影刀RPA_使用影刀获取cookies配合reqeuest模块进行爬虫_我的学习笔记_by上海小分队 收藏
收藏
回答
收藏影刀RPA_使用影刀获取cookies配合reqeuest模块进行爬虫_我的学习笔记_by上海小分队

2023-03-13 15:18·浏览量:1371
小可耐教你学影刀RPA【哔哩哔哩同名】
代码
https://github.com/PYTHON3webspider/scrapelogin2
语雀 地址
https://www.yuque.com/pengzhiqiang999/python/yniiakfv6fzo3oph?singleDoc# 《使用影刀获取cookies配合reqeuest模块进行爬虫》
练习网站
https://login2.scrape.center/login
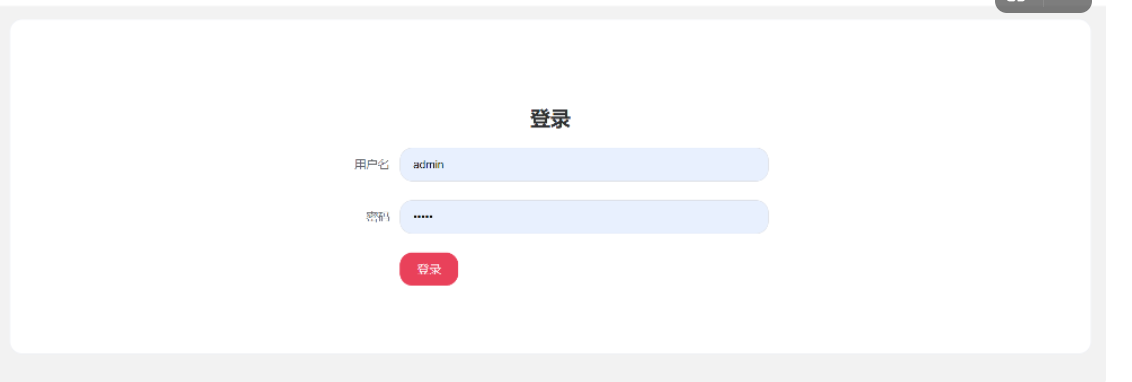
账号密码 admin admin
实现过程
可视化代码
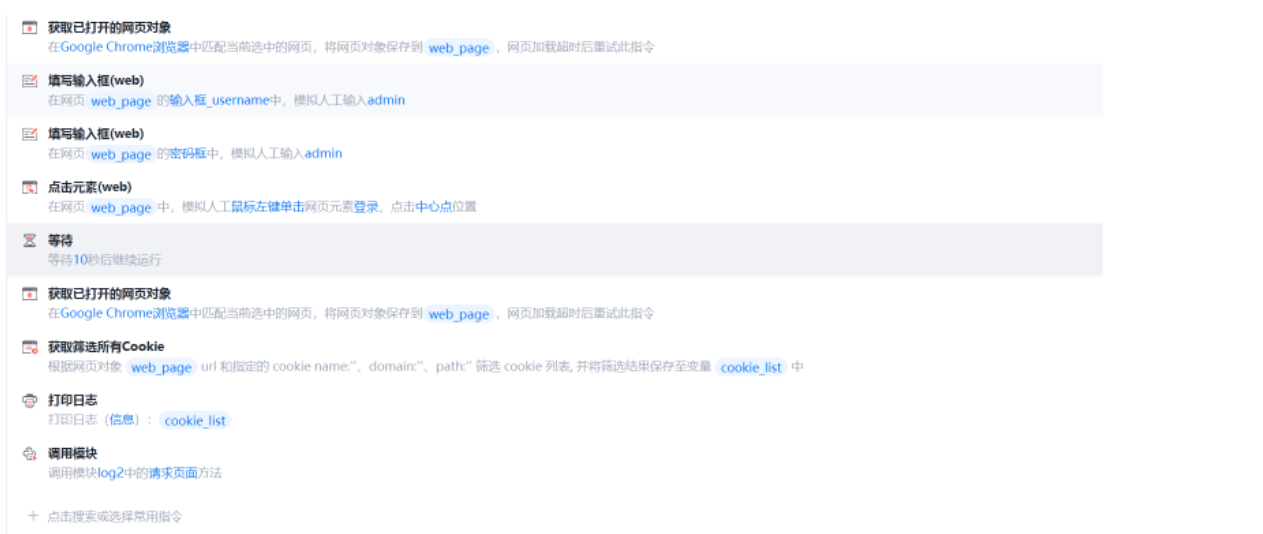
log2代码
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import time
def main(args):
pass
from urllib.parse import urljoin
import requests
import time
BASE_URL = 'https://login2.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
"""
用影刀代替
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(BASE_URL)
browser.find_element_by_css_selector('input[name="username"]').send_keys(USERNAME)
browser.find_element_by_css_selector('input[name="password"]').send_keys(PASSWORD)
browser.find_element_by_css_selector('input[type="submit"]').click()
# get cookies from selenium
cookies = browser.get_cookies()
print('Cookies', cookies)
browser.close()
time.sleep(10)
"""
def 请求页面(cookies):
# set cookies to requests
session = requests.Session()
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value'])
response_index = session.get(INDEX_URL)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)遇到的坑
https://blog.csdn.net/qq_16555103/article/details/107901931
实际是 url错误 无语无语 真实代码
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
def main(args):
pass
from urllib.parse import urljoin
# from selenium import webdriver
import requests
import time
BASE_URL = 'https://login2.scrape.center/page/4'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
# browser = webdriver.Chrome()
# browser.get(BASE_URL)
# browser.find_element_by_css_selector('input[name="username"]').send_keys(USERNAME)
# browser.find_element_by_css_selector('input[name="password"]').send_keys(PASSWORD)
# browser.find_element_by_css_selector('input[type="submit"]').click()
# time.sleep(10)
# # get cookies from selenium
# cookies = browser.get_cookies()
# print('Cookies', cookies)
# browser.close()
def 请求页面(cookies):
# set cookies to requests
session = requests.Session()
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value'])
response_index = session.get("https://login2.scrape.center/page/4",verify=False)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
收藏2全部回答(1)
最新
发布回答
回答




