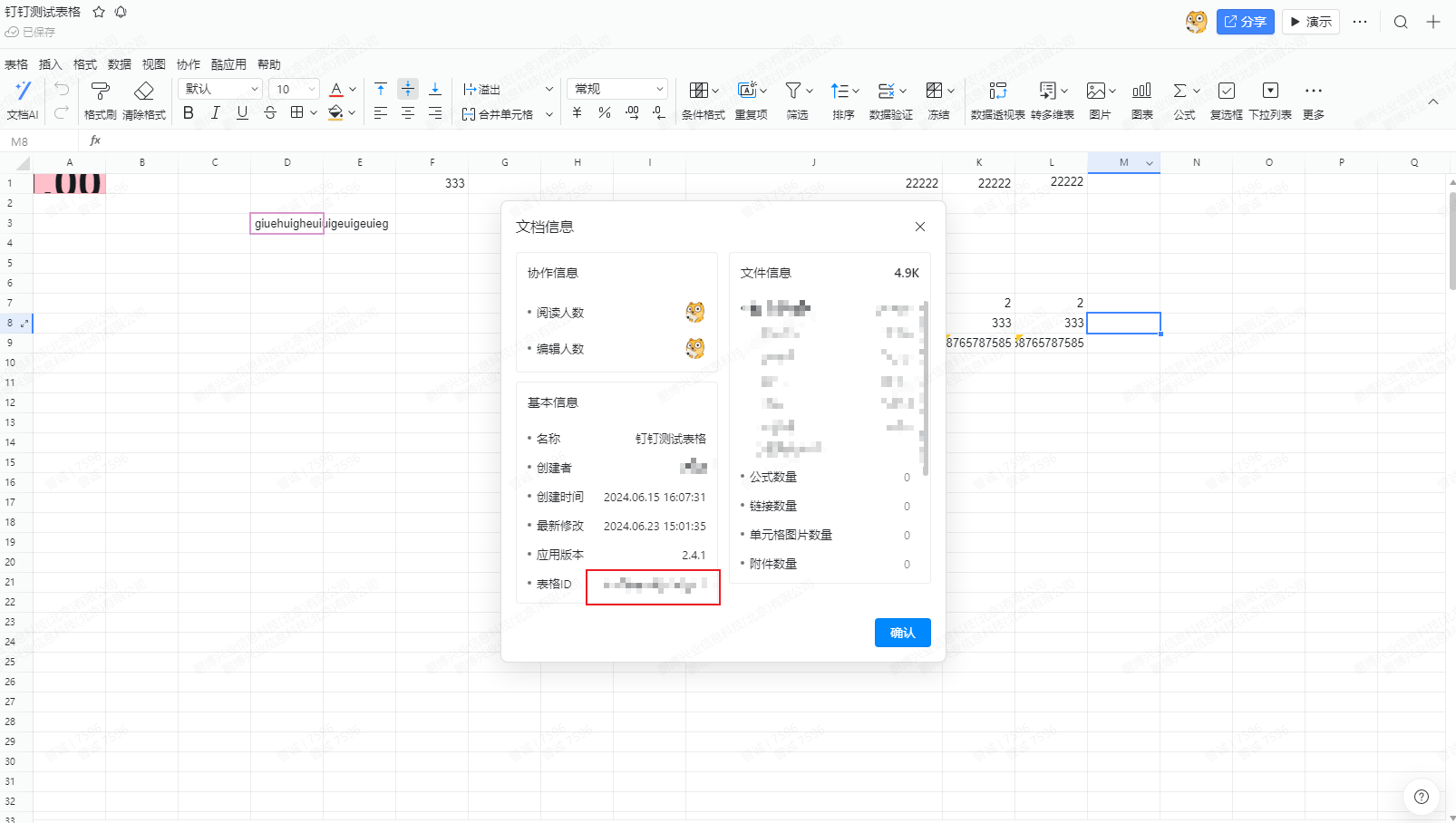
- key:表格id,如下图所示获取
- timeout:下载超时时间,可不填
使用方式:
DingXlsxDownloads("C:\Users\Admin\Desktop\a.xlsx", "your_token", "your_book_id", 10).run()然后就可以直接下载到对应位置,方便大家获取并处理文件啦,也不需要打开网页或者捕获元素的方式来下载了

收藏全部评论(1)
最新
发布评论
评论




