【小技巧】视频下载小招式--http请求攻克微博视频 收藏
收藏
评论
收藏【小技巧】视频下载小招式--http请求攻克微博视频
阿
2024-05-30 21:02·浏览量:1870
阿
阿深
一、问题场景:
最近在帮客户研究微博的数据爬取时,遇到了颇多的问题,其中有一个就是:微博视频找不到可供下载的连接哇,需要大批量爬取下载,该怎么破?👇
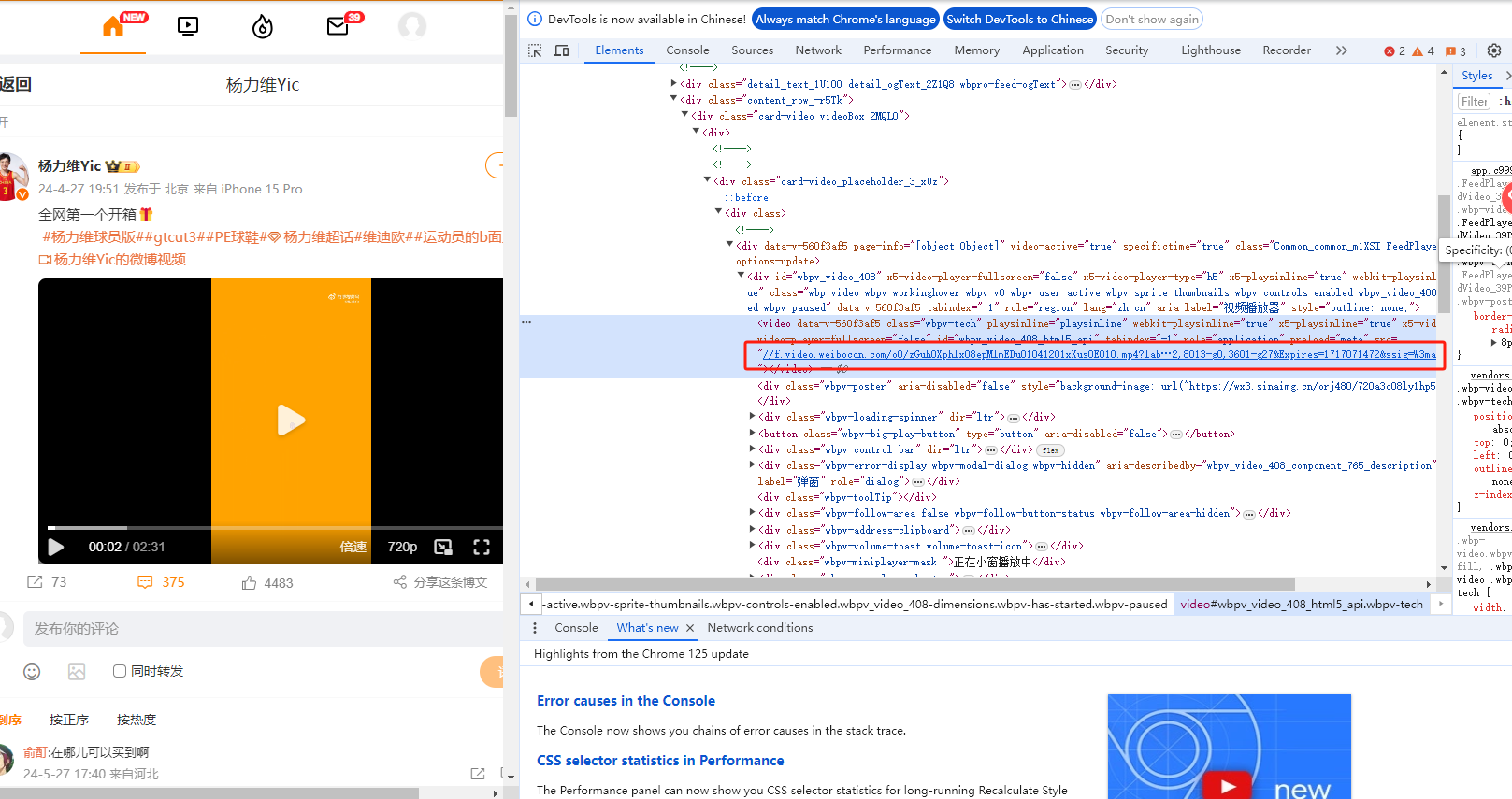
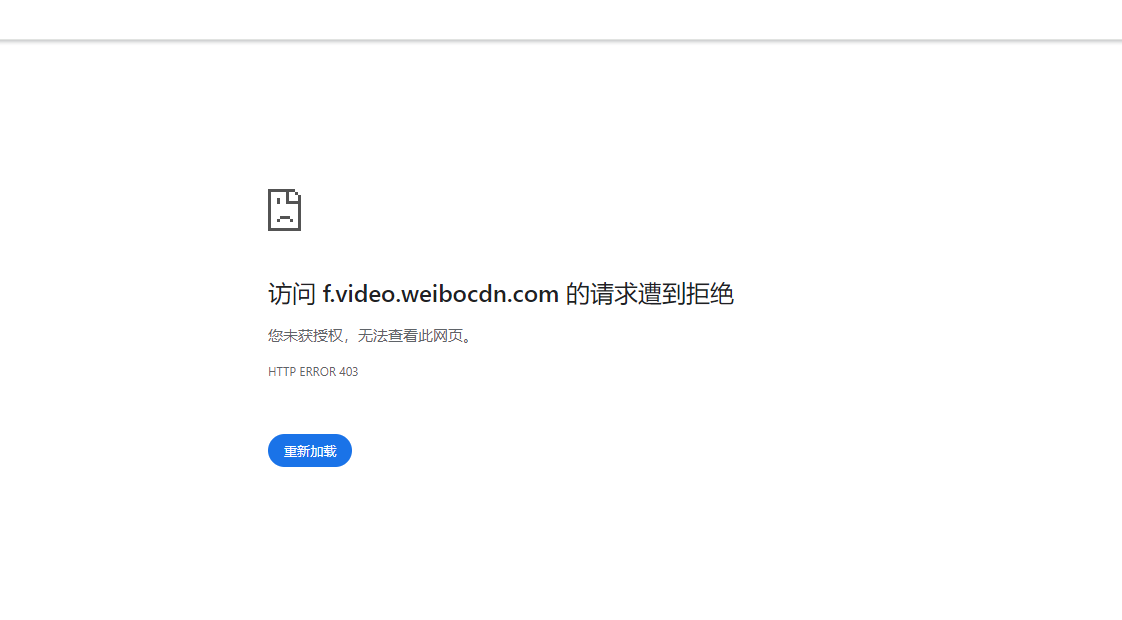
如图所示,直接访问从网络源码中拿到的这个链接,会显示请求遭到拒绝。:
https://f.video.weibocdn.com/o0/zGuhOXphlx08epMlmEDu01041201xXus0E010.mp4?label=mp4_720p&template=720x1280.24.0&media_id=5027855772352571&tp=8x8A3El:YTkl0eM8&us=0&ori=1&bf=4&ot=v&lp=000024grZZ&ps=mZ6WB&uid=3BKQqf&ab=,8012-g2,8013-g0,3601-g27&Expires=1717071472&ssig=W3ma7Hx%2FEv&KID=unistore,video 二、尝试方案:
1. 查看了社区相关的帖子,找到了昕怡大佬的帖子: 网页视频下载,源码中找不到视频链接?这怎么搞?---- by.广州组 。发现并不适用,因为找不到M3u3格式的文件,而找到了媒体资源打开也仍然是访问被拒绝👇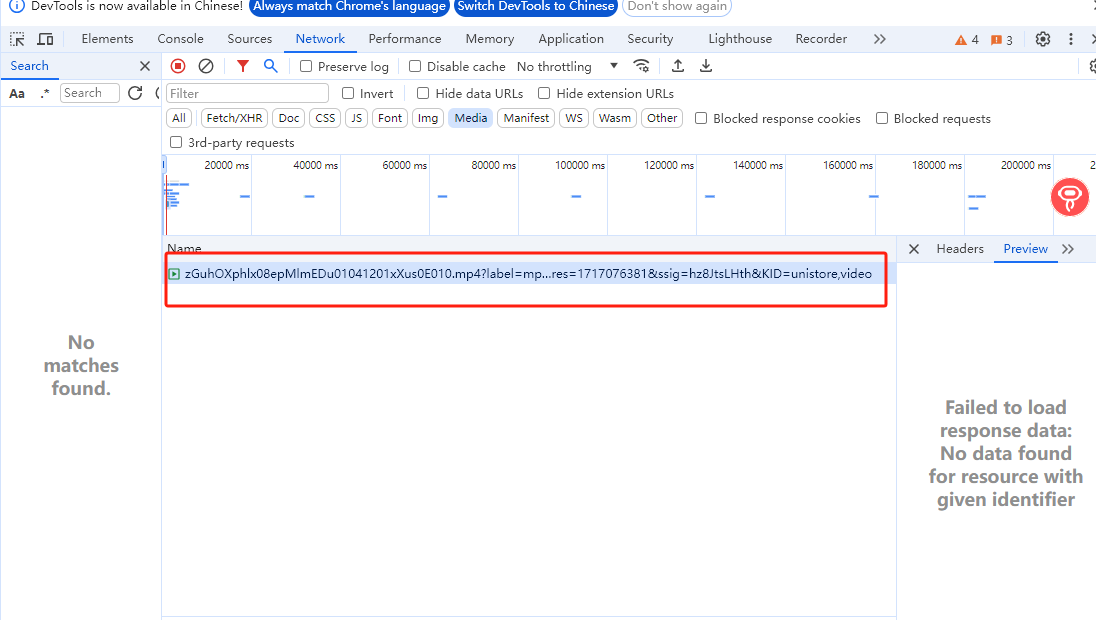
2. 然后我试着对这个链接的结构进行了分析,例如(https://f.video.weibocdn.com/o0/zGuhOXphlx08epMlmEDu01041201xXus0E010.mp4 )看起来是实际地址,但是访问仍然是相同的结果。
3. 再仔细分析一下,可以发现这个网址后面带着许多参数,例如视频格式分辨率(720x1280)、到期时间戳(Expires=1717071472)、签名参数ssig、uid等等,那这些可能都是导致我们无法直接访问这个链接进行视频下载的原因(具体原理不懂)
4. 鉴于过往的经验,我想到了一个方案:影刀+m3u3插件(这个插件亲测挺好用,后续有机会可以再分享一篇关于这个插件的用法)。然而,拿到的仍然是网络源码的那个url,直接点击下载也会变成txt文件显示无法提取👇
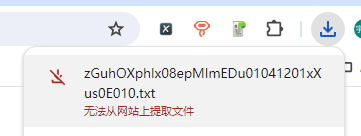
三、最终方案:
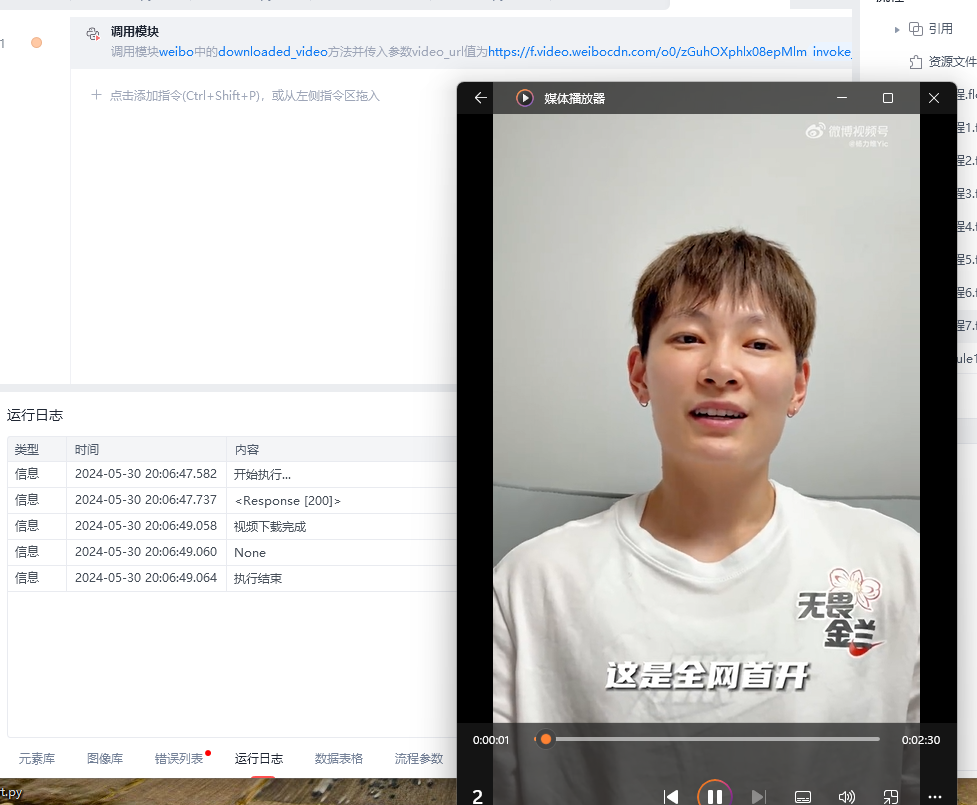
在尝试了以上方案均无果的情况下,我想到了另一种方案:利用py代码模拟发送请求,把返回的视频流数据直接保存download下来。
秉着这个思路,加上努力查阅资料编写代码(不是,GPT真好用),最终终于成功把这个视频给下载了下来😀
四、参考代码:
import requests
import os
def downloaded_video(video_url,download_dir,video_name):
# 获取的视频链接
video_url = video_url
# 模拟浏览器请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Referer": "https://www.weibo.com/",
}
# 指定下载目录和文件名
video_name = video_name
download_dir = download_dir
file_path = os.path.join(download_dir,video_name)
try:
# 发送 HTTP GET 请求
response = requests.get(video_url, headers=headers, stream=True)
print(response)
# 检查请求是否成功
if response.status_code == 200 and 'video/mp4' in response.headers.get('Content-Type', ''):
# 创建下载目录(如果不存在)
os.makedirs(download_dir, exist_ok=True)
# 保存视频文件到本地
with open(file_path, "wb") as file:
for chunk in response.iter_content(chunk_size=8192):
if chunk: # 过滤掉保持连接的空块
file.write(chunk)
print("视频下载完成")
else:
print(f"请求失败,状态码:{response.status_code}")
except requests.exceptions.RequestException as e:
print(f"请求异常:{e}")五、使用步骤及注意事项:
- 在影刀添加python模块,复制上述代码在编码版上。
- 安装requests库。
- 调用此模块,传入以下三个参数:
- video_url:在网络源码里拿到的视频url,注意需带上前缀 https:
- download_dir:自定义视频保存目录
- video_name:自定义视频保存的名称,注意需带上后缀 .mp4
注意:
- 由于从网络源码中拿到的url是带有时间戳的,因此,获取url和调用模块下载视频的时间间隔不能过长,否则即会请求失败。
- 通过用时间戳计算,发现失效时间大概是86分钟后。
六、思考与延申:
按理来说,此方法的思路应该会适用于很多的视频下载场景(还没时间具体测试),这里只是做一个抛砖引玉,感兴趣的朋友们也可自行测试~
收藏7全部评论(1)
最新
发布评论
评论




