 收藏
收藏元素捕获实践总结

RPA的整个执行过程中,无论是数据抓取、表单填写、按钮点击还是页面导航等操作,都离不开对目标元素的准确识别与定位。从影刀的默认捕获方式到CSS选择器、XPath选择器到图像识别,每一种定位方式都有其适用的特定条件和优势,同时也会有一些“注意事项”,在这里将一一介绍。

捕获方式介绍
影刀内嵌的捕获方式(简单、常用)

影刀提供了三种捕获元素的方式:'标准模式捕获'、'深度模式捕获'和'CV智能模式捕获':
标准模式捕获:对网页元素进行捕获,需要操作网页元素可以选择该捕获方式,同时也支撑捕获win软件元素;
深度模式捕获:针对windows软件元素设计的捕获模式;
CV智能模式捕获:无法用以上两种捕获模式都无法捕获的情况,可以尝试使用此模式进行捕获(注:官方说该模式通过图像识别捕获,但效果并不好(图像识别的方法后面另有介绍)。所捕获元素含极易改变的属性,如cls、token,极不稳定)。
这三种方式捕获到元素后,都可通过编辑按钮,对元素节点进行编辑,取消掉容易变化的属性,保留相对比较稳定且能精准定位所需元素的数据。
XPath选择器和CSS选择器(灵活、准确)
XPath选择器相关视频教程:https://www.bilibili.com/video/BV1ZV4y1v7z1
CSS选择器相关视频教程:https://www.bilibili.com/video/BV1pu4y1N7hx
注:这两种定位方式只支持网页元素的捕获
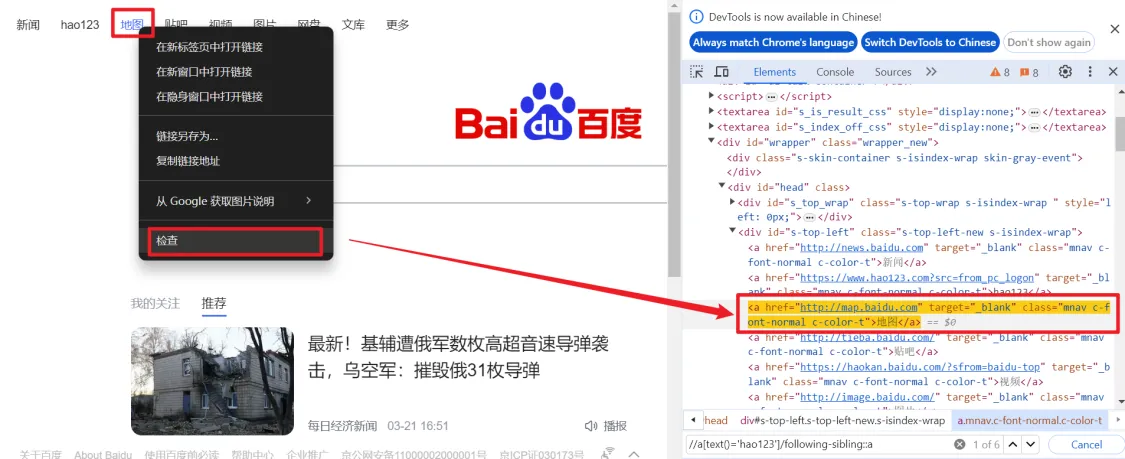
XPath选择器和CSS选择器都是用于在HTML文档或XML文档中定位和选取特定元素的技术,所以只支持对网页元素进行定位,这两种选择器的核心原理在于,它们能够深入到网页的源码,根据元素的标签名称、属性及其值、层级关系等多种特征,精确地定位元素。在页面元素上右键检查时可以看到此网页对应的HTML源码以及此元素所在的位置,通过观察找到目标元素的特征,从而定位一个或一类元素。
XPath选择器
XPath(XML Path Language)是一种专门用于在XML文档(包括HTML作为其一种特殊形式)中查找信息的语言。它采用路径表达式的方式,允许用户通过描述元素之间的层次关系和属性特征来定位和选取具体的XML或HTML节点。
以下列举了一些定位百度首页中定位“地图”元素的XPath表达式:
# “/” 表示从文档根节点开始搜索,逐层定位元素,a标签有多个时,[3]表示从上往下取第三个
/html/body/div/div/div/a[3]
# “[]” 中括号内指定元素搜索的条件表达式
# text()='地图' 表示根据标签的文本值定位,如:<a>地图</a>
/html/body/div/div/div/a[text()='地图']
# “//” 表示查找任意深度的匹配节点
/html/body//a[text()='地图']
//a[text()='地图']
# 支持使用逻辑运算符 and 与 or 来组合多个条件
# 标签的属性需要用“@”,如@class、@id、@target
//a[text()='地图' and @class='mnav c-font-normal c-color-t']
# 查找当前节点之后的同级节点
//a[text()='hao123']/following-sibling::a[1]
# 查找当前节点之前的同级节点
//a[text()='贴吧']/preceding-sibling::a[1]
# 查找当前节点的子节点
//div[@id='s-top-left']/child::a[text()='地图']
# (更多关于节点间关系的表达式将在下文中进一步介绍)
# 查询当前节点或其子节点的值包含某字符串(模糊查询)
//a[contains(string(),'地')]在XPath中,节点间关系表达式是非常关键的一部分,用于描述XML或HTML文档中元素之间的层级、亲属和其他结构性关系。例如:
- child:查找当前节点的子节点。
- parent:查找当前节点的父节点。
- descendant:查找当前节点的所有后代节点。
- ancestor:查找当前节点的所有先辈节点。
- following-sibling:查找当前节点之后的同级节点。
- preceding-sibling:查找当前节点之前的同级节点。
- 等等。
CSS选择器
CSS选择器基于CSS(层叠样式表)样式表语言的选择规则,它是CSS语法中用于识别和指定HTML文档中应应用特定样式的元素的关键部分。前端开发的小伙伴应该非常熟悉。
还是以百度首页中定位“地图”元素为例演示如何编写CSS选择器表达式:
# “>”是逐层定位元素,和XPath中的“/”相似,nth-of-type(3)选择div下第三个a标签
html>body>div a:nth-of-type(3)
# a标签中href属性=“http://map.baidu.com”的元素
a[href="http://map.baidu.com"]CSS选择器不支持通过标签内容“地图”这种文本来定位,只能通过标签自身的属性定位
验证表达式
1、控制台Elements页下进行搜索(此方式XPath和CSS表达式均可校验)
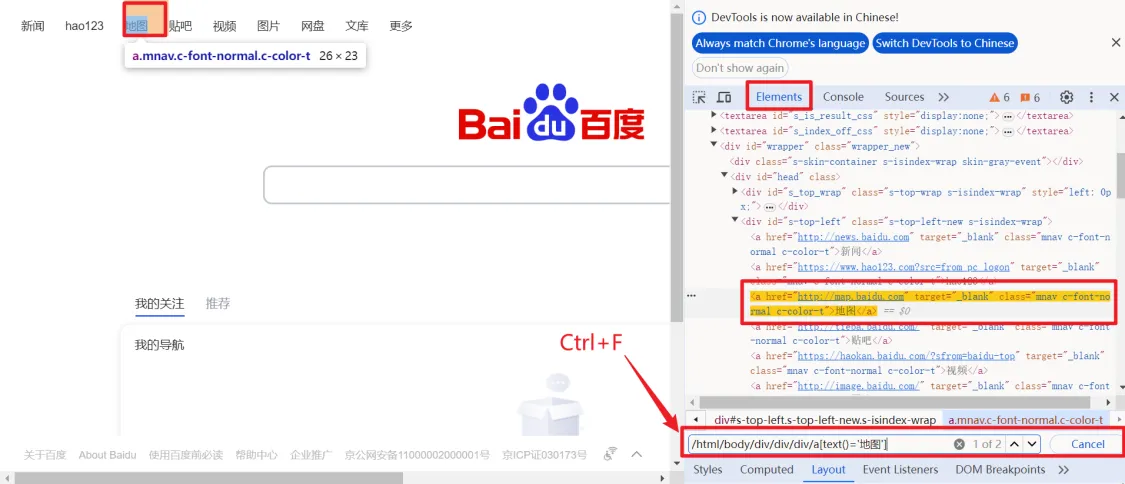
2、下载浏览器插件“XPath Helper”,(只能校验XPath表达式)
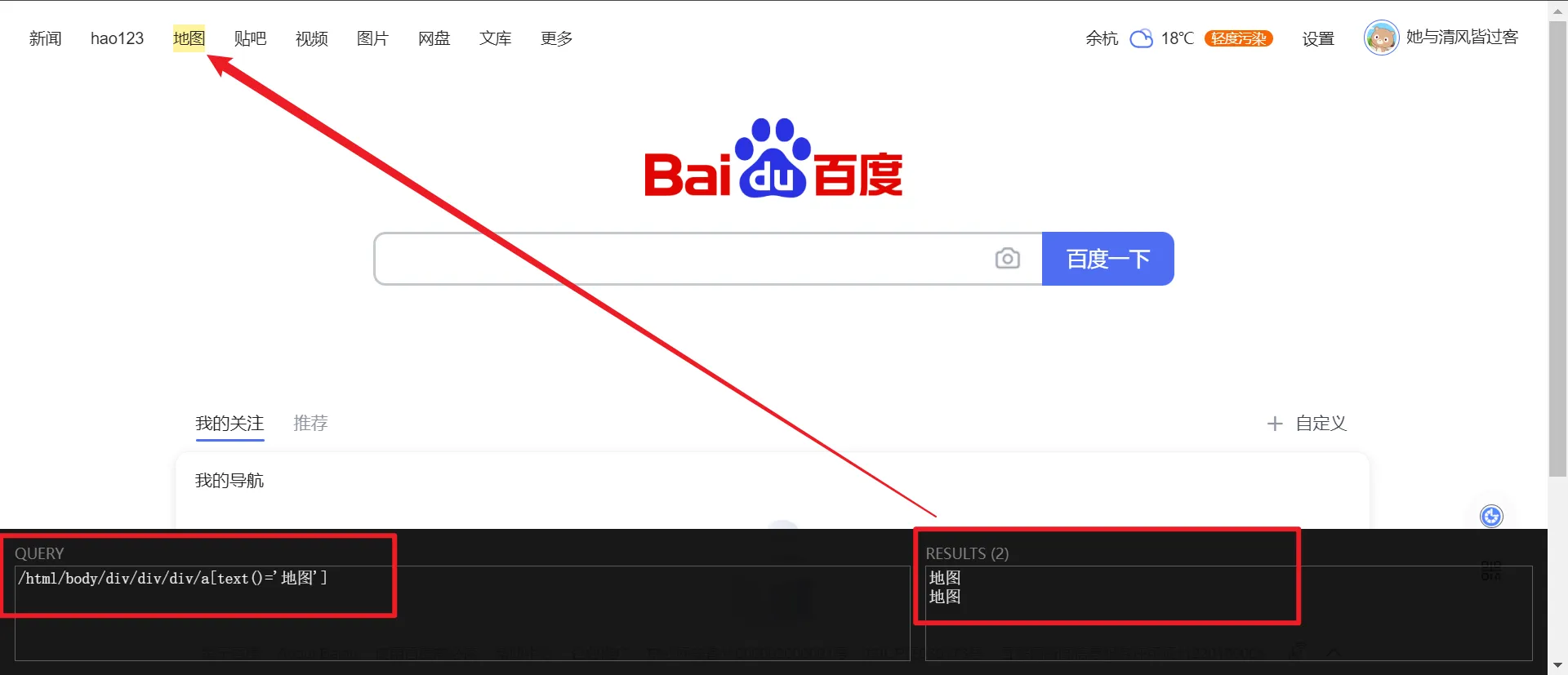
XPath Helper”的安装:hgimnogjllphhhkhlmebbmlgjoejdpjl.zip

解压后,将.CRX文件拖到扩展程序页面完成安装
影刀中使用以上方式捕获元素
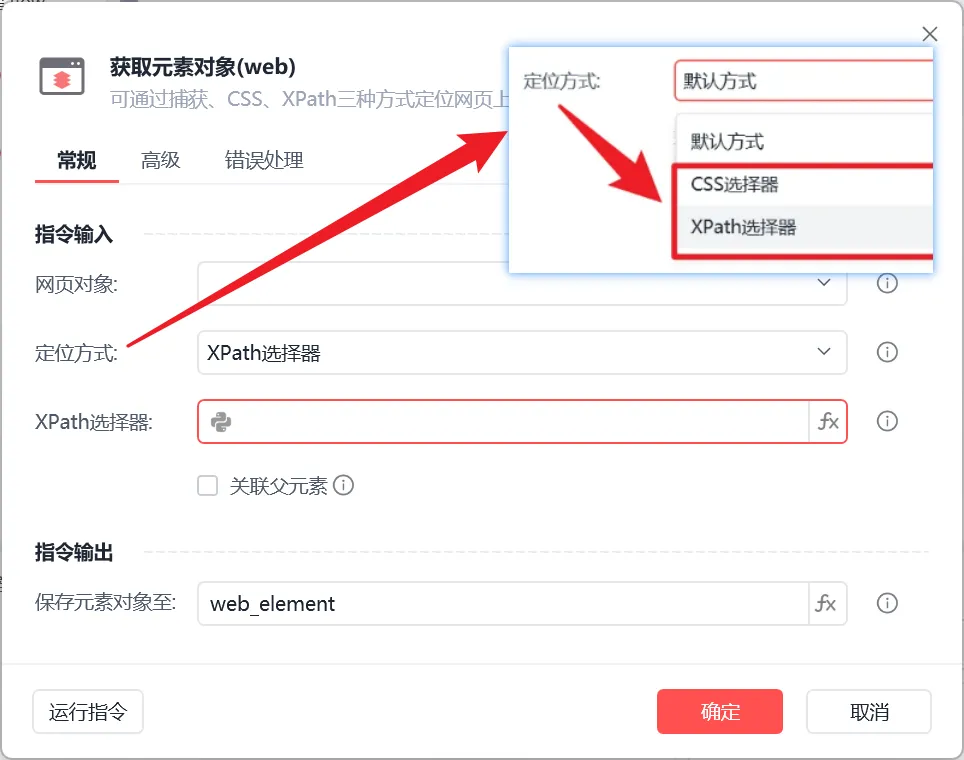
在影刀中使用这两种定位方式时,首先通过以下指令获取元素对象:

选择定位方式CSS选择器或XPath选择器,在输入框中输入对应的表达式即可:
图像识别
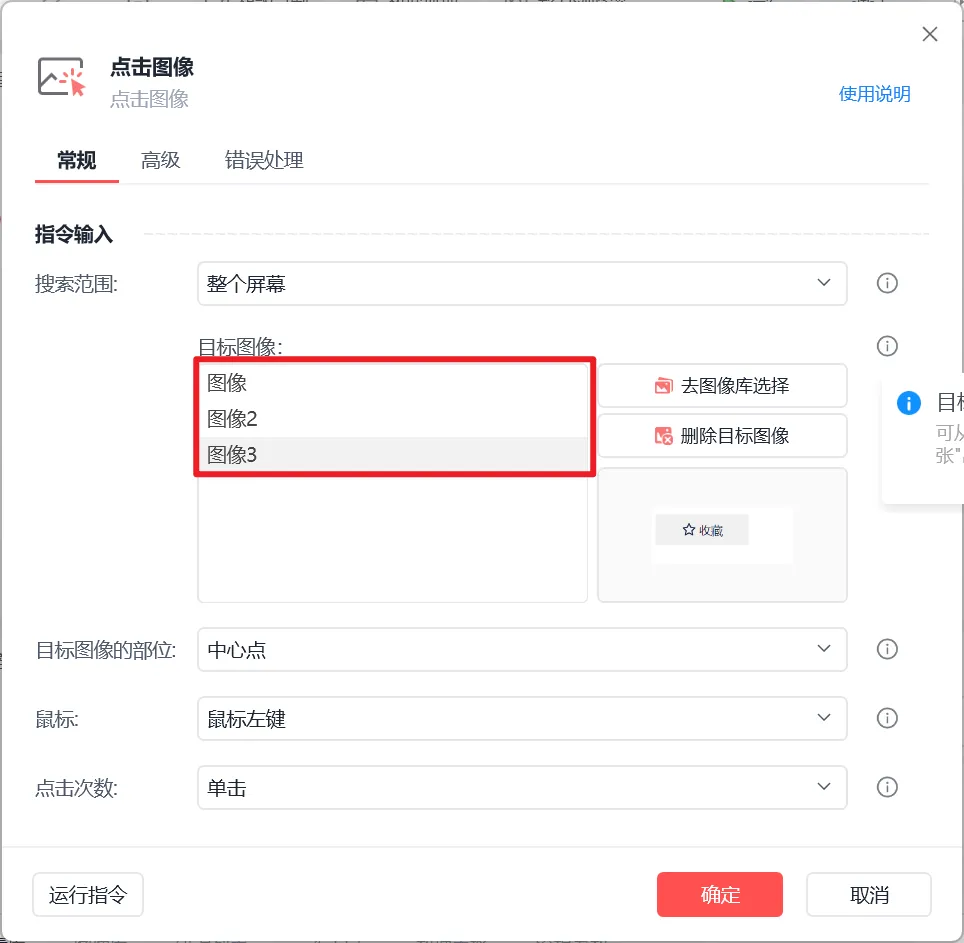
对于无法通过以上方法进行捕获的元素,可以尝试使用图像识别定位,但此方式容易收到屏幕分辨率的影响,最好在运行设备上进行开发,同时页面缩放也可能会导致图像识别不到。
影刀有支持“图像识别定位”的指令,使用起来也很简单,建议添加多个图像以提高图像识别的准确率:
屏幕横纵坐标定位
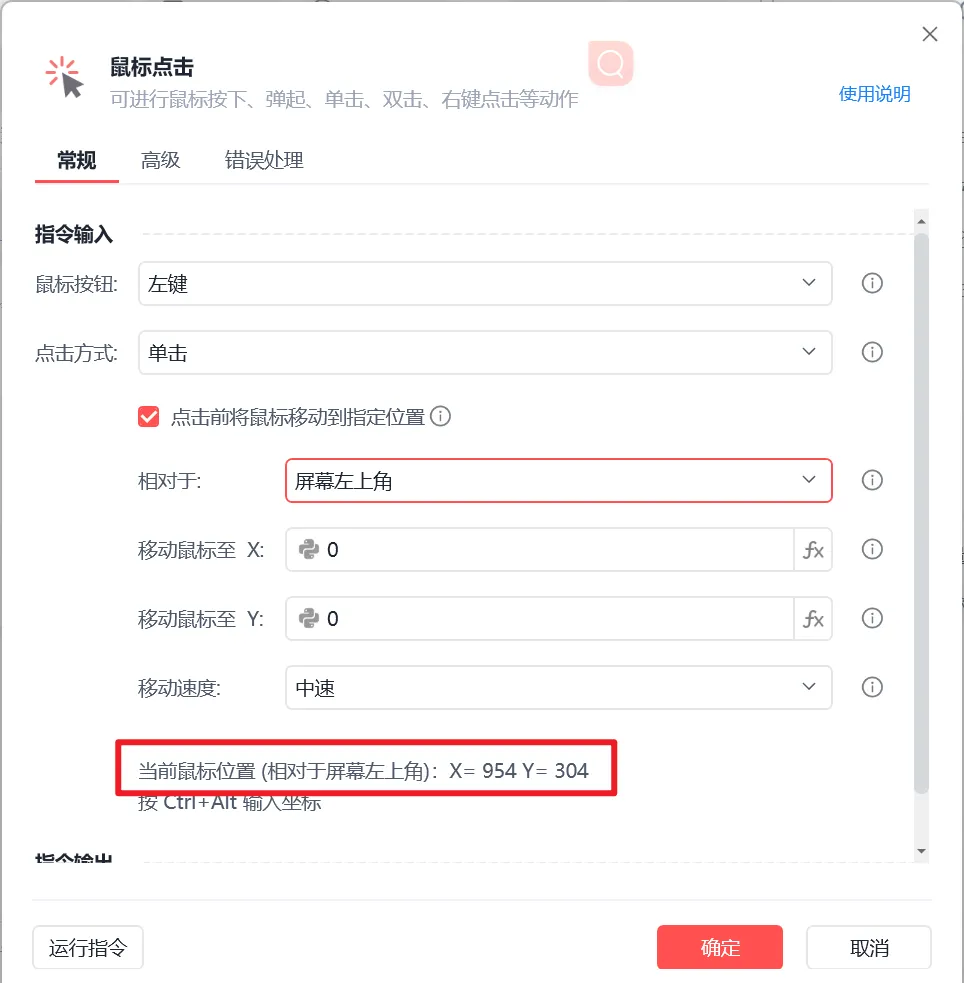
屏幕横纵坐标定位,就是在电脑屏幕上,通过确定元素在二维平面上的精确位置来实现对屏幕对象的定位。在不同的电脑分辨率环境下,屏幕尺寸和像素密度会发生变化,这就意味着相同的坐标值可能对应的实际物理位置会有差异。
使用场景选择分析和坑
使用场景选择
大多数情况下使用影刀自带的元素捕获即可,这种方式操作简单快捷(取消掉容易变化的属性,保留相对比较稳定且能精准定位所需元素的数据),对于复杂的Web元素建议使用XPath进行定位,复杂的Win元素尝试使用‘深度捕获’或‘图像识别捕获’,经实践‘图像识别捕获’的准确度还是很高的。
注意
1、在捕获Web元素时,有些信息其实不是Web元素,而是属于浏览器提供的内置功能,是Win元素,所以XPath
2、MAC的元素偏移量问题
mac上使用捕获谷歌浏览器下的元素时,存在偏移问题,导致不能使用,另外,在某浏览器捕获的元素无法在另一个浏览器上运行(使用win没有这些问题)
【方案一】:使用影刀自带的浏览器,那么程序在运行时也必须运行在影刀自带的浏览器上,否则会定位不到元素
【方案二】:降低谷歌浏览器版本:https://www.yuque.com/pengzhiqiang999/xiaokenai/fubpdho05yckgikf?singleDoc#
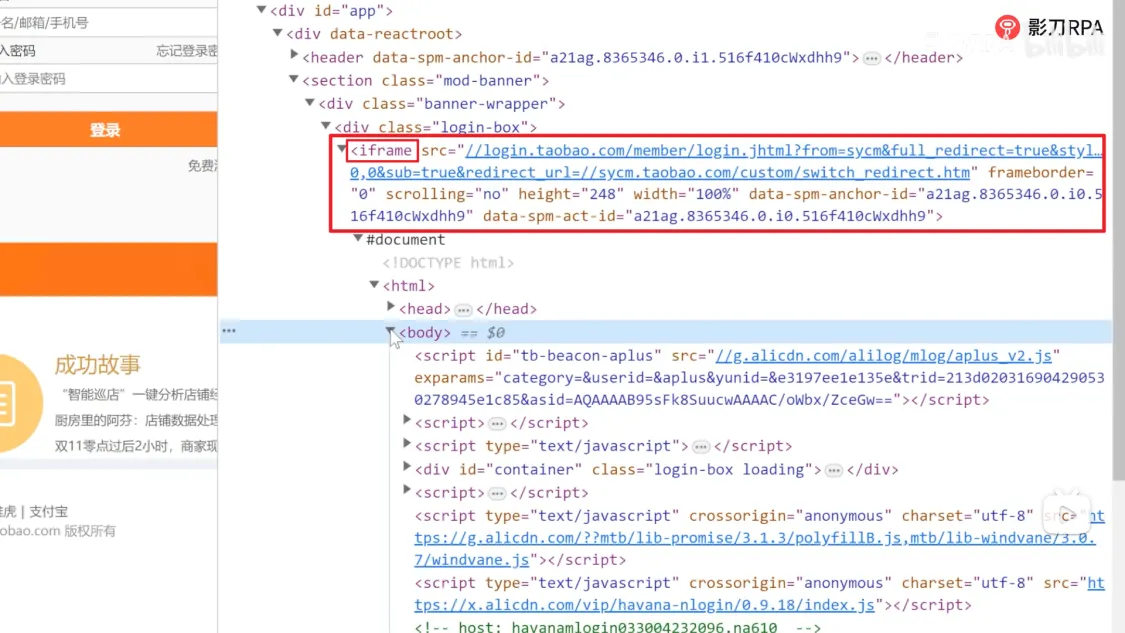
3、跨域元素XPath无法直接定位,需特殊处理
解决方案:https://www.bilibili.com/video/BV1ZV4y1v7z1?p=4

收藏11



